 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTC-DID: CTC-Based Arabic dialect identification for streaming applications
Jan 18, 2026This paper proposes a Dialect Identification (DID) approach inspired by the Connectionist Temporal Classification (CTC) loss function as used in Automatic Speech Recognition (ASR). CTC-DID frames the dialect identification task as a limited-vocabulary ASR system, where dialect tags are treated as a sequence of labels for a given utterance. For training, the repetition of dialect tags in transcriptions is estimated either using a proposed Language-Agnostic Heuristic (LAH) approach or a pre-trained ASR model. The method is evaluated on the low-resource Arabic Dialect Identification (ADI) task, with experimental results demonstrating that an SSL-based CTC-DID model, trained on a limited dataset, outperforms both fine-tuned Whisper and ECAPA-TDNN models. Notably, CTC-DID also surpasses these models in zero-shot evaluation on the Casablanca dataset. The proposed approach is found to be more robust to shorter utterances and is shown to be easily adaptable for streaming, real-time applications, with minimal performance degradation.
Dual-Encoder Transformer-Based Multimodal Learning for Ischemic Stroke Lesion Segmentation Using Diffusion MRI
Dec 23, 2025Accurate segmentation of ischemic stroke lesions from diffusion magnetic resonance imaging (MRI) is essential for clinical decision-making and outcome assessment. Diffusion-Weighted Imaging (DWI) and Apparent Diffusion Coefficient (ADC) scans provide complementary information on acute and sub-acute ischemic changes; however, automated lesion delineation remains challenging due to variability in lesion appearance. In this work, we study ischemic stroke lesion segmentation using multimodal diffusion MRI from the ISLES 2022 dataset. Several state-of-the-art convolutional and transformer-based architectures, including U-Net variants, Swin-UNet, and TransUNet, are benchmarked. Based on performance, a dual-encoder TransUNet architecture is proposed to learn modality-specific representations from DWI and ADC inputs. To incorporate spatial context, adjacent slice information is integrated using a three-slice input configuration. All models are trained under a unified framework and evaluated using the Dice Similarity Coefficient (DSC). Results show that transformer-based models outperform convolutional baselines, and the proposed dual-encoder TransUNet achieves the best performance, reaching a Dice score of 85.4% on the test set. The proposed framework offers a robust solution for automated ischemic stroke lesion segmentation from diffusion MRI.
Anatomy-Guided Representation Learning Using a Transformer-Based Network for Thyroid Nodule Segmentation in Ultrasound Images
Dec 14, 2025Accurate thyroid nodule segmentation in ultrasound images is critical for diagnosis and treatment planning. However, ambiguous boundaries between nodules and surrounding tissues, size variations, and the scarcity of annotated ultrasound data pose significant challenges for automated segmentation. Existing deep learning models struggle to incorporate contextual information from the thyroid gland and generalize effectively across diverse cases. To address these challenges, we propose SSMT-Net, a Semi-Supervised Multi-Task Transformer-based Network that leverages unlabeled data to enhance Transformer-centric encoder feature extraction capability in an initial unsupervised phase. In the supervised phase, the model jointly optimizes nodule segmentation, gland segmentation, and nodule size estimation, integrating both local and global contextual features. Extensive evaluations on the TN3K and DDTI datasets demonstrate that SSMT-Net outperforms state-of-the-art methods, with higher accuracy and robustness, indicating its potential for real-world clinical applications.
Adversarial Attacks on Audio Deepfake Detection: A Benchmark and Comparative Study
Sep 08, 2025The widespread use of generative AI has shown remarkable success in producing highly realistic deepfakes, posing a serious threat to various voice biometric applications, including speaker verification, voice biometrics, audio conferencing, and criminal investigations. To counteract this, several state-of-the-art (SoTA) audio deepfake detection (ADD) methods have been proposed to identify generative AI signatures to distinguish between real and deepfake audio. However, the effectiveness of these methods is severely undermined by anti-forensic (AF) attacks that conceal generative signatures. These AF attacks span a wide range of techniques, including statistical modifications (e.g., pitch shifting, filtering, noise addition, and quantization) and optimization-based attacks (e.g., FGSM, PGD, C \& W, and DeepFool). In this paper, we investigate the SoTA ADD methods and provide a comparative analysis to highlight their effectiveness in exposing deepfake signatures, as well as their vulnerabilities under adversarial conditions. We conducted an extensive evaluation of ADD methods on five deepfake benchmark datasets using two categories: raw and spectrogram-based approaches. This comparative analysis enables a deeper understanding of the strengths and limitations of SoTA ADD methods against diverse AF attacks. It does not only highlight vulnerabilities of ADD methods, but also informs the design of more robust and generalized detectors for real-world voice biometrics. It will further guide future research in developing adaptive defense strategies that can effectively counter evolving AF techniques.
