Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring compressibility of transformer based text-to-music (TTM) models
Paper and Code
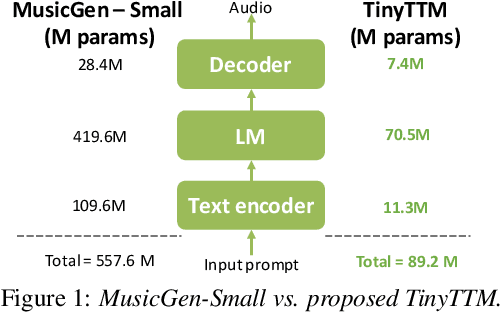
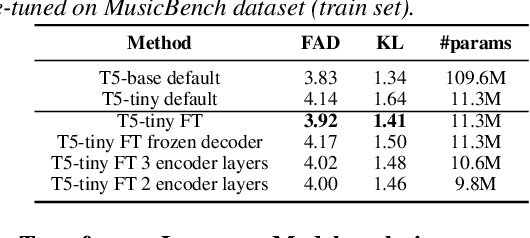
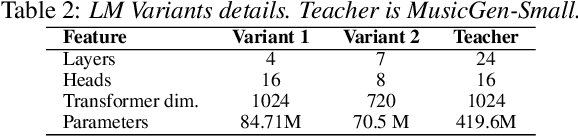
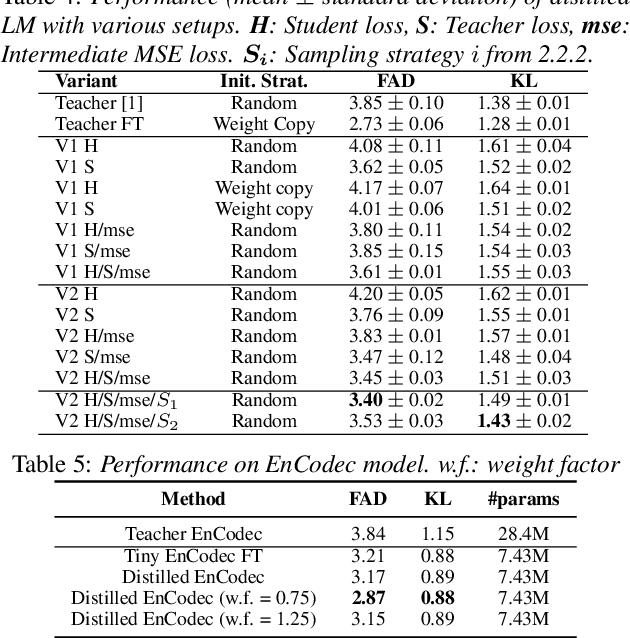
State-of-the art Text-To-Music (TTM) generative AI models are large and require desktop or server class compute, making them infeasible for deployment on mobile phones. This paper presents an analysis of trade-offs between model compression and generation performance of TTM models. We study compression through knowledge distillation and specific modifications that enable applicability over the various components of the TTM model (encoder, generative model and the decoder). Leveraging these methods we create TinyTTM (89.2M params) that achieves a FAD of 3.66 and KL of 1.32 on MusicBench dataset, better than MusicGen-Small (557.6M params) but not lower than MusicGen-small fine-tuned on MusicBench.
* Proceedings of INTERSPEECH 2024
View paper on