 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Architecture Search Algorithms for Quantum Autoencoders
Sep 18, 2025The design of quantum circuits is currently driven by the specific objectives of the quantum algorithm in question. This approach thus relies on a significant manual effort by the quantum algorithm designer to design an appropriate circuit for the task. However this approach cannot scale to more complex quantum algorithms in the future without exponentially increasing the circuit design effort and introducing unwanted inductive biases. Motivated by this observation, we propose to automate the process of cicuit design by drawing inspiration from Neural Architecture Search (NAS). In this work, we propose two Quantum-NAS algorithms that aim to find efficient circuits given a particular quantum task. We choose quantum data compression as our driver quantum task and demonstrate the performance of our algorithms by finding efficient autoencoder designs that outperform baselines on three different tasks - quantum data denoising, classical data compression and pure quantum data compression. Our results indicate that quantum NAS algorithms can significantly alleviate the manual effort while delivering performant quantum circuits for any given task.
QAdaPrune: Adaptive Parameter Pruning For Training Variational Quantum Circuits
Aug 23, 2024In the present noisy intermediate scale quantum computing era, there is a critical need to devise methods for the efficient implementation of gate-based variational quantum circuits. This ensures that a range of proposed applications can be deployed on real quantum hardware. The efficiency of quantum circuit is desired both in the number of trainable gates and the depth of the overall circuit. The major concern of barren plateaus has made this need for efficiency even more acute. The problem of efficient quantum circuit realization has been extensively studied in the literature to reduce gate complexity and circuit depth. Another important approach is to design a method to reduce the \emph{parameter complexity} in a variational quantum circuit. Existing methods include hyperparameter-based parameter pruning which introduces an additional challenge of finding the best hyperparameters for different applications. In this paper, we present \emph{QAdaPrune} - an adaptive parameter pruning algorithm that automatically determines the threshold and then intelligently prunes the redundant and non-performing parameters. We show that the resulting sparse parameter sets yield quantum circuits that perform comparably to the unpruned quantum circuits and in some cases may enhance trainability of the circuits even if the original quantum circuit gets stuck in a barren plateau.\\ \noindent{\bf Reproducibility}: The source code and data are available at \url{https://github.com/aicaffeinelife/QAdaPrune.git}
QArchSearch: A Scalable Quantum Architecture Search Package
Oct 11, 2023



The current era of quantum computing has yielded several algorithms that promise high computational efficiency. While the algorithms are sound in theory and can provide potentially exponential speedup, there is little guidance on how to design proper quantum circuits to realize the appropriate unitary transformation to be applied to the input quantum state. In this paper, we present \texttt{QArchSearch}, an AI based quantum architecture search package with the \texttt{QTensor} library as a backend that provides a principled and automated approach to finding the best model given a task and input quantum state. We show that the search package is able to efficiently scale the search to large quantum circuits and enables the exploration of more complex models for different quantum applications. \texttt{QArchSearch} runs at scale and high efficiency on high-performance computing systems using a two-level parallelization scheme on both CPUs and GPUs, which has been demonstrated on the Polaris supercomputer.
Learning To Optimize Quantum Neural Network Without Gradients
Apr 15, 2023Quantum Machine Learning is an emerging sub-field in machine learning where one of the goals is to perform pattern recognition tasks by encoding data into quantum states. This extension from classical to quantum domain has been made possible due to the development of hybrid quantum-classical algorithms that allow a parameterized quantum circuit to be optimized using gradient based algorithms that run on a classical computer. The similarities in training of these hybrid algorithms and classical neural networks has further led to the development of Quantum Neural Networks (QNNs). However, in the current training regime for QNNs, the gradients w.r.t objective function have to be computed on the quantum device. This computation is highly non-scalable and is affected by hardware and sampling noise present in the current generation of quantum hardware. In this paper, we propose a training algorithm that does not rely on gradient information. Specifically, we introduce a novel meta-optimization algorithm that trains a \emph{meta-optimizer} network to output parameters for the quantum circuit such that the objective function is minimized. We empirically and theoretically show that we achieve a better quality minima in fewer circuit evaluations than existing gradient based algorithms on different datasets.
