 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstruction-Tuned LLMs for Parsing and Mining Unstructured Logs on Leadership HPC Systems
Apr 06, 2026Leadership-class HPC systems generate massive volumes of heterogeneous, largely unstructured system logs. Because these logs originate from diverse software, hardware, and runtime layers, they exhibit inconsistent formats, making structure extraction and pattern discovery extremely challenging. Therefore, robust log parsing and mining is critical to transform this raw telemetry into actionable insights that reveal operational patterns, diagnose anomalies, and enable reliable, efficient, and scalable system analysis. Recent advances in large language models (LLMs) offer a promising new direction for automated log understanding in leadership-class HPC environments. To capitalize on this opportunity, we present a domain-adapted, instruction-following, LLM-driven framework that leverages chain-of-thought (CoT) reasoning to parse and structure HPC logs with high fidelity. Our approach combines domain-specific log-template data with instruction-tuned examples to fine-tune an 8B-parameter LLaMA model tailored for HPC log analysis. We develop a hybrid fine-tuning methodology that adapts a general-purpose LLM to domain-specific log data, enabling privacy-preserving, locally deployable, fast, and energy-efficient log-mining approach. We conduct experiments on a diverse set of log datasets from the LogHub repository. The evaluation confirms that our approach achieves parsing accuracy on par with significantly larger models, such as LLaMA 70B and Anthropic's Claude. We further validate the practical utility of our fine-tuned LLM model by parsing over 600 million production logs from the Frontier supercomputer over a four-week window, uncovering critical patterns in temporal dynamics, node-level anomalies, and workload-error log correlations.
TRACE: Training-Free Partial Audio Deepfake Detection via Embedding Trajectory Analysis of Speech Foundation Models
Apr 01, 2026Partial audio deepfakes, where synthesized segments are spliced into genuine recordings, are particularly deceptive because most of the audio remains authentic. Existing detectors are supervised: they require frame-level annotations, overfit to specific synthesis pipelines, and must be retrained as new generative models emerge. We argue that this supervision is unnecessary. We hypothesize that speech foundation models implicitly encode a forensic signal: genuine speech forms smooth, slowly varying embedding trajectories, while splice boundaries introduce abrupt disruptions in frame-level transitions. Building on this, we propose TRACE (Training-free Representation-based Audio Countermeasure via Embedding dynamics), a training-free framework that detects partial audio deepfakes by analyzing the first-order dynamics of frozen speech foundation model representations without any training, labeled data, or architectural modification. We evaluate TRACE on four benchmarks that span two languages using six speech foundation models. In PartialSpoof, TRACE achieves 8.08% EER, competitive with fine-tuned supervised baselines. In LlamaPartialSpoof, the most challenging benchmark featuring LLM-driven commercial synthesis, TRACE surpasses a supervised baseline outright (24.12% vs. 24.49% EER) without any target-domain data. These results show that temporal dynamics in speech foundation models provide an effective, generalize signal for training-free audio forensics.
Adversarial Attacks on Audio Deepfake Detection: A Benchmark and Comparative Study
Sep 08, 2025The widespread use of generative AI has shown remarkable success in producing highly realistic deepfakes, posing a serious threat to various voice biometric applications, including speaker verification, voice biometrics, audio conferencing, and criminal investigations. To counteract this, several state-of-the-art (SoTA) audio deepfake detection (ADD) methods have been proposed to identify generative AI signatures to distinguish between real and deepfake audio. However, the effectiveness of these methods is severely undermined by anti-forensic (AF) attacks that conceal generative signatures. These AF attacks span a wide range of techniques, including statistical modifications (e.g., pitch shifting, filtering, noise addition, and quantization) and optimization-based attacks (e.g., FGSM, PGD, C \& W, and DeepFool). In this paper, we investigate the SoTA ADD methods and provide a comparative analysis to highlight their effectiveness in exposing deepfake signatures, as well as their vulnerabilities under adversarial conditions. We conducted an extensive evaluation of ADD methods on five deepfake benchmark datasets using two categories: raw and spectrogram-based approaches. This comparative analysis enables a deeper understanding of the strengths and limitations of SoTA ADD methods against diverse AF attacks. It does not only highlight vulnerabilities of ADD methods, but also informs the design of more robust and generalized detectors for real-world voice biometrics. It will further guide future research in developing adaptive defense strategies that can effectively counter evolving AF techniques.
