 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
Paper and Code
May 10, 2024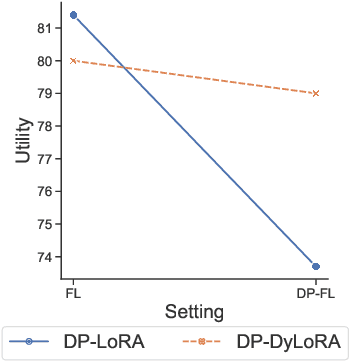
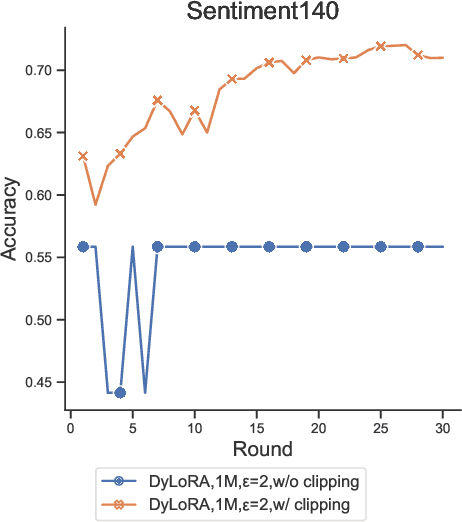
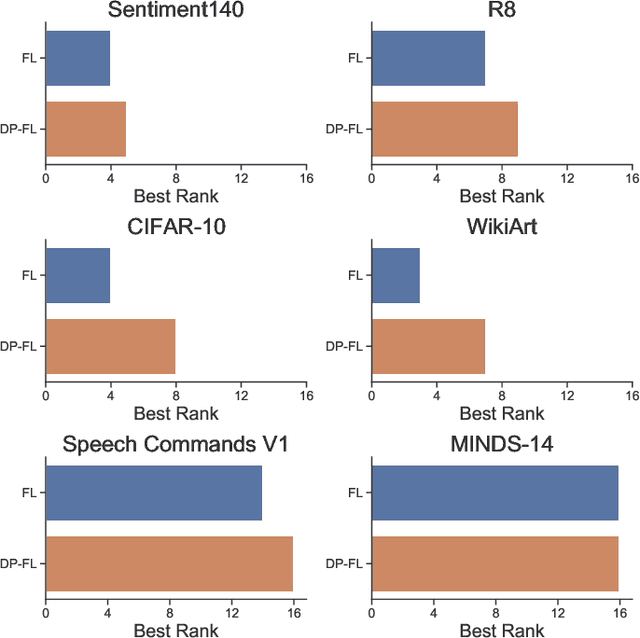
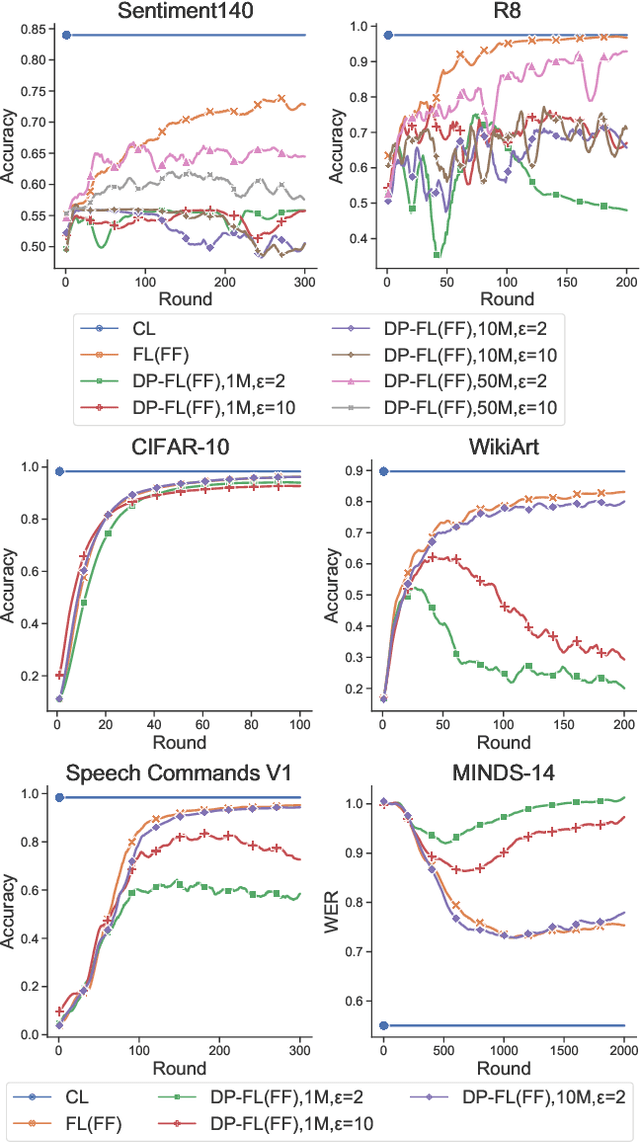
Federated learning (FL) allows clients in an Internet of Things (IoT) system to collaboratively train a global model without sharing their local data with a server. However, clients' contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients' contributions. The randomness makes it infeasible to train large transformer-based models, common in modern IoT systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of {\epsilon}=2.