 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Lengthy to Lucid: A Systematic Literature Review on NLP Techniques for Taming Long Sentences
Dec 08, 2023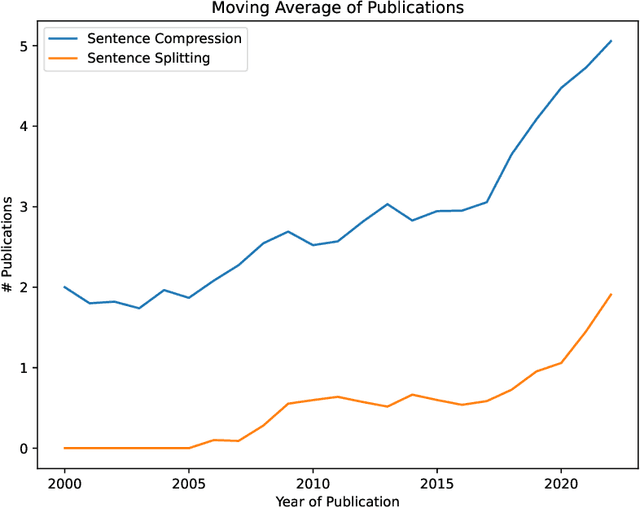
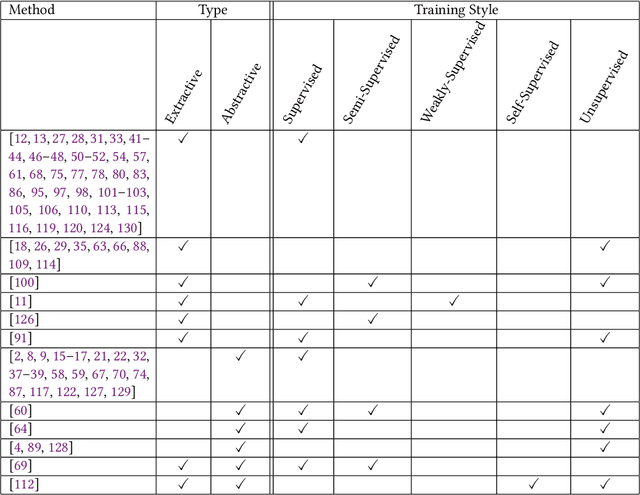
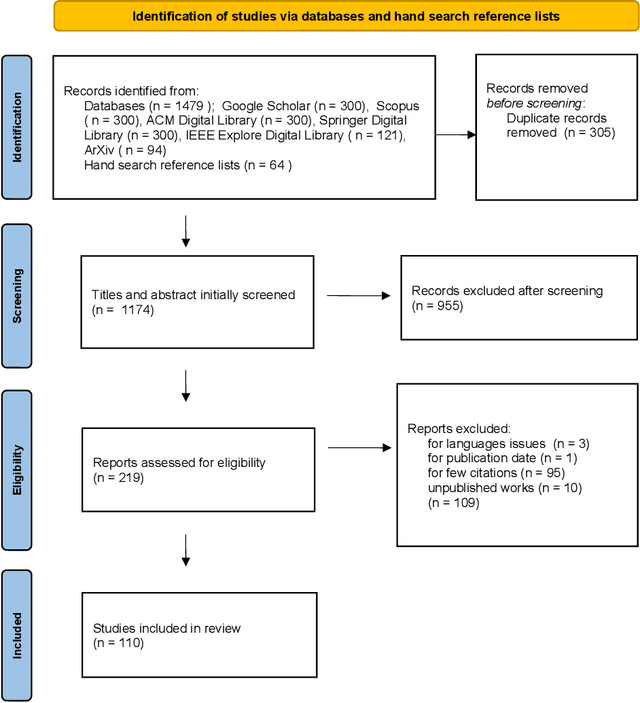
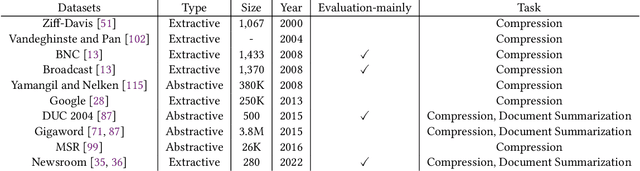
Long sentences have been a persistent issue in written communication for many years since they make it challenging for readers to grasp the main points or follow the initial intention of the writer. This survey, conducted using the PRISMA guidelines, systematically reviews two main strategies for addressing the issue of long sentences: a) sentence compression and b) sentence splitting. An increased trend of interest in this area has been observed since 2005, with significant growth after 2017. Current research is dominated by supervised approaches for both sentence compression and splitting. Yet, there is a considerable gap in weakly and self-supervised techniques, suggesting an opportunity for further research, especially in domains with limited data. In this survey, we categorize and group the most representative methods into a comprehensive taxonomy. We also conduct a comparative evaluation analysis of these methods on common sentence compression and splitting datasets. Finally, we discuss the challenges and limitations of current methods, providing valuable insights for future research directions. This survey is meant to serve as a comprehensive resource for addressing the complexities of long sentences. We aim to enable researchers to make further advancements in the field until long sentences are no longer a barrier to effective communication.
Learning to Teach Reinforcement Learning Agents
Jul 28, 2017

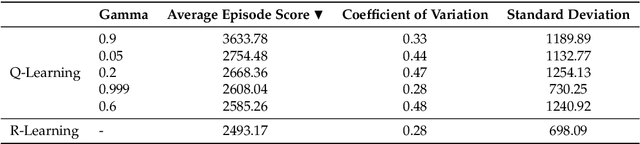
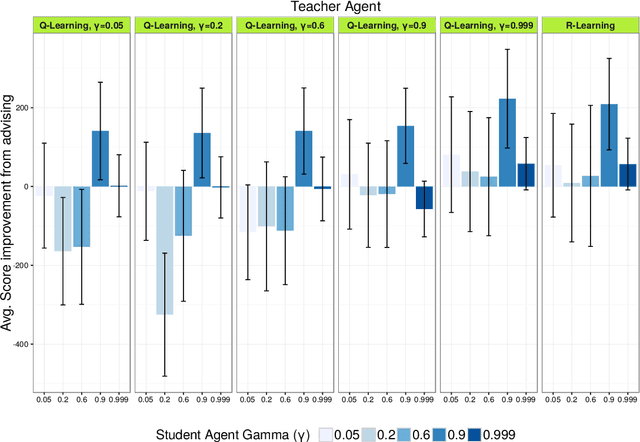
In this article we study the transfer learning model of action advice under a budget. We focus on reinforcement learning teachers providing action advice to heterogeneous students playing the game of Pac-Man under a limited advice budget. First, we examine several critical factors affecting advice quality in this setting, such as the average performance of the teacher, its variance and the importance of reward discounting in advising. The experiments show the non-trivial importance of the coefficient of variation (CV) as a statistic for choosing policies that generate advice. The CV statistic relates variance to the corresponding mean. Second, the article studies policy learning for distributing advice under a budget. Whereas most methods in the relevant literature rely on heuristics for advice distribution we formulate the problem as a learning one and propose a novel RL algorithm capable of learning when to advise, adapting to the student and the task at hand. Furthermore, we argue that learning to advise under a budget is an instance of a more generic learning problem: Constrained Exploitation Reinforcement Learning.