BEINIT: Avoiding Barren Plateaus in Variational Quantum Algorithms
Apr 28, 2022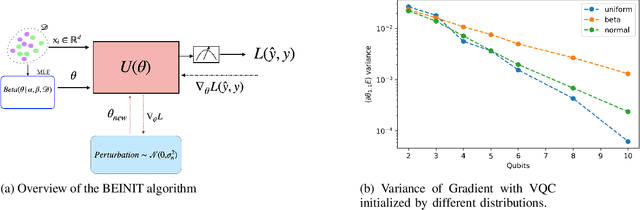
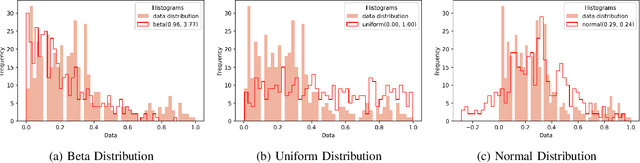
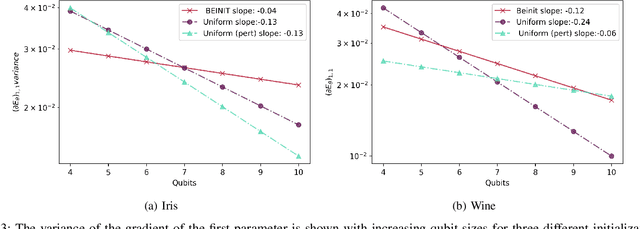
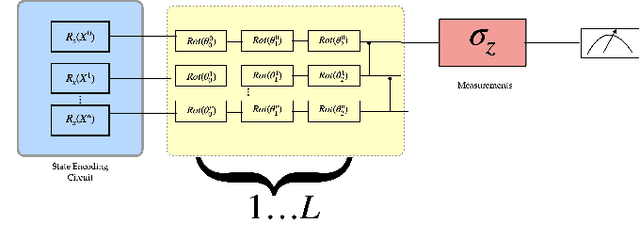
Barren plateaus are a notorious problem in the optimization of variational quantum algorithms and pose a critical obstacle in the quest for more efficient quantum machine learning algorithms. Many potential reasons for barren plateaus have been identified but few solutions have been proposed to avoid them in practice. Existing solutions are mainly focused on the initialization of unitary gate parameters without taking into account the changes induced by input data. In this paper, we propose an alternative strategy which initializes the parameters of a unitary gate by drawing from a beta distribution. The hyperparameters of the beta distribution are estimated from the data. To further prevent barren plateau during training we add a novel perturbation at every gradient descent step. Taking these ideas together, we empirically show that our proposed framework significantly reduces the possibility of a complex quantum neural network getting stuck in a barren plateau.
FAIRLEARN:Configurable and Interpretable Algorithmic Fairness
Nov 17, 2021
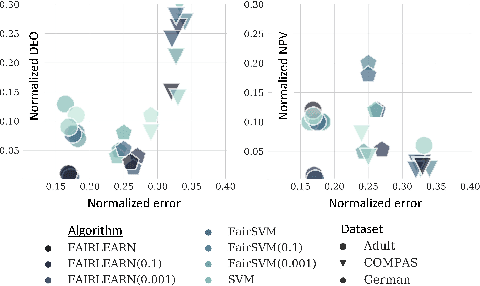
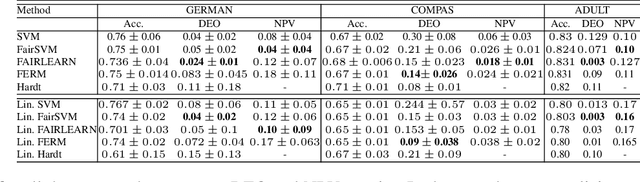
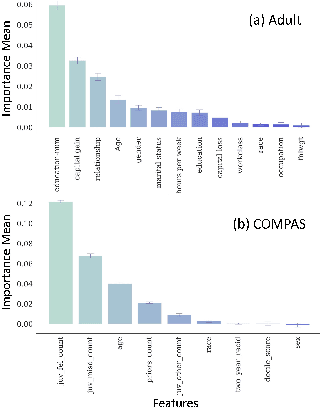
The rapid growth of data in the recent years has led to the development of complex learning algorithms that are often used to make decisions in real world. While the positive impact of the algorithms has been tremendous, there is a need to mitigate any bias arising from either training samples or implicit assumptions made about the data samples. This need becomes critical when algorithms are used in automated decision making systems that can hugely impact people's lives. Many approaches have been proposed to make learning algorithms fair by detecting and mitigating bias in different stages of optimization. However, due to a lack of a universal definition of fairness, these algorithms optimize for a particular interpretation of fairness which makes them limited for real world use. Moreover, an underlying assumption that is common to all algorithms is the apparent equivalence of achieving fairness and removing bias. In other words, there is no user defined criteria that can be incorporated into the optimization procedure for producing a fair algorithm. Motivated by these shortcomings of existing methods, we propose the FAIRLEARN procedure that produces a fair algorithm by incorporating user constraints into the optimization procedure. Furthermore, we make the process interpretable by estimating the most predictive features from data. We demonstrate the efficacy of our approach on several real world datasets using different fairness criteria.
