 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-target regression via output space quantization
Mar 22, 2020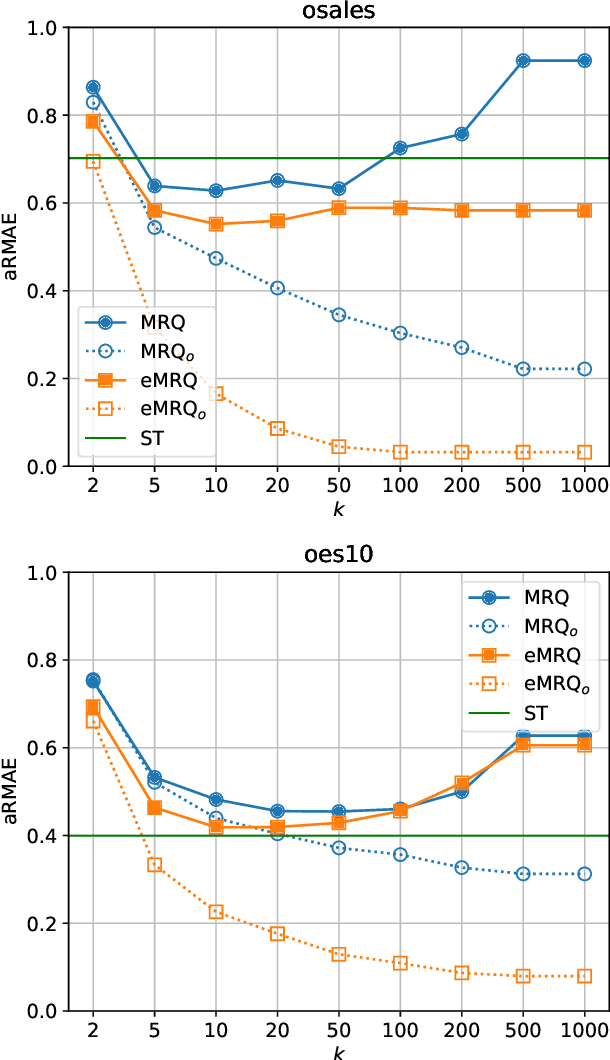
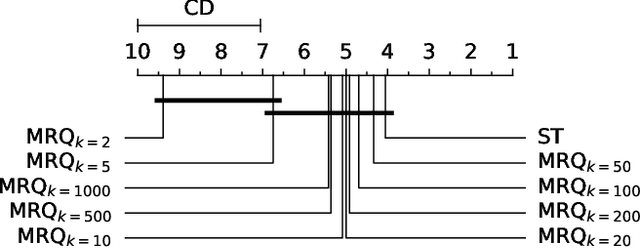
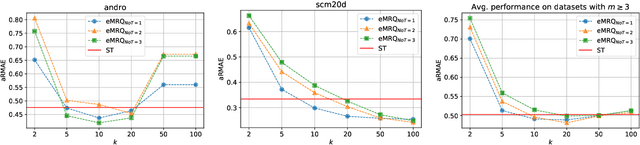
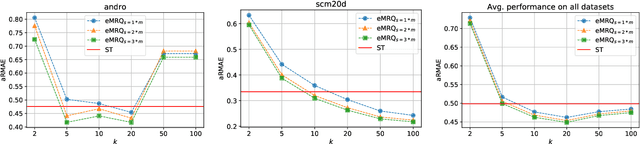
Multi-target regression is concerned with the prediction of multiple continuous target variables using a shared set of predictors. Two key challenges in multi-target regression are: (a) modelling target dependencies and (b) scalability to large output spaces. In this paper, a new multi-target regression method is proposed that tries to jointly address these challenges via a novel problem transformation approach. The proposed method, called MRQ, is based on the idea of quantizing the output space in order to transform the multiple continuous targets into one or more discrete ones. Learning on the transformed output space naturally enables modeling of target dependencies while the quantization strategy can be flexibly parameterized to control the trade-off between prediction accuracy and computational efficiency. Experiments on a large collection of benchmark datasets show that MRQ is both highly scalable and also competitive with the state-of-the-art in terms of accuracy. In particular, an ensemble version of MRQ obtains the best overall accuracy, while being an order of magnitude faster than the runner up method.
Design and implementation of an open source Greek POS Tagger and Entity Recognizer using spaCy
Dec 05, 2019