 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistency Based Unsupervised Self-training For ASR Personalisation
Paper and Code
Jan 22, 2024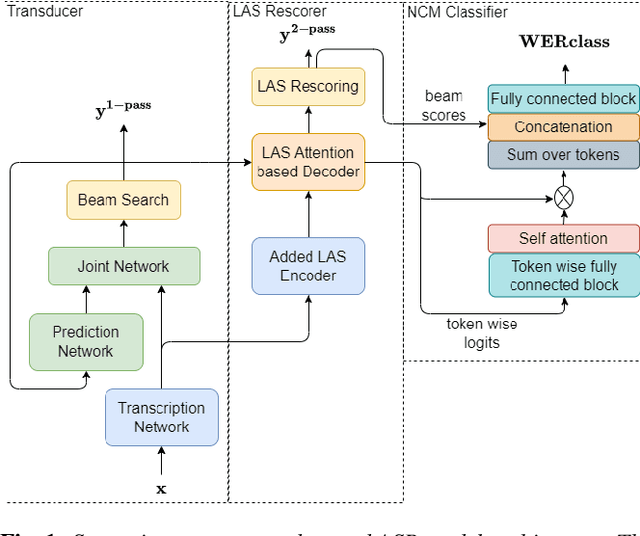

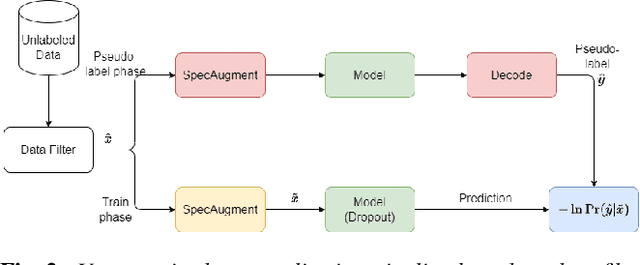
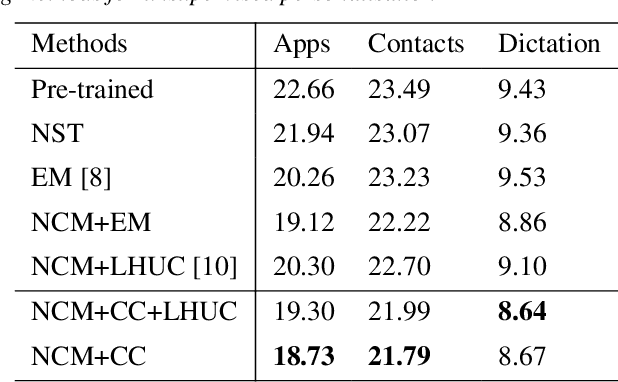
On-device Automatic Speech Recognition (ASR) models trained on speech data of a large population might underperform for individuals unseen during training. This is due to a domain shift between user data and the original training data, differed by user's speaking characteristics and environmental acoustic conditions. ASR personalisation is a solution that aims to exploit user data to improve model robustness. The majority of ASR personalisation methods assume labelled user data for supervision. Personalisation without any labelled data is challenging due to limited data size and poor quality of recorded audio samples. This work addresses unsupervised personalisation by developing a novel consistency based training method via pseudo-labelling. Our method achieves a relative Word Error Rate Reduction (WERR) of 17.3% on unlabelled training data and 8.1% on held-out data compared to a pre-trained model, and outperforms the current state-of-the art methods.