 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValSub: Subsampling Validation Data to Mitigate Forgetting during ASR Personalization
Paper and Code
Mar 12, 2025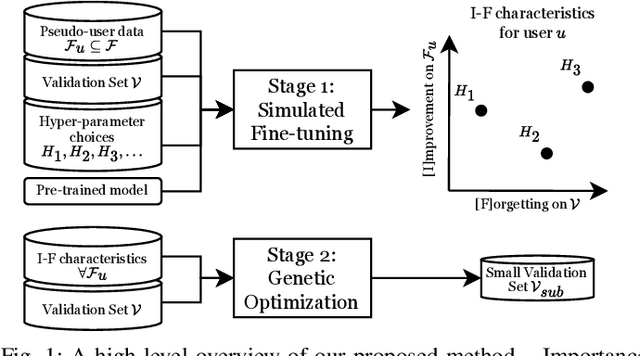
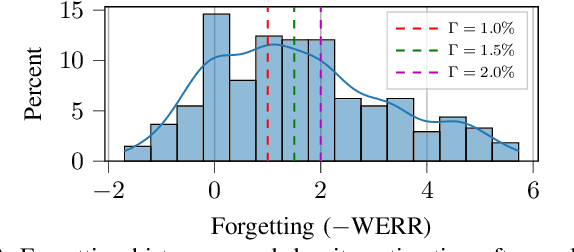
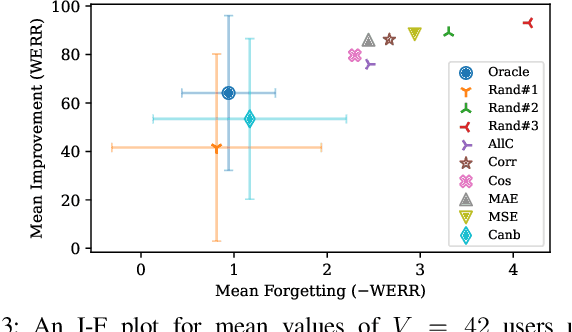
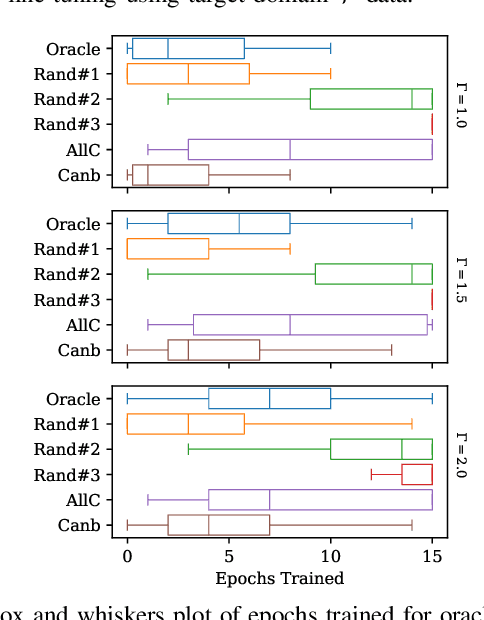
Automatic Speech Recognition (ASR) is widely used within consumer devices such as mobile phones. Recently, personalization or on-device model fine-tuning has shown that adaptation of ASR models towards target user speech improves their performance over rare words or accented speech. Despite these gains, fine-tuning on user data (target domain) risks the personalized model to forget knowledge about its original training distribution (source domain) i.e. catastrophic forgetting, leading to subpar general ASR performance. A simple and efficient approach to combat catastrophic forgetting is to measure forgetting via a validation set that represents the source domain distribution. However, such validation sets are large and impractical for mobile devices. Towards this, we propose a novel method to subsample a substantially large validation set into a smaller one while maintaining the ability to estimate forgetting. We demonstrate the efficacy of such a dataset in mitigating forgetting by utilizing it to dynamically determine the number of ideal fine-tuning epochs. When measuring the deviations in per user fine-tuning epochs against a 50x larger validation set (oracle), our method achieves a lower mean-absolute-error (3.39) compared to randomly selected subsets of the same size (3.78-8.65). Unlike random baselines, our method consistently tracks the oracle's behaviour across three different forgetting thresholds.