 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaliency Maps Generation for Automatic Text Summarization
Paper and Code
Jul 12, 2019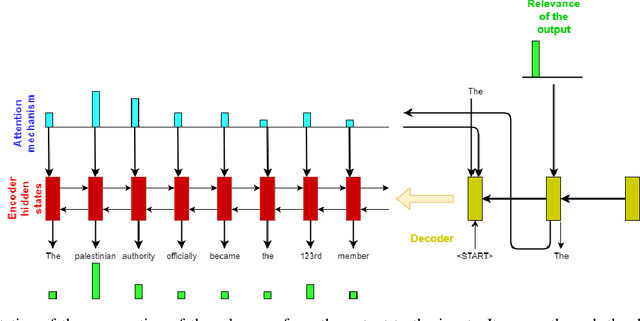


Saliency map generation techniques are at the forefront of explainable AI literature for a broad range of machine learning applications. Our goal is to question the limits of these approaches on more complex tasks. In this paper we apply Layer-Wise Relevance Propagation (LRP) to a sequence-to-sequence attention model trained on a text summarization dataset. We obtain unexpected saliency maps and discuss the rightfulness of these "explanations". We argue that we need a quantitative way of testing the counterfactual case to judge the truthfulness of the saliency maps. We suggest a protocol to check the validity of the importance attributed to the input and show that the saliency maps obtained sometimes capture the real use of the input features by the network, and sometimes do not. We use this example to discuss how careful we need to be when accepting them as explanation.