 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchies of Reward Machines
May 31, 2022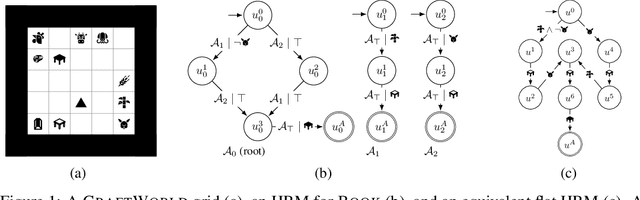


Reward machines (RMs) are a recent formalism for representing the reward function of a reinforcement learning task through a finite-state machine whose edges encode landmarks of the task using high-level events. The structure of RMs enables the decomposition of a task into simpler and independently solvable subtasks that help tackle long-horizon and/or sparse reward tasks. We propose a formalism for further abstracting the subtask structure by endowing an RM with the ability to call other RMs, thus composing a hierarchy of RMs (HRM). We exploit HRMs by treating each call to an RM as an independently solvable subtask using the options framework, and describe a curriculum-based method to induce HRMs from example traces observed by the agent. Our experiments reveal that exploiting a handcrafted HRM leads to faster convergence than with a flat HRM, and that learning an HRM is more scalable than learning an equivalent flat HRM.
Reactive Answer Set Programming
Sep 22, 2021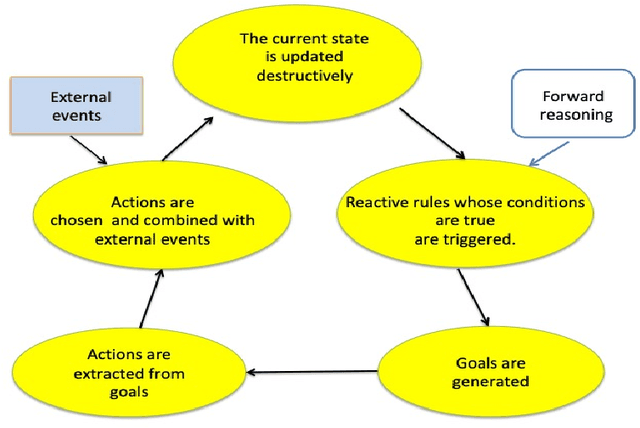

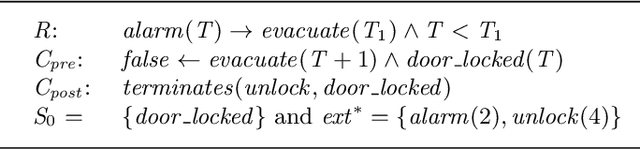

Logic Production System (LPS) is a logic-based framework for modelling reactive behaviour. Based on abductive logic programming, it combines reactive rules with logic programs, a database and a causal theory that specifies transitions between the states of the database. This paper proposes a systematic mapping of the Kernel of this framework (called KELPS) into an answer set program (ASP). For this purpose a new variant of KELPS with finite models, called $n$-distance KELPS, is introduced. A formal definition of the mapping from this $n$-distance KELPS to ASP is given and proven sound and complete. The Answer Set Programming paradigm allows to capture additional behaviours to the basic reactivity of KELPS, in particular proactive, preemptive and prospective behaviours. These are all discussed and illustrated with examples. Then a hybrid framework is proposed that integrates KELPS and ASP, allowing to combine the strengths of both paradigms. Under consideration in Theory and Practice of Logic Programming (TPLP).