Coping with Mistreatment in Fair Algorithms
Feb 22, 2021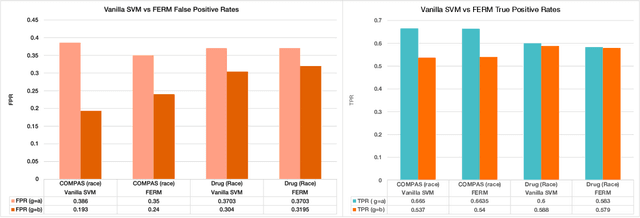
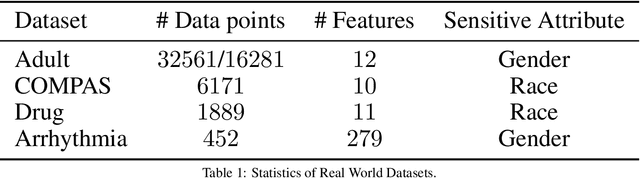

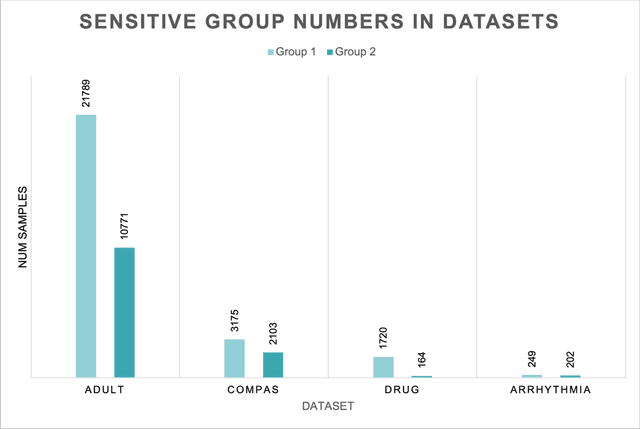
Machine learning actively impacts our everyday life in almost all endeavors and domains such as healthcare, finance, and energy. As our dependence on the machine learning increases, it is inevitable that these algorithms will be used to make decisions that will have a direct impact on the society spanning all resolutions from personal choices to world-wide policies. Hence, it is crucial to ensure that (un)intentional bias does not affect the machine learning algorithms especially when they are required to take decisions that may have unintended consequences. Algorithmic fairness techniques have found traction in the machine learning community and many methods and metrics have been proposed to ensure and evaluate fairness in algorithms and data collection. In this paper, we study the algorithmic fairness in a supervised learning setting and examine the effect of optimizing a classifier for the Equal Opportunity metric. We demonstrate that such a classifier has an increased false positive rate across sensitive groups and propose a conceptually simple method to mitigate this bias. We rigorously analyze the proposed method and evaluate it on several real world datasets demonstrating its efficacy.
Accelerating COVID-19 research with graph mining and transformer-based learning
Feb 10, 2021In 2020, the White House released the, "Call to Action to the Tech Community on New Machine Readable COVID-19 Dataset," wherein artificial intelligence experts are asked to collect data and develop text mining techniques that can help the science community answer high-priority scientific questions related to COVID-19. The Allen Institute for AI and collaborators announced the availability of a rapidly growing open dataset of publications, the COVID-19 Open Research Dataset (CORD-19). As the pace of research accelerates, biomedical scientists struggle to stay current. To expedite their investigations, scientists leverage hypothesis generation systems, which can automatically inspect published papers to discover novel implicit connections. We present an automated general purpose hypothesis generation systems AGATHA-C and AGATHA-GP for COVID-19 research. The systems are based on graph-mining and the transformer model. The systems are massively validated using retrospective information rediscovery and proactive analysis involving human-in-the-loop expert analysis. Both systems achieve high-quality predictions across domains (in some domains up to 0.97% ROC AUC) in fast computational time and are released to the broad scientific community to accelerate biomedical research. In addition, by performing the domain expert curated study, we show that the systems are able to discover on-going research findings such as the relationship between COVID-19 and oxytocin hormone.