 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Lengthy to Lucid: A Systematic Literature Review on NLP Techniques for Taming Long Sentences
Dec 08, 2023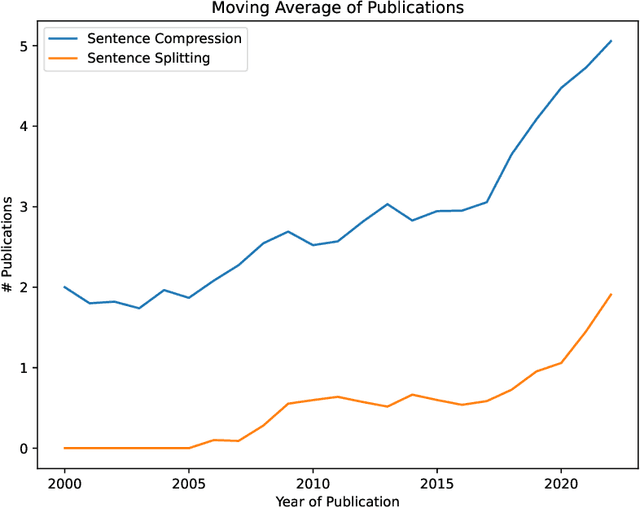
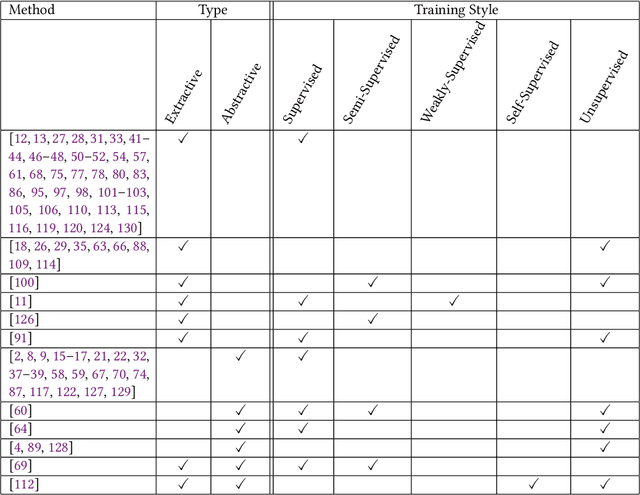
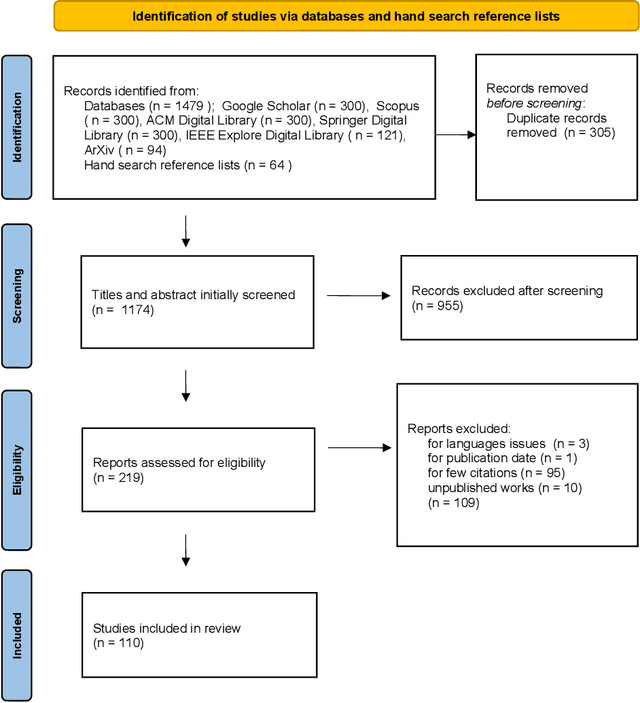
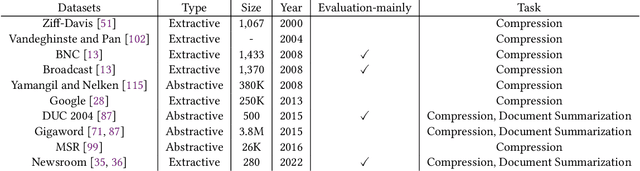
Long sentences have been a persistent issue in written communication for many years since they make it challenging for readers to grasp the main points or follow the initial intention of the writer. This survey, conducted using the PRISMA guidelines, systematically reviews two main strategies for addressing the issue of long sentences: a) sentence compression and b) sentence splitting. An increased trend of interest in this area has been observed since 2005, with significant growth after 2017. Current research is dominated by supervised approaches for both sentence compression and splitting. Yet, there is a considerable gap in weakly and self-supervised techniques, suggesting an opportunity for further research, especially in domains with limited data. In this survey, we categorize and group the most representative methods into a comprehensive taxonomy. We also conduct a comparative evaluation analysis of these methods on common sentence compression and splitting datasets. Finally, we discuss the challenges and limitations of current methods, providing valuable insights for future research directions. This survey is meant to serve as a comprehensive resource for addressing the complexities of long sentences. We aim to enable researchers to make further advancements in the field until long sentences are no longer a barrier to effective communication.
Topic-Aware Evaluation and Transformer Methods for Topic-Controllable Summarization
Jun 13, 2022



Topic-controllable summarization is an emerging research area with a wide range of potential applications. However, existing approaches suffer from significant limitations. First, there is currently no established evaluation metric for this task. Furthermore, existing methods built upon recurrent architectures, which can significantly limit their performance compared to more recent Transformer-based architectures, while they also require modifications to the model's architecture for controlling the topic. In this work, we propose a new topic-oriented evaluation measure to automatically evaluate the generated summaries based on the topic affinity between the generated summary and the desired topic. We also conducted a user study that validates the reliability of this measure. Finally, we propose simple, yet powerful methods for topic-controllable summarization either incorporating topic embeddings into the model's architecture or employing control tokens to guide the summary generation. Experimental results show that control tokens can achieve better performance compared to more complicated embedding-based approaches while being at the same time significantly faster.