Induction and Exploitation of Subgoal Automata for Reinforcement Learning
Sep 08, 2020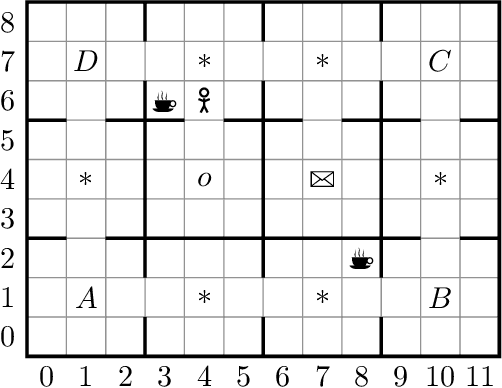
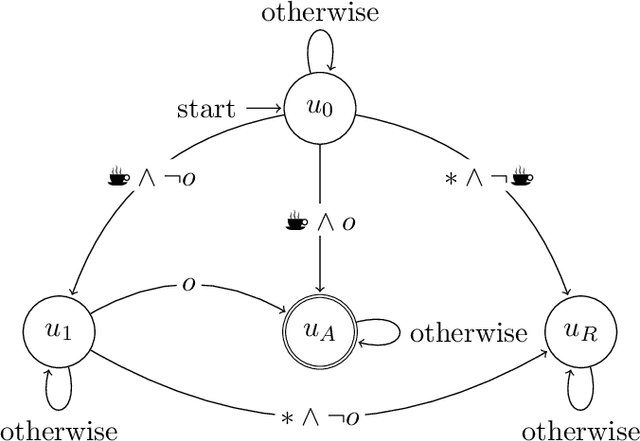

In this paper we present ISA, an approach for learning and exploiting subgoals in episodic reinforcement learning (RL) tasks. ISA interleaves reinforcement learning with the induction of a subgoal automaton, an automaton whose edges are labeled by the task's subgoals expressed as propositional logic formulas over a set of high-level events. A subgoal automaton also consists of two special states: a state indicating the successful completion of the task, and a state indicating that the task has finished without succeeding. A state-of-the-art inductive logic programming system is used to learn a subgoal automaton that covers the traces of high-level events observed by the RL agent. When the currently exploited automaton does not correctly recognize a trace, the automaton learner induces a new automaton that covers that trace. The interleaving process guarantees the induction of automata with the minimum number of states, and applies a symmetry breaking mechanism to shrink the search space whilst remaining complete. We evaluate ISA in several grid-world and continuous state space problems using different RL algorithms that leverage the automaton structures. We provide an in-depth empirical analysis of the automaton learning process performance in terms of the traces, the symmetric breaking and specific restrictions imposed on the final learnable automaton. For each class of RL problem, we show that the learned automata can be successfully exploited to learn policies that reach the goal, achieving an average reward comparable to the case where automata are not learned but handcrafted and given beforehand.
The ILASP system for Inductive Learning of Answer Set Programs
May 02, 2020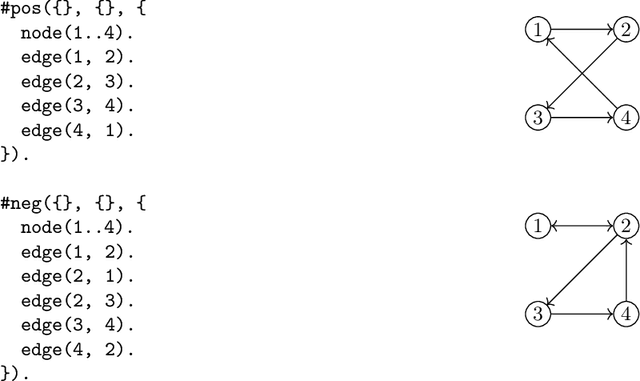
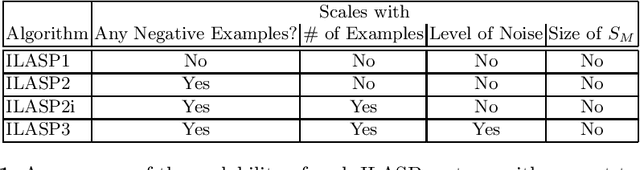
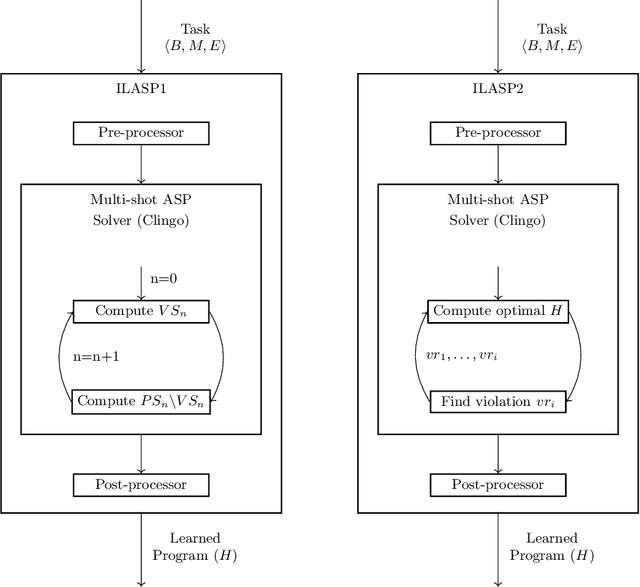
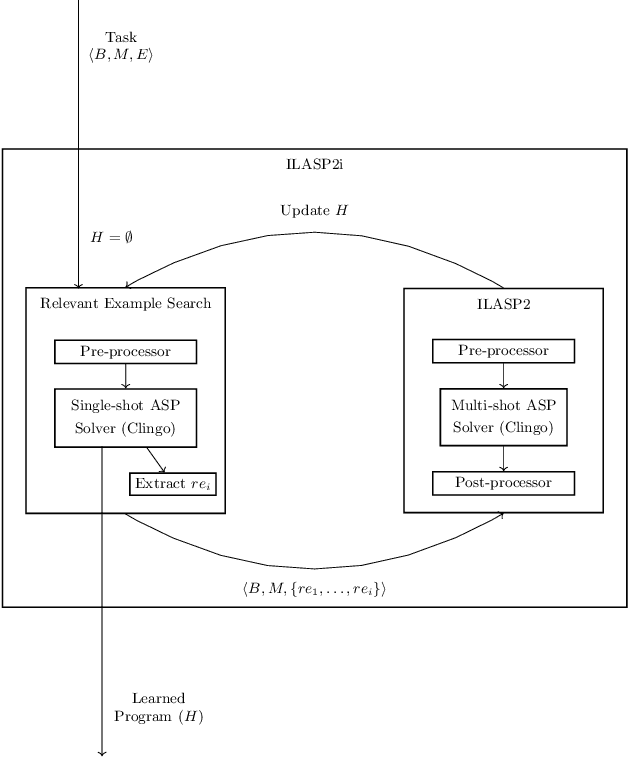
