 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEINIT: Avoiding Barren Plateaus in Variational Quantum Algorithms
Paper and Code
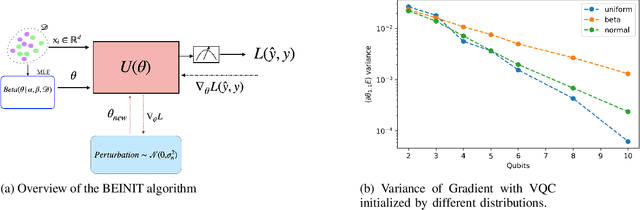
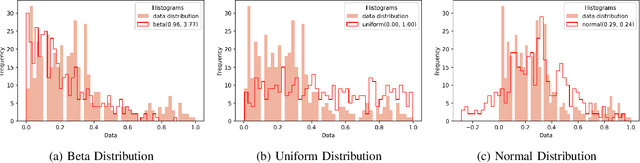
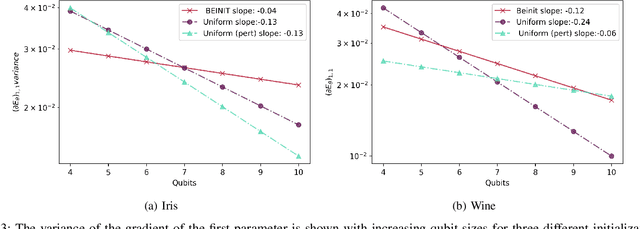
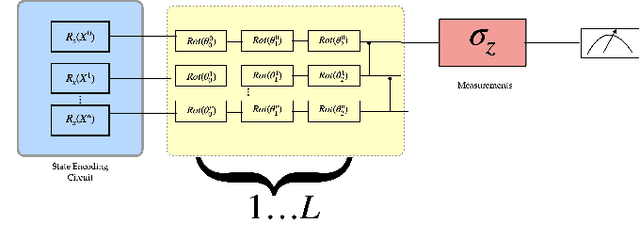
Barren plateaus are a notorious problem in the optimization of variational quantum algorithms and pose a critical obstacle in the quest for more efficient quantum machine learning algorithms. Many potential reasons for barren plateaus have been identified but few solutions have been proposed to avoid them in practice. Existing solutions are mainly focused on the initialization of unitary gate parameters without taking into account the changes induced by input data. In this paper, we propose an alternative strategy which initializes the parameters of a unitary gate by drawing from a beta distribution. The hyperparameters of the beta distribution are estimated from the data. To further prevent barren plateau during training we add a novel perturbation at every gradient descent step. Taking these ideas together, we empirically show that our proposed framework significantly reduces the possibility of a complex quantum neural network getting stuck in a barren plateau.