 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVoice Spoofing Countermeasures: Taxonomy, State-of-the-art, experimental analysis of generalizability, open challenges, and the way forward
Oct 02, 2022



Malicious actors may seek to use different voice-spoofing attacks to fool ASV systems and even use them for spreading misinformation. Various countermeasures have been proposed to detect these spoofing attacks. Due to the extensive work done on spoofing detection in automated speaker verification (ASV) systems in the last 6-7 years, there is a need to classify the research and perform qualitative and quantitative comparisons on state-of-the-art countermeasures. Additionally, no existing survey paper has reviewed integrated solutions to voice spoofing evaluation and speaker verification, adversarial/antiforensics attacks on spoofing countermeasures, and ASV itself, or unified solutions to detect multiple attacks using a single model. Further, no work has been done to provide an apples-to-apples comparison of published countermeasures in order to assess their generalizability by evaluating them across corpora. In this work, we conduct a review of the literature on spoofing detection using hand-crafted features, deep learning, end-to-end, and universal spoofing countermeasure solutions to detect speech synthesis (SS), voice conversion (VC), and replay attacks. Additionally, we also review integrated solutions to voice spoofing evaluation and speaker verification, adversarial and anti-forensics attacks on voice countermeasures, and ASV. The limitations and challenges of the existing spoofing countermeasures are also presented. We report the performance of these countermeasures on several datasets and evaluate them across corpora. For the experiments, we employ the ASVspoof2019 and VSDC datasets along with GMM, SVM, CNN, and CNN-GRU classifiers. (For reproduceability of the results, the code of the test bed can be found in our GitHub Repository.
CFGs-2-NLU: Sequence-to-Sequence Learning for Mapping Utterances to Semantics and Pragmatics
Jul 22, 2016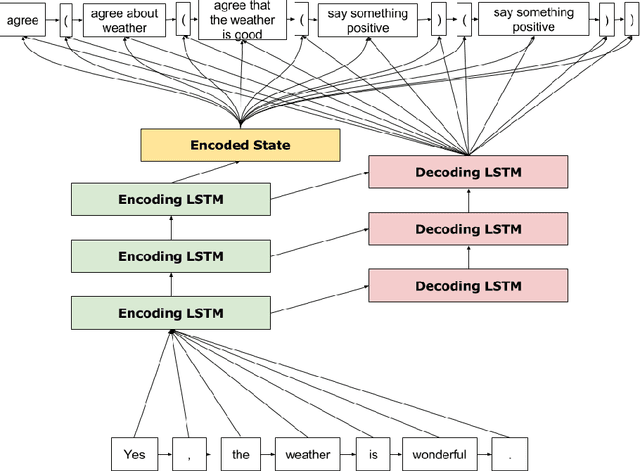
In this paper, we present a novel approach to natural language understanding that utilizes context-free grammars (CFGs) in conjunction with sequence-to-sequence (seq2seq) deep learning. Specifically, we take a CFG authored to generate dialogue for our target application for NLU, a videogame, and train a long short-term memory (LSTM) recurrent neural network (RNN) to map the surface utterances that it produces to traces of the grammatical expansions that yielded them. Critically, this CFG was authored using a tool we have developed that supports arbitrary annotation of the nonterminal symbols in the grammar. Because we already annotated the symbols in this grammar for the semantic and pragmatic considerations that our game's dialogue manager operates over, we can use the grammatical trace associated with any surface utterance to infer such information. During gameplay, we translate player utterances into grammatical traces (using our RNN), collect the mark-up attributed to the symbols included in that trace, and pass this information to the dialogue manager, which updates the conversation state accordingly. From an offline evaluation task, we demonstrate that our trained RNN translates surface utterances to grammatical traces with great accuracy. To our knowledge, this is the first usage of seq2seq learning for conversational agents (our game's characters) who explicitly reason over semantic and pragmatic considerations.