The goal of Inductive Logic Programming (ILP) is to learn a program that explains a set of examples in the context of some pre-existing background knowledge. Until recently, most research on ILP targeted learning Prolog programs. Our own ILASP system instead learns Answer Set Programs, including normal rules, choice rules and hard and weak constraints. Learning such expressive programs widens the applicability of ILP considerably; for example, enabling preference learning, learning common-sense knowledge, including defaults and exceptions, and learning non-deterministic theories. In this paper, we first give a general overview of ILASP's learning framework and its capabilities. This is followed by a comprehensive summary of the evolution of the ILASP system, presenting the strengths and weaknesses of each version, with a particular emphasis on scalability.
A general framework for scientifically inspired explanations in AI
Mar 02, 2020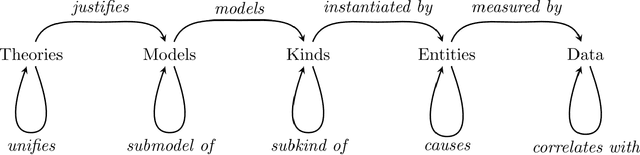
Explainability in AI is gaining attention in the computer science community in response to the increasing success of deep learning and the important need of justifying how such systems make predictions in life-critical applications. The focus of explainability in AI has predominantly been on trying to gain insights into how machine learning systems function by exploring relationships between input data and predicted outcomes or by extracting simpler interpretable models. Through literature surveys of philosophy and social science, authors have highlighted the sharp difference between these generated explanations and human-made explanations and claimed that current explanations in AI do not take into account the complexity of human interaction to allow for effective information passing to not-expert users. In this paper we instantiate the concept of structure of scientific explanation as the theoretical underpinning for a general framework in which explanations for AI systems can be implemented. This framework aims to provide the tools to build a "mental-model" of any AI system so that the interaction with the user can provide information on demand and be closer to the nature of human-made explanations. We illustrate how we can utilize this framework through two very different examples: an artificial neural network and a Prolog solver and we provide a possible implementation for both examples.
Induction of Subgoal Automata for Reinforcement Learning
Nov 29, 2019

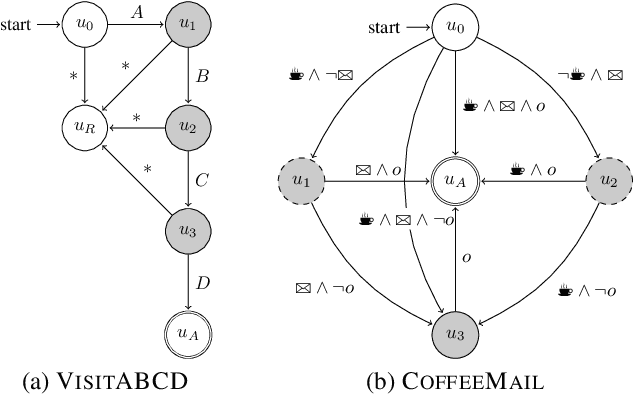
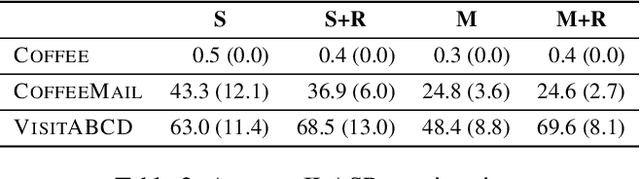
In this work we present ISA, a novel approach for learning and exploiting subgoals in reinforcement learning (RL). Our method relies on inducing an automaton whose transitions are subgoals expressed as propositional formulas over a set of observable events. A state-of-the-art inductive logic programming system is used to learn the automaton from observation traces perceived by the RL agent. The reinforcement learning and automaton learning processes are interleaved: a new refined automaton is learned whenever the RL agent generates a trace not recognized by the current automaton. We evaluate ISA in several gridworld problems and show that it performs similarly to a method for which automata are given in advance. We also show that the learned automata can be exploited to speed up convergence through reward shaping and transfer learning across multiple tasks. Finally, we analyze the running time and the number of traces that ISA needs to learn an automata, and the impact that the number of observable events has on the learner's performance.
Saliency Maps Generation for Automatic Text Summarization
Jul 12, 2019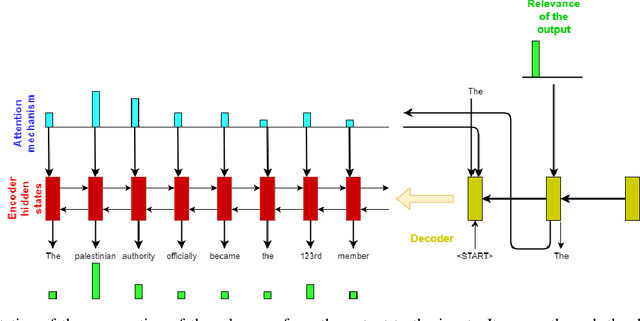


Saliency map generation techniques are at the forefront of explainable AI literature for a broad range of machine learning applications. Our goal is to question the limits of these approaches on more complex tasks. In this paper we apply Layer-Wise Relevance Propagation (LRP) to a sequence-to-sequence attention model trained on a text summarization dataset. We obtain unexpected saliency maps and discuss the rightfulness of these "explanations". We argue that we need a quantitative way of testing the counterfactual case to judge the truthfulness of the saliency maps. We suggest a protocol to check the validity of the importance attributed to the input and show that the saliency maps obtained sometimes capture the real use of the input features by the network, and sometimes do not. We use this example to discuss how careful we need to be when accepting them as explanation.
Inductive Learning of Answer Set Programs from Noisy Examples
Aug 25, 2018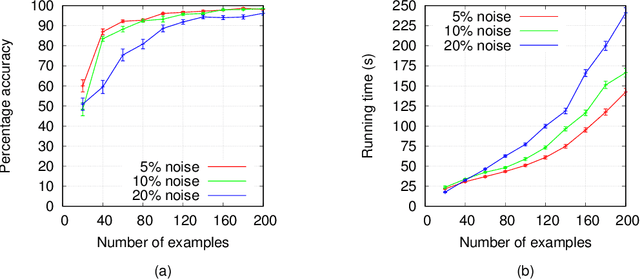
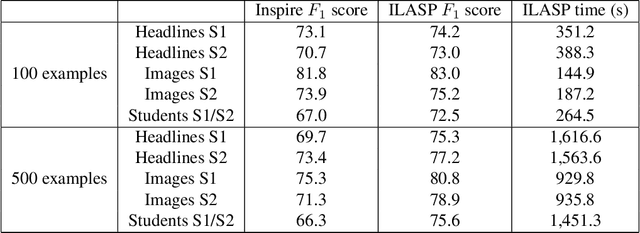
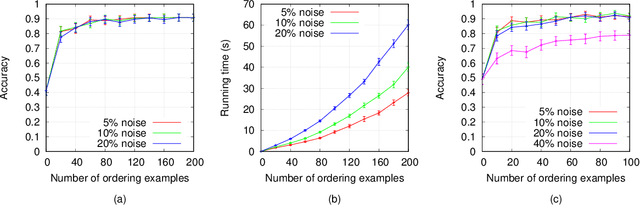

In recent years, non-monotonic Inductive Logic Programming has received growing interest. Specifically, several new learning frameworks and algorithms have been introduced for learning under the answer set semantics, allowing the learning of common-sense knowledge involving defaults and exceptions, which are essential aspects of human reasoning. In this paper, we present a noise-tolerant generalisation of the learning from answer sets framework. We evaluate our ILASP3 system, both on synthetic and on real datasets, represented in the new framework. In particular, we show that on many of the datasets ILASP3 achieves a higher accuracy than other ILP systems that have previously been applied to the datasets, including a recently proposed differentiable learning framework.
Iterative Learning of Answer Set Programs from Context Dependent Examples
Aug 05, 2016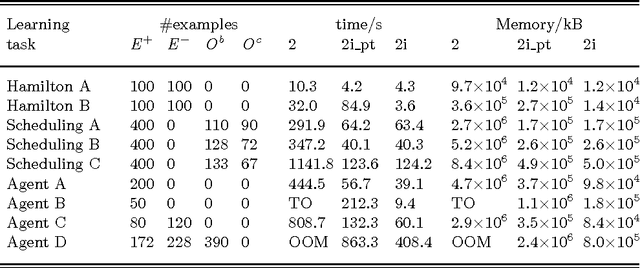
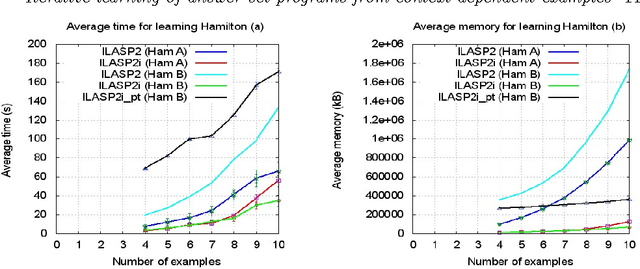
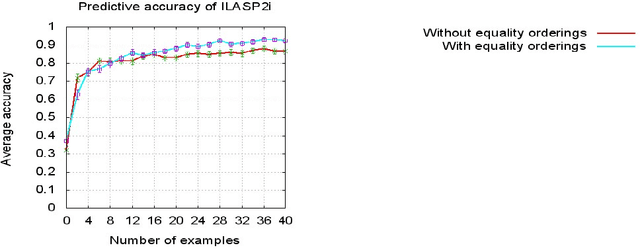
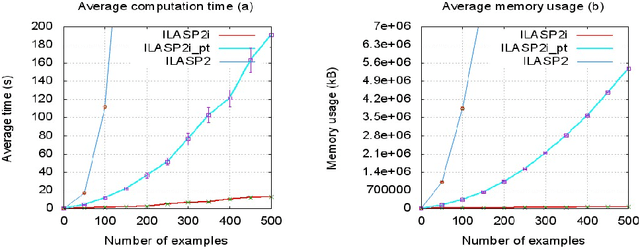
In recent years, several frameworks and systems have been proposed that extend Inductive Logic Programming (ILP) to the Answer Set Programming (ASP) paradigm. In ILP, examples must all be explained by a hypothesis together with a given background knowledge. In existing systems, the background knowledge is the same for all examples; however, examples may be context-dependent. This means that some examples should be explained in the context of some information, whereas others should be explained in different contexts. In this paper, we capture this notion and present a context-dependent extension of the Learning from Ordered Answer Sets framework. In this extension, contexts can be used to further structure the background knowledge. We then propose a new iterative algorithm, ILASP2i, which exploits this feature to scale up the existing ILASP2 system to learning tasks with large numbers of examples. We demonstrate the gain in scalability by applying both algorithms to various learning tasks. Our results show that, compared to ILASP2, the newly proposed ILASP2i system can be two orders of magnitude faster and use two orders of magnitude less memory, whilst preserving the same average accuracy. This paper is under consideration for acceptance in TPLP.
Learning Weak Constraints in Answer Set Programming
Jul 23, 2015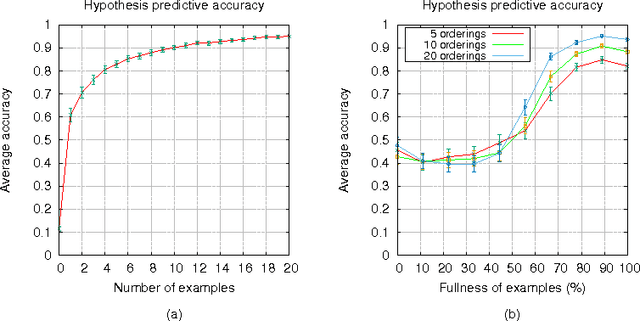
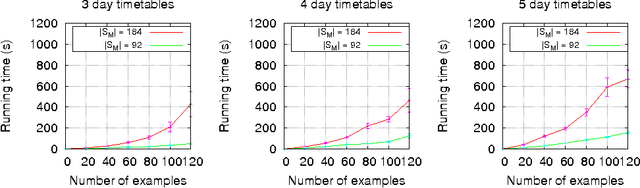
This paper contributes to the area of inductive logic programming by presenting a new learning framework that allows the learning of weak constraints in Answer Set Programming (ASP). The framework, called Learning from Ordered Answer Sets, generalises our previous work on learning ASP programs without weak constraints, by considering a new notion of examples as ordered pairs of partial answer sets that exemplify which answer sets of a learned hypothesis (together with a given background knowledge) are preferred to others. In this new learning task inductive solutions are searched within a hypothesis space of normal rules, choice rules, and hard and weak constraints. We propose a new algorithm, ILASP2, which is sound and complete with respect to our new learning framework. We investigate its applicability to learning preferences in an interview scheduling problem and also demonstrate that when restricted to the task of learning ASP programs without weak constraints, ILASP2 can be much more efficient than our previously proposed system.
* To appear in Theory and Practice of Logic Programming (TPLP), Proceedings of ICLP 2015