SHIELD: A Secure and Highly Enhanced Integrated Learning for Robust Deepfake Detection against Adversarial Attacks
Jul 17, 2025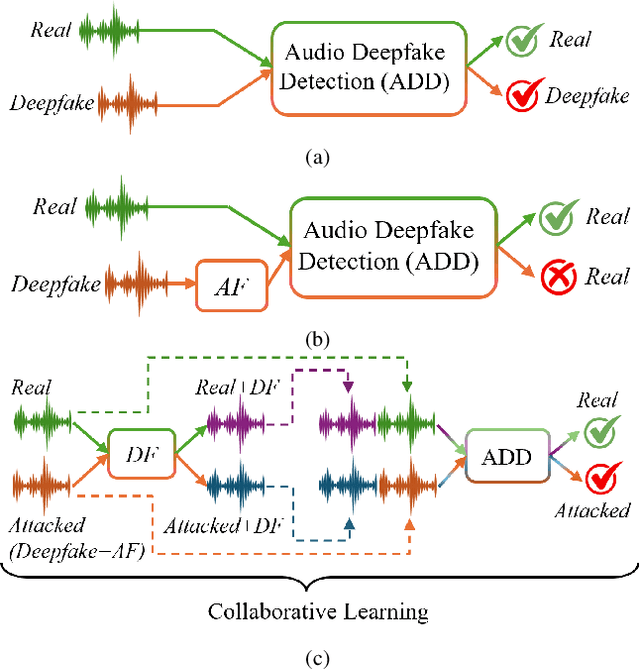
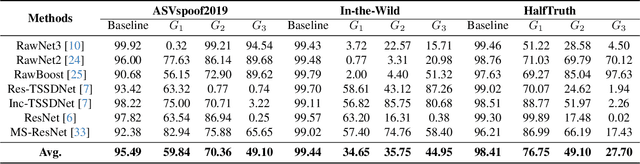
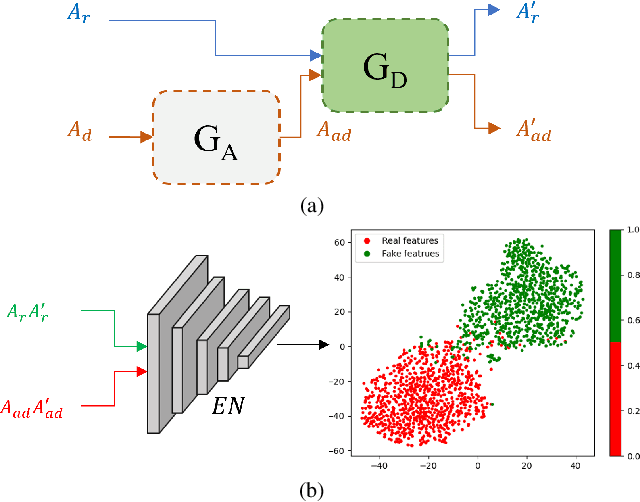
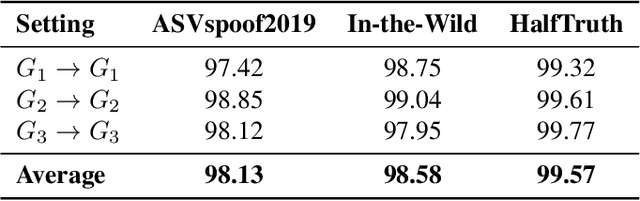
Audio plays a crucial role in applications like speaker verification, voice-enabled smart devices, and audio conferencing. However, audio manipulations, such as deepfakes, pose significant risks by enabling the spread of misinformation. Our empirical analysis reveals that existing methods for detecting deepfake audio are often vulnerable to anti-forensic (AF) attacks, particularly those attacked using generative adversarial networks. In this article, we propose a novel collaborative learning method called SHIELD to defend against generative AF attacks. To expose AF signatures, we integrate an auxiliary generative model, called the defense (DF) generative model, which facilitates collaborative learning by combining input and output. Furthermore, we design a triplet model to capture correlations for real and AF attacked audios with real-generated and attacked-generated audios using auxiliary generative models. The proposed SHIELD strengthens the defense against generative AF attacks and achieves robust performance across various generative models. The proposed AF significantly reduces the average detection accuracy from 95.49% to 59.77% for ASVspoof2019, from 99.44% to 38.45% for In-the-Wild, and from 98.41% to 51.18% for HalfTruth for three different generative models. The proposed SHIELD mechanism is robust against AF attacks and achieves an average accuracy of 98.13%, 98.58%, and 99.57% in match, and 98.78%, 98.62%, and 98.85% in mismatch settings for the ASVspoof2019, In-the-Wild, and HalfTruth datasets, respectively.
