 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgressive unsupervised domain adaptation for ASR using ensemble models and multi-stage training
Paper and Code
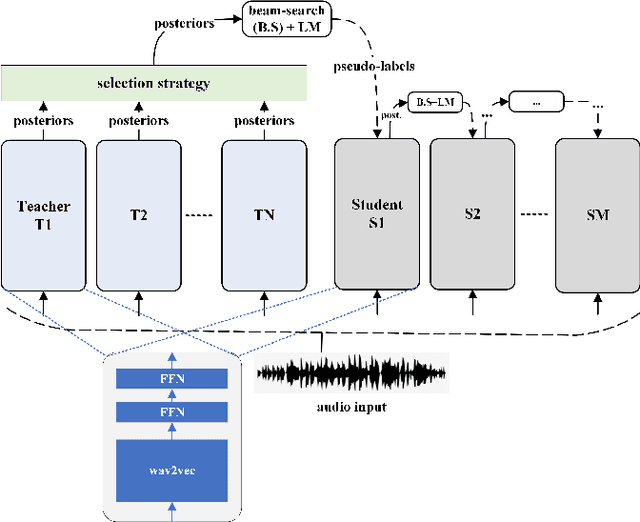
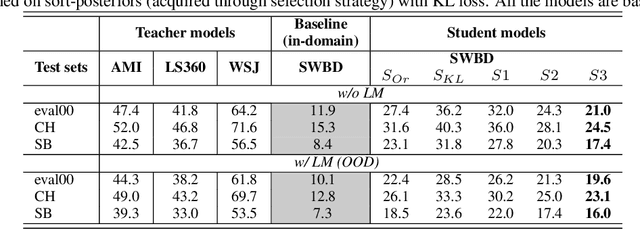
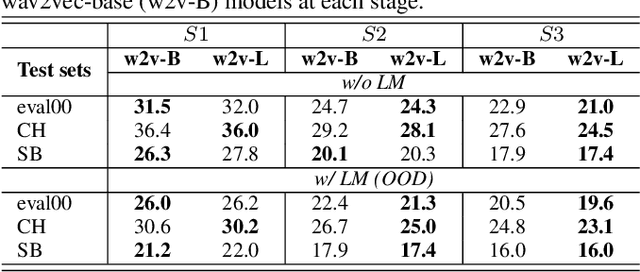
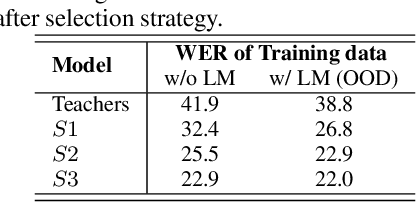
In Automatic Speech Recognition (ASR), teacher-student (T/S) training has shown to perform well for domain adaptation with small amount of training data. However, adaption without ground-truth labels is still challenging. A previous study has shown the effectiveness of using ensemble teacher models in T/S training for unsupervised domain adaptation (UDA) but its performance still lags behind compared to the model trained on in-domain data. This paper proposes a method to yield better UDA by training multi-stage students with ensemble teacher models. Initially, multiple teacher models are trained on labelled data from read and meeting domains. These teachers are used to train a student model on unlabelled out-of-domain telephone speech data. To improve the adaptation, subsequent student models are trained sequentially considering previously trained model as their teacher. Experiments are conducted with three teachers trained on AMI, WSJ and LibriSpeech and three stages of students on SwitchBoard data. Results shown on eval00 test set show significant WER improvement with multi-stage training with an absolute gain of 9.8%, 7.7% and 3.3% at each stage.