SHIELD: A Secure and Highly Enhanced Integrated Learning for Robust Deepfake Detection against Adversarial Attacks
Jul 17, 2025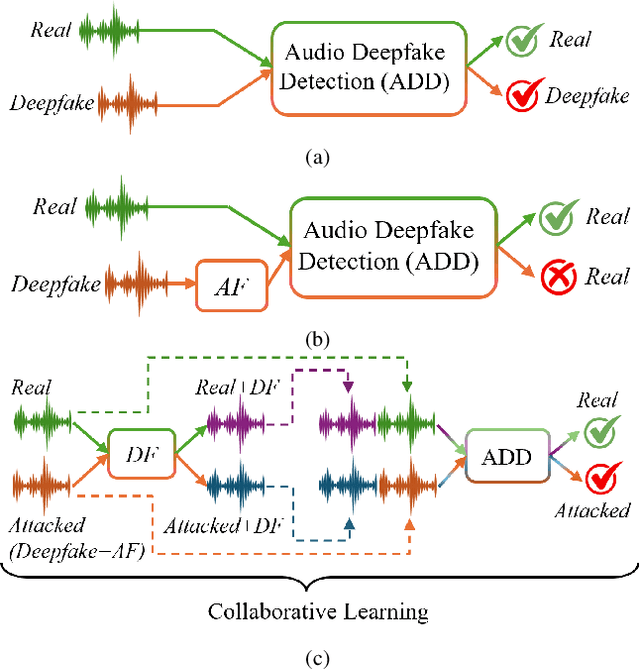
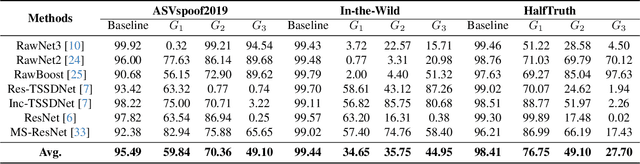
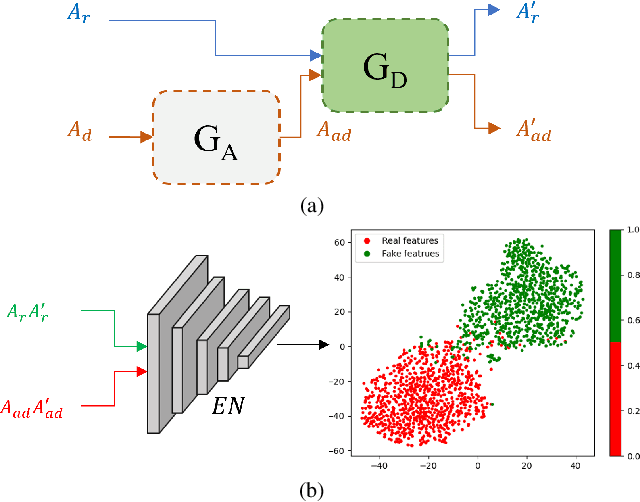
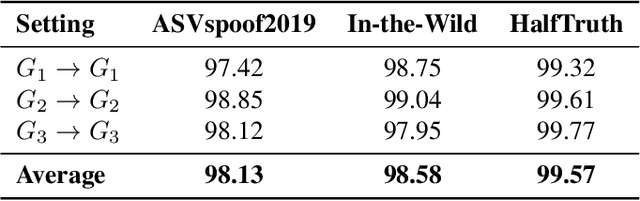
Audio plays a crucial role in applications like speaker verification, voice-enabled smart devices, and audio conferencing. However, audio manipulations, such as deepfakes, pose significant risks by enabling the spread of misinformation. Our empirical analysis reveals that existing methods for detecting deepfake audio are often vulnerable to anti-forensic (AF) attacks, particularly those attacked using generative adversarial networks. In this article, we propose a novel collaborative learning method called SHIELD to defend against generative AF attacks. To expose AF signatures, we integrate an auxiliary generative model, called the defense (DF) generative model, which facilitates collaborative learning by combining input and output. Furthermore, we design a triplet model to capture correlations for real and AF attacked audios with real-generated and attacked-generated audios using auxiliary generative models. The proposed SHIELD strengthens the defense against generative AF attacks and achieves robust performance across various generative models. The proposed AF significantly reduces the average detection accuracy from 95.49% to 59.77% for ASVspoof2019, from 99.44% to 38.45% for In-the-Wild, and from 98.41% to 51.18% for HalfTruth for three different generative models. The proposed SHIELD mechanism is robust against AF attacks and achieves an average accuracy of 98.13%, 98.58%, and 99.57% in match, and 98.78%, 98.62%, and 98.85% in mismatch settings for the ASVspoof2019, In-the-Wild, and HalfTruth datasets, respectively.
A Lightweight and Interpretable Deepfakes Detection Framework
Jan 21, 2025


The recent realistic creation and dissemination of so-called deepfakes poses a serious threat to social life, civil rest, and law. Celebrity defaming, election manipulation, and deepfakes as evidence in court of law are few potential consequences of deepfakes. The availability of open source trained models based on modern frameworks such as PyTorch or TensorFlow, video manipulations Apps such as FaceApp and REFACE, and economical computing infrastructure has easen the creation of deepfakes. Most of the existing detectors focus on detecting either face-swap, lip-sync, or puppet master deepfakes, but a unified framework to detect all three types of deepfakes is hardly explored. This paper presents a unified framework that exploits the power of proposed feature fusion of hybrid facial landmarks and our novel heart rate features for detection of all types of deepfakes. We propose novel heart rate features and fused them with the facial landmark features to better extract the facial artifacts of fake videos and natural variations available in the original videos. We used these features to train a light-weight XGBoost to classify between the deepfake and bonafide videos. We evaluated the performance of our framework on the world leaders dataset (WLDR) that contains all types of deepfakes. Experimental results illustrate that the proposed framework offers superior detection performance over the comparative deepfakes detection methods. Performance comparison of our framework against the LSTM-FCN, a candidate of deep learning model, shows that proposed model achieves similar results, however, it is more interpretable.
Transferable Adversarial Attacks on Audio Deepfake Detection
Jan 21, 2025



Audio deepfakes pose significant threats, including impersonation, fraud, and reputation damage. To address these risks, audio deepfake detection (ADD) techniques have been developed, demonstrating success on benchmarks like ASVspoof2019. However, their resilience against transferable adversarial attacks remains largely unexplored. In this paper, we introduce a transferable GAN-based adversarial attack framework to evaluate the effectiveness of state-of-the-art (SOTA) ADD systems. By leveraging an ensemble of surrogate ADD models and a discriminator, the proposed approach generates transferable adversarial attacks that better reflect real-world scenarios. Unlike previous methods, the proposed framework incorporates a self-supervised audio model to ensure transcription and perceptual integrity, resulting in high-quality adversarial attacks. Experimental results on benchmark dataset reveal that SOTA ADD systems exhibit significant vulnerabilities, with accuracies dropping from 98% to 26%, 92% to 54%, and 94% to 84% in white-box, gray-box, and black-box scenarios, respectively. When tested in other data sets, performance drops of 91% to 46%, and 94% to 67% were observed against the In-the-Wild and WaveFake data sets, respectively. These results highlight the significant vulnerabilities of existing ADD systems and emphasize the need to enhance their robustness against advanced adversarial threats to ensure security and reliability.
Securing Social Media Against Deepfakes using Identity, Behavioral, and Geometric Signatures
Dec 07, 2024



Trust in social media is a growing concern due to its ability to influence significant societal changes. However, this space is increasingly compromised by various types of deepfake multimedia, which undermine the authenticity of shared content. Although substantial efforts have been made to address the challenge of deepfake content, existing detection techniques face a major limitation in generalization: they tend to perform well only on specific types of deepfakes they were trained on.This dependency on recognizing specific deepfake artifacts makes current methods vulnerable when applied to unseen or varied deepfakes, thereby compromising their performance in real-world applications such as social media platforms. To address the generalizability of deepfake detection, there is a need for a holistic approach that can capture a broader range of facial attributes and manipulations beyond isolated artifacts. To address this, we propose a novel deepfake detection framework featuring an effective feature descriptor that integrates Deep identity, Behavioral, and Geometric (DBaG) signatures, along with a classifier named DBaGNet. Specifically, the DBaGNet classifier utilizes the extracted DBaG signatures, leveraging a triplet loss objective to enhance generalized representation learning for improved classification. Specifically, the DBaGNet classifier utilizes the extracted DBaG signatures and applies a triplet loss objective to enhance generalized representation learning for improved classification. To test the effectiveness and generalizability of our proposed approach, we conduct extensive experiments using six benchmark deepfake datasets: WLDR, CelebDF, DFDC, FaceForensics++, DFD, and NVFAIR. Specifically, to ensure the effectiveness of our approach, we perform cross-dataset evaluations, and the results demonstrate significant performance gains over several state-of-the-art methods.
Progressive unsupervised domain adaptation for ASR using ensemble models and multi-stage training
Feb 07, 2024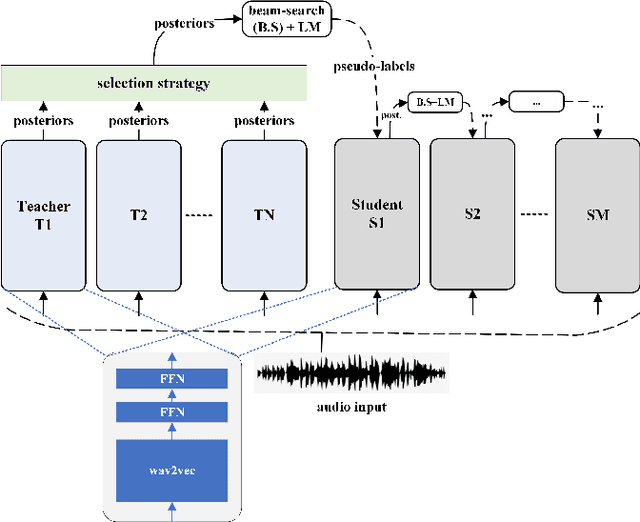
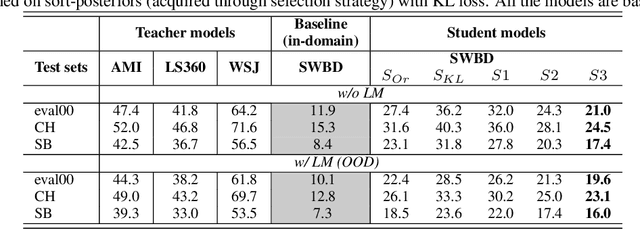
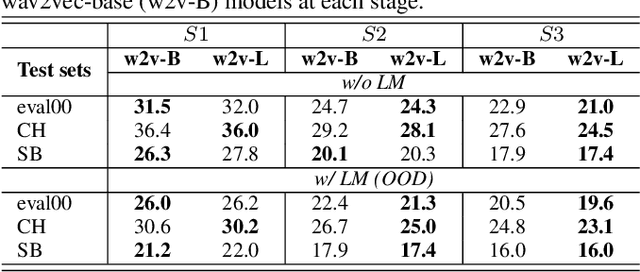
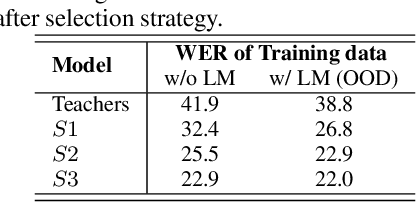
In Automatic Speech Recognition (ASR), teacher-student (T/S) training has shown to perform well for domain adaptation with small amount of training data. However, adaption without ground-truth labels is still challenging. A previous study has shown the effectiveness of using ensemble teacher models in T/S training for unsupervised domain adaptation (UDA) but its performance still lags behind compared to the model trained on in-domain data. This paper proposes a method to yield better UDA by training multi-stage students with ensemble teacher models. Initially, multiple teacher models are trained on labelled data from read and meeting domains. These teachers are used to train a student model on unlabelled out-of-domain telephone speech data. To improve the adaptation, subsequent student models are trained sequentially considering previously trained model as their teacher. Experiments are conducted with three teachers trained on AMI, WSJ and LibriSpeech and three stages of students on SwitchBoard data. Results shown on eval00 test set show significant WER improvement with multi-stage training with an absolute gain of 9.8%, 7.7% and 3.3% at each stage.
MUST: A Multilingual Student-Teacher Learning approach for low-resource speech recognition
Oct 29, 2023Student-teacher learning or knowledge distillation (KD) has been previously used to address data scarcity issue for training of speech recognition (ASR) systems. However, a limitation of KD training is that the student model classes must be a proper or improper subset of the teacher model classes. It prevents distillation from even acoustically similar languages if the character sets are not same. In this work, the aforementioned limitation is addressed by proposing a MUltilingual Student-Teacher (MUST) learning which exploits a posteriors mapping approach. A pre-trained mapping model is used to map posteriors from a teacher language to the student language ASR. These mapped posteriors are used as soft labels for KD learning. Various teacher ensemble schemes are experimented to train an ASR model for low-resource languages. A model trained with MUST learning reduces relative character error rate (CER) up to 9.5% in comparison with a baseline monolingual ASR.