Transferable Adversarial Attacks on Audio Deepfake Detection
Jan 21, 2025



Audio deepfakes pose significant threats, including impersonation, fraud, and reputation damage. To address these risks, audio deepfake detection (ADD) techniques have been developed, demonstrating success on benchmarks like ASVspoof2019. However, their resilience against transferable adversarial attacks remains largely unexplored. In this paper, we introduce a transferable GAN-based adversarial attack framework to evaluate the effectiveness of state-of-the-art (SOTA) ADD systems. By leveraging an ensemble of surrogate ADD models and a discriminator, the proposed approach generates transferable adversarial attacks that better reflect real-world scenarios. Unlike previous methods, the proposed framework incorporates a self-supervised audio model to ensure transcription and perceptual integrity, resulting in high-quality adversarial attacks. Experimental results on benchmark dataset reveal that SOTA ADD systems exhibit significant vulnerabilities, with accuracies dropping from 98% to 26%, 92% to 54%, and 94% to 84% in white-box, gray-box, and black-box scenarios, respectively. When tested in other data sets, performance drops of 91% to 46%, and 94% to 67% were observed against the In-the-Wild and WaveFake data sets, respectively. These results highlight the significant vulnerabilities of existing ADD systems and emphasize the need to enhance their robustness against advanced adversarial threats to ensure security and reliability.
Securing Social Media Against Deepfakes using Identity, Behavioral, and Geometric Signatures
Dec 07, 2024



Trust in social media is a growing concern due to its ability to influence significant societal changes. However, this space is increasingly compromised by various types of deepfake multimedia, which undermine the authenticity of shared content. Although substantial efforts have been made to address the challenge of deepfake content, existing detection techniques face a major limitation in generalization: they tend to perform well only on specific types of deepfakes they were trained on.This dependency on recognizing specific deepfake artifacts makes current methods vulnerable when applied to unseen or varied deepfakes, thereby compromising their performance in real-world applications such as social media platforms. To address the generalizability of deepfake detection, there is a need for a holistic approach that can capture a broader range of facial attributes and manipulations beyond isolated artifacts. To address this, we propose a novel deepfake detection framework featuring an effective feature descriptor that integrates Deep identity, Behavioral, and Geometric (DBaG) signatures, along with a classifier named DBaGNet. Specifically, the DBaGNet classifier utilizes the extracted DBaG signatures, leveraging a triplet loss objective to enhance generalized representation learning for improved classification. Specifically, the DBaGNet classifier utilizes the extracted DBaG signatures and applies a triplet loss objective to enhance generalized representation learning for improved classification. To test the effectiveness and generalizability of our proposed approach, we conduct extensive experiments using six benchmark deepfake datasets: WLDR, CelebDF, DFDC, FaceForensics++, DFD, and NVFAIR. Specifically, to ensure the effectiveness of our approach, we perform cross-dataset evaluations, and the results demonstrate significant performance gains over several state-of-the-art methods.
Parallel Stacked Aggregated Network for Voice Authentication in IoT-Enabled Smart Devices
Nov 29, 2024



Voice authentication on IoT-enabled smart devices has gained prominence in recent years due to increasing concerns over user privacy and security. The current authentication systems are vulnerable to different voice-spoofing attacks (e.g., replay, voice cloning, and audio deepfakes) that mimic legitimate voices to deceive authentication systems and enable fraudulent activities (e.g., impersonation, unauthorized access, financial fraud, etc.). Existing solutions are often designed to tackle a single type of attack, leading to compromised performance against unseen attacks. On the other hand, existing unified voice anti-spoofing solutions, not designed specifically for IoT, possess complex architectures and thus cannot be deployed on IoT-enabled smart devices. Additionally, most of these unified solutions exhibit significant performance issues, including higher equal error rates or lower accuracy for specific attacks. To overcome these issues, we present the parallel stacked aggregation network (PSA-Net), a lightweight framework designed as an anti-spoofing defense system for voice-controlled smart IoT devices. The PSA-Net processes raw audios directly and eliminates the need for dataset-dependent handcrafted features or pre-computed spectrograms. Furthermore, PSA-Net employs a split-transform-aggregate approach, which involves the segmentation of utterances, the extraction of intrinsic differentiable embeddings through convolutions, and the aggregation of them to distinguish legitimate from spoofed audios. In contrast to existing deep Resnet-oriented solutions, we incorporate cardinality as an additional dimension in our network, which enhances the PSA-Net ability to generalize across diverse attacks. The results show that the PSA-Net achieves more consistent performance for different attacks that exist in current anti-spoofing solutions.
Securing Voice Biometrics: One-Shot Learning Approach for Audio Deepfake Detection
Oct 05, 2023



The Automatic Speaker Verification (ASV) system is vulnerable to fraudulent activities using audio deepfakes, also known as logical-access voice spoofing attacks. These deepfakes pose a concerning threat to voice biometrics due to recent advancements in generative AI and speech synthesis technologies. While several deep learning models for speech synthesis detection have been developed, most of them show poor generalizability, especially when the attacks have different statistical distributions from the ones seen. Therefore, this paper presents Quick-SpoofNet, an approach for detecting both seen and unseen synthetic attacks in the ASV system using one-shot learning and metric learning techniques. By using the effective spectral feature set, the proposed method extracts compact and representative temporal embeddings from the voice samples and utilizes metric learning and triplet loss to assess the similarity index and distinguish different embeddings. The system effectively clusters similar speech embeddings, classifying bona fide speeches as the target class and identifying other clusters as spoofing attacks. The proposed system is evaluated using the ASVspoof 2019 logical access (LA) dataset and tested against unseen deepfake attacks from the ASVspoof 2021 dataset. Additionally, its generalization ability towards unseen bona fide speech is assessed using speech data from the VSDC dataset.
Bridging the Spoof Gap: A Unified Parallel Aggregation Network for Voice Presentation Attacks
Sep 19, 2023Automatic Speaker Verification (ASV) systems are increasingly used in voice bio-metrics for user authentication but are susceptible to logical and physical spoofing attacks, posing security risks. Existing research mainly tackles logical or physical attacks separately, leading to a gap in unified spoofing detection. Moreover, when existing systems attempt to handle both types of attacks, they often exhibit significant disparities in the Equal Error Rate (EER). To bridge this gap, we present a Parallel Stacked Aggregation Network that processes raw audio. Our approach employs a split-transform-aggregation technique, dividing utterances into convolved representations, applying transformations, and aggregating the results to identify logical (LA) and physical (PA) spoofing attacks. Evaluation of the ASVspoof-2019 and VSDC datasets shows the effectiveness of the proposed system. It outperforms state-of-the-art solutions, displaying reduced EER disparities and superior performance in detecting spoofing attacks. This highlights the proposed method's generalizability and superiority. In a world increasingly reliant on voice-based security, our unified spoofing detection system provides a robust defense against a spectrum of voice spoofing attacks, safeguarding ASVs and user data effectively.
Frame-to-Utterance Convergence: A Spectra-Temporal Approach for Unified Spoofing Detection
Sep 18, 2023Voice spoofing attacks pose a significant threat to automated speaker verification systems. Existing anti-spoofing methods often simulate specific attack types, such as synthetic or replay attacks. However, in real-world scenarios, the countermeasures are unaware of the generation schema of the attack, necessitating a unified solution. Current unified solutions struggle to detect spoofing artifacts, especially with recent spoofing mechanisms. For instance, the spoofing algorithms inject spectral or temporal anomalies, which are challenging to identify. To this end, we present a spectra-temporal fusion leveraging frame-level and utterance-level coefficients. We introduce a novel local spectral deviation coefficient (SDC) for frame-level inconsistencies and employ a bi-LSTM-based network for sequential temporal coefficients (STC), which capture utterance-level artifacts. Our spectra-temporal fusion strategy combines these coefficients, and an auto-encoder generates spectra-temporal deviated coefficients (STDC) to enhance robustness. Our proposed approach addresses multiple spoofing categories, including synthetic, replay, and partial deepfake attacks. Extensive evaluation on diverse datasets (ASVspoof2019, ASVspoof2021, VSDC, partial spoofs, and in-the-wild deepfakes) demonstrated its robustness for a wide range of voice applications.