 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInduction and Exploitation of Subgoal Automata for Reinforcement Learning
Paper and Code
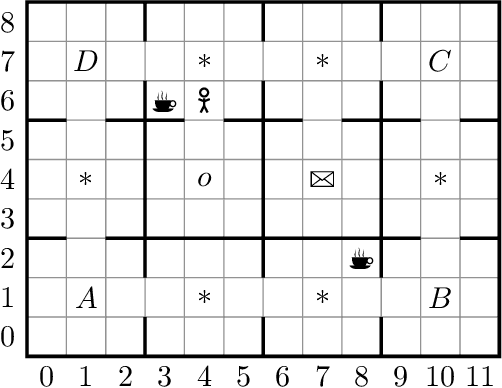
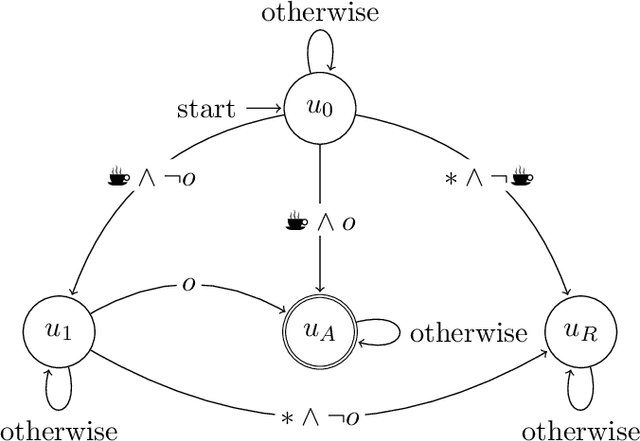

In this paper we present ISA, an approach for learning and exploiting subgoals in episodic reinforcement learning (RL) tasks. ISA interleaves reinforcement learning with the induction of a subgoal automaton, an automaton whose edges are labeled by the task's subgoals expressed as propositional logic formulas over a set of high-level events. A subgoal automaton also consists of two special states: a state indicating the successful completion of the task, and a state indicating that the task has finished without succeeding. A state-of-the-art inductive logic programming system is used to learn a subgoal automaton that covers the traces of high-level events observed by the RL agent. When the currently exploited automaton does not correctly recognize a trace, the automaton learner induces a new automaton that covers that trace. The interleaving process guarantees the induction of automata with the minimum number of states, and applies a symmetry breaking mechanism to shrink the search space whilst remaining complete. We evaluate ISA in several grid-world and continuous state space problems using different RL algorithms that leverage the automaton structures. We provide an in-depth empirical analysis of the automaton learning process performance in terms of the traces, the symmetric breaking and specific restrictions imposed on the final learnable automaton. For each class of RL problem, we show that the learned automata can be successfully exploited to learn policies that reach the goal, achieving an average reward comparable to the case where automata are not learned but handcrafted and given beforehand.