Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgepMCT: Patched Multi-Condition Training for Robust Speech Recognition
Paper and Code
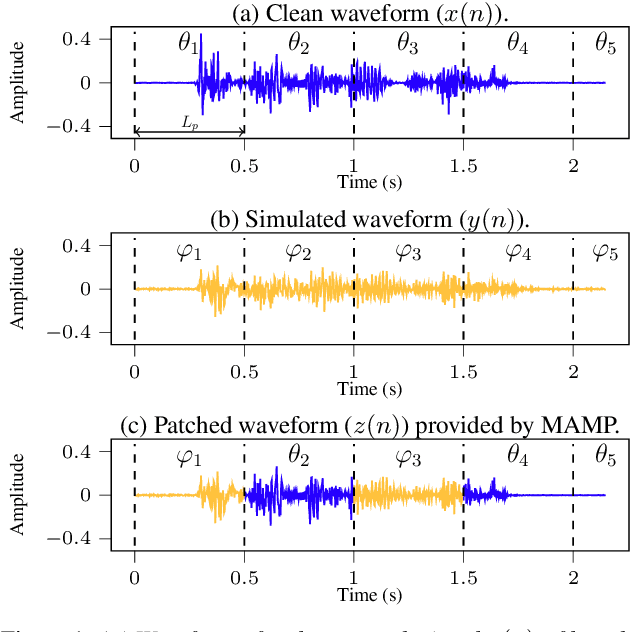
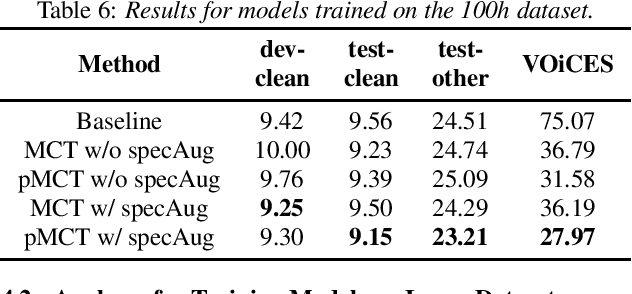
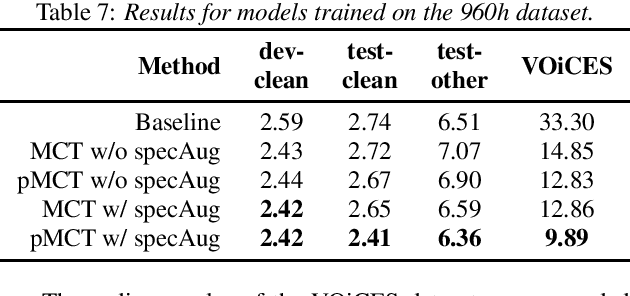
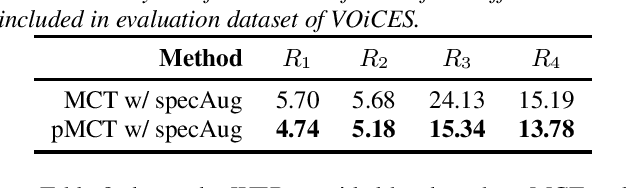
We propose a novel Patched Multi-Condition Training (pMCT) method for robust Automatic Speech Recognition (ASR). pMCT employs Multi-condition Audio Modification and Patching (MAMP) via mixing {\it patches} of the same utterance extracted from clean and distorted speech. Training using patch-modified signals improves robustness of models in noisy reverberant scenarios. Our proposed pMCT is evaluated on the LibriSpeech dataset showing improvement over using vanilla Multi-Condition Training (MCT). For analyses on robust ASR, we employed pMCT on the VOiCES dataset which is a noisy reverberant dataset created using utterances from LibriSpeech. In the analyses, pMCT achieves 23.1% relative WER reduction compared to the MCT.
* Accepted at Interspeech 2022
View paper on