 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Clustered Federated Learning with Privacy-Preserving Initialization and Normality-Driven Aggregation
Apr 22, 2026Federated learning (FL) enables training of a global model while keeping raw data on end-devices. Despite this, FL has shown to leak private user information and thus in practice, it is often coupled with methods such as differential privacy (DP) and secure vector sum to provide formal privacy guarantees to its participants. In realistic cross-device deployments, the data are highly heterogeneous, so vanilla federated learning converges slowly and generalizes poorly. Clustered federated learning (CFL) mitigates this by segregating users into clusters, leading to lower intra-cluster data heterogeneity. Nevertheless, coupling CFL with DP remains challenging: the injected DP noise makes individual client updates excessively noisy, and the server is unable to initialize cluster centroids with the less noisy aggregated updates. To address this challenge, we propose PINA, a two-stage framework that first lets each client fine-tune a lightweight low-rank adaptation (LoRA) adapter and privately share a compressed sketch of the update. The server leverages these sketches to construct robust cluster centroids. In the second stage, PINA introduces a normality-driven aggregation mechanism that improves convergence and robustness. Our method retains the benefits of clustered FL while providing formal privacy guarantees against an untrusted server. Extensive evaluations show that our proposed method outperforms state-of-the-art DP-FL algorithms by an average of 2.9% in accuracy for privacy budgets (epsilon in {2, 8}).
FlowW2N: Whispered-to-Normal Speech Conversion via Flow-Matching
Mar 04, 2026Whispered-to-normal (W2N) speech conversion aims to reconstruct missing phonation from whispered input while preserving content and speaker identity. This task is challenging due to temporal misalignment between whisper and voiced recordings and lack of paired data. We propose FlowW2N, a conditional flow matching approach that trains exclusively on synthetic, time-aligned whisper-normal pairs and conditions on domain-invariant features. We exploit high-level ASR embeddings that exhibits strong invariance between synthetic and real whispered speech, enabling generalization to real whispers despite never observing it during training. We verify this invariance across ASR layers and propose a selection criterion optimizing content informativeness and cross-domain invariance. Our method achieves SOTA intelligibility on the CHAINS and wTIMIT datasets, reducing Word Error Rate by 26-46% relative to prior work while using only 10 steps at inference and requiring no real paired data.
Robust Target Speaker Diarization and Separation via Augmented Speaker Embedding Sampling
Aug 08, 2025Traditional speech separation and speaker diarization approaches rely on prior knowledge of target speakers or a predetermined number of participants in audio signals. To address these limitations, recent advances focus on developing enrollment-free methods capable of identifying targets without explicit speaker labeling. This work introduces a new approach to train simultaneous speech separation and diarization using automatic identification of target speaker embeddings, within mixtures. Our proposed model employs a dual-stage training pipeline designed to learn robust speaker representation features that are resilient to background noise interference. Furthermore, we present an overlapping spectral loss function specifically tailored for enhancing diarization accuracy during overlapped speech frames. Experimental results show significant performance gains compared to the current SOTA baseline, achieving 71% relative improvement in DER and 69% in cpWER.
ValSub: Subsampling Validation Data to Mitigate Forgetting during ASR Personalization
Mar 12, 2025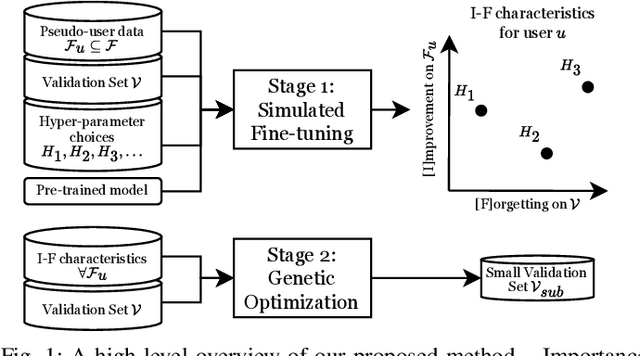
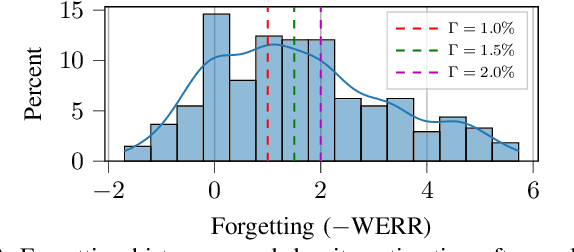
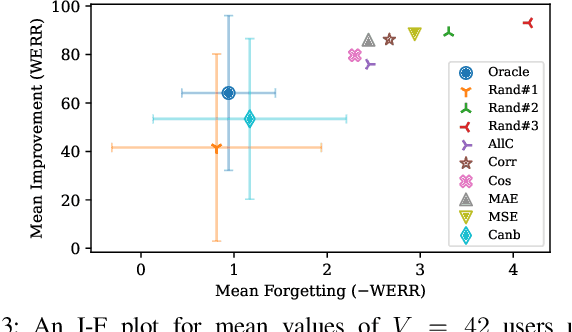
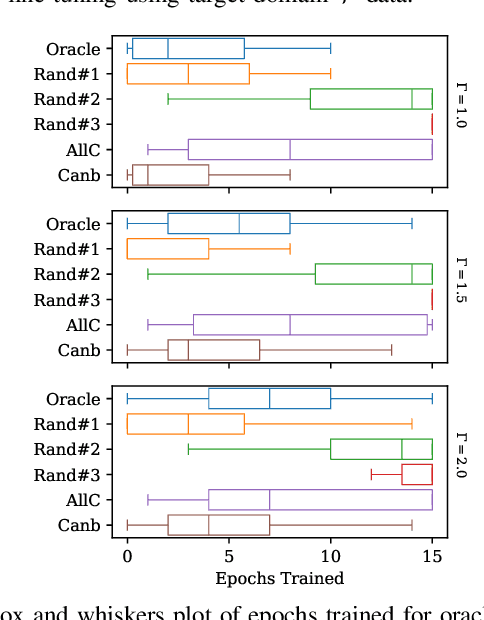
Automatic Speech Recognition (ASR) is widely used within consumer devices such as mobile phones. Recently, personalization or on-device model fine-tuning has shown that adaptation of ASR models towards target user speech improves their performance over rare words or accented speech. Despite these gains, fine-tuning on user data (target domain) risks the personalized model to forget knowledge about its original training distribution (source domain) i.e. catastrophic forgetting, leading to subpar general ASR performance. A simple and efficient approach to combat catastrophic forgetting is to measure forgetting via a validation set that represents the source domain distribution. However, such validation sets are large and impractical for mobile devices. Towards this, we propose a novel method to subsample a substantially large validation set into a smaller one while maintaining the ability to estimate forgetting. We demonstrate the efficacy of such a dataset in mitigating forgetting by utilizing it to dynamically determine the number of ideal fine-tuning epochs. When measuring the deviations in per user fine-tuning epochs against a 50x larger validation set (oracle), our method achieves a lower mean-absolute-error (3.39) compared to randomly selected subsets of the same size (3.78-8.65). Unlike random baselines, our method consistently tracks the oracle's behaviour across three different forgetting thresholds.
Diffusion based Text-to-Music Generation with Global and Local Text based Conditioning
Jan 27, 2025Diffusion based Text-To-Music (TTM) models generate music corresponding to text descriptions. Typically UNet based diffusion models condition on text embeddings generated from a pre-trained large language model or from a cross-modality audio-language representation model. This work proposes a diffusion based TTM, in which the UNet is conditioned on both (i) a uni-modal language model (e.g., T5) via cross-attention and (ii) a cross-modal audio-language representation model (e.g., CLAP) via Feature-wise Linear Modulation (FiLM). The diffusion model is trained to exploit both a local text representation from the T5 and a global representation from the CLAP. Furthermore, we propose modifications that extract both global and local representations from the T5 through pooling mechanisms that we call mean pooling and self-attention pooling. This approach mitigates the need for an additional encoder (e.g., CLAP) to extract a global representation, thereby reducing the number of model parameters. Our results show that incorporating the CLAP global embeddings to the T5 local embeddings enhances text adherence (KL=1.47) compared to a baseline model solely relying on the T5 local embeddings (KL=1.54). Alternatively, extracting global text embeddings directly from the T5 local embeddings through the proposed mean pooling approach yields superior generation quality (FAD=1.89) while exhibiting marginally inferior text adherence (KL=1.51) against the model conditioned on both CLAP and T5 text embeddings (FAD=1.94 and KL=1.47). Our proposed solution is not only efficient but also compact in terms of the number of parameters required.
persoDA: Personalized Data Augmentation for Personalized ASR
Jan 17, 2025



Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user's data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
persoDA: Personalized Data Augmentation forPersonalized ASR
Jan 15, 2025Data augmentation (DA) is ubiquitously used in training of Automatic Speech Recognition (ASR) models. DA offers increased data variability, robustness and generalization against different acoustic distortions. Recently, personalization of ASR models on mobile devices has been shown to improve Word Error Rate (WER). This paper evaluates data augmentation in this context and proposes persoDA; a DA method driven by user's data utilized to personalize ASR. persoDA aims to augment training with data specifically tuned towards acoustic characteristics of the end-user, as opposed to standard augmentation based on Multi-Condition Training (MCT) that applies random reverberation and noises. Our evaluation with an ASR conformer-based baseline trained on Librispeech and personalized for VOICES shows that persoDA achieves a 13.9% relative WER reduction over using standard data augmentation (using random noise & reverberation). Furthermore, persoDA shows 16% to 20% faster convergence over MCT.
Exploring compressibility of transformer based text-to-music (TTM) models
Jun 24, 2024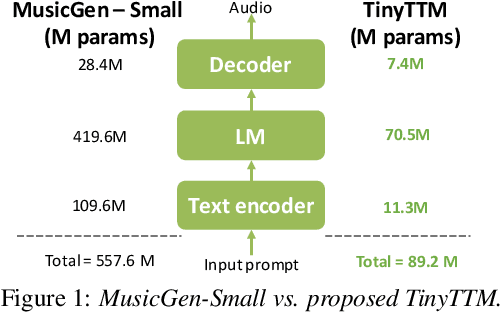
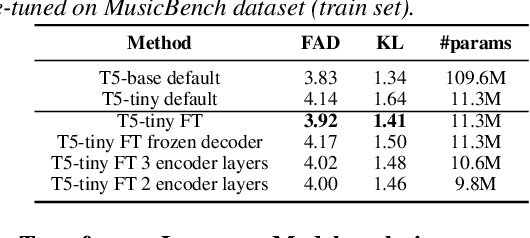
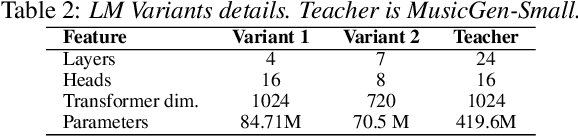
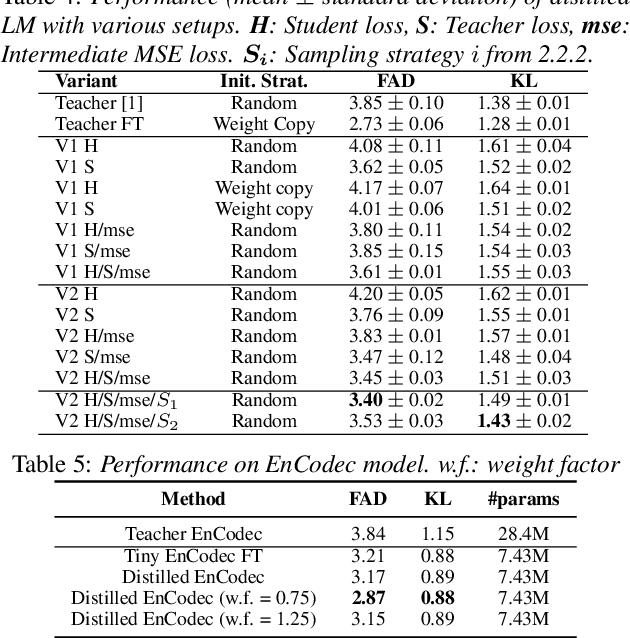
State-of-the art Text-To-Music (TTM) generative AI models are large and require desktop or server class compute, making them infeasible for deployment on mobile phones. This paper presents an analysis of trade-offs between model compression and generation performance of TTM models. We study compression through knowledge distillation and specific modifications that enable applicability over the various components of the TTM model (encoder, generative model and the decoder). Leveraging these methods we create TinyTTM (89.2M params) that achieves a FAD of 3.66 and KL of 1.32 on MusicBench dataset, better than MusicGen-Small (557.6M params) but not lower than MusicGen-small fine-tuned on MusicBench.
DP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
May 10, 2024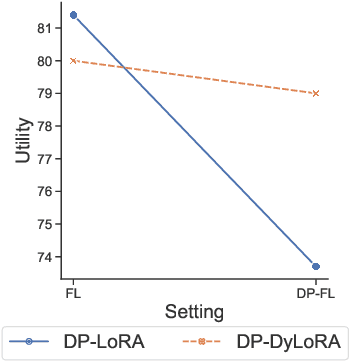
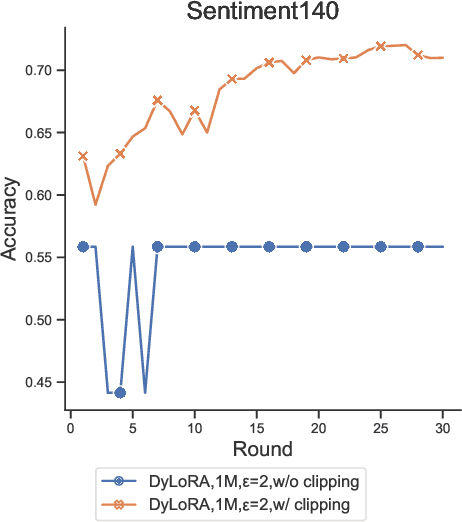
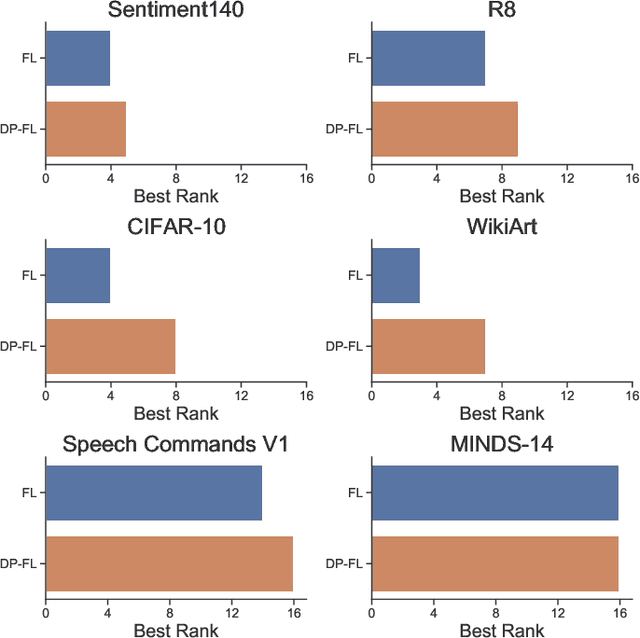
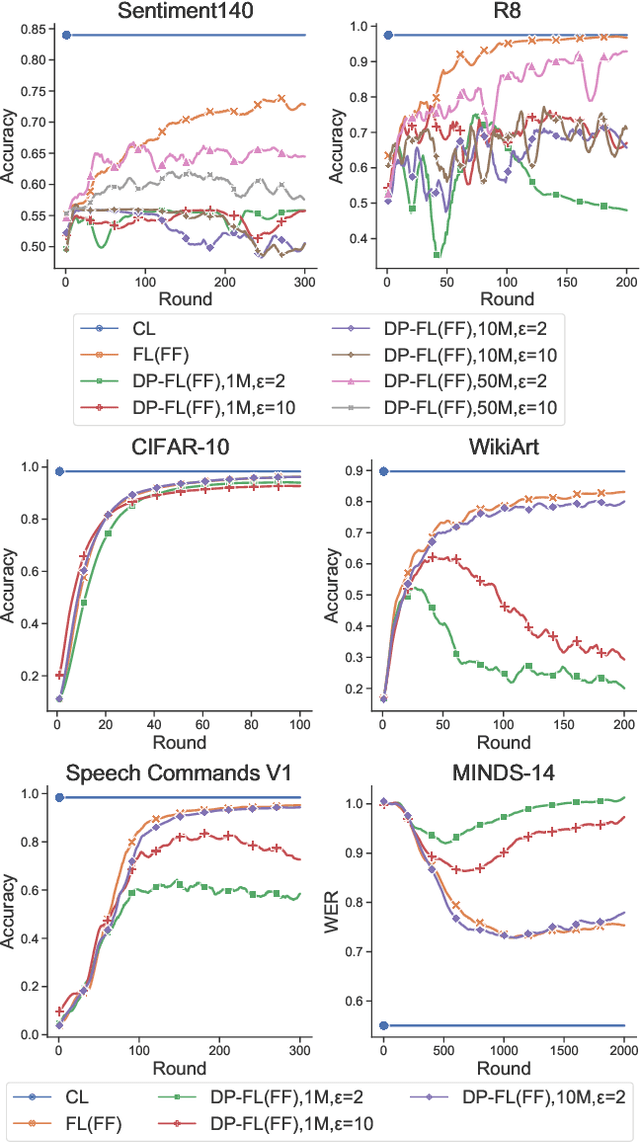
Federated learning (FL) allows clients in an Internet of Things (IoT) system to collaboratively train a global model without sharing their local data with a server. However, clients' contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients' contributions. The randomness makes it infeasible to train large transformer-based models, common in modern IoT systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of {\epsilon}=2.
Locality enhanced dynamic biasing and sampling strategies for contextual ASR
Jan 23, 2024Automatic Speech Recognition (ASR) still face challenges when recognizing time-variant rare-phrases. Contextual biasing (CB) modules bias ASR model towards such contextually-relevant phrases. During training, a list of biasing phrases are selected from a large pool of phrases following a sampling strategy. In this work we firstly analyse different sampling strategies to provide insights into the training of CB for ASR with correlation plots between the bias embeddings among various training stages. Secondly, we introduce a neighbourhood attention (NA) that localizes self attention (SA) to the nearest neighbouring frames to further refine the CB output. The results show that this proposed approach provides on average a 25.84% relative WER improvement on LibriSpeech sets and rare-word evaluation compared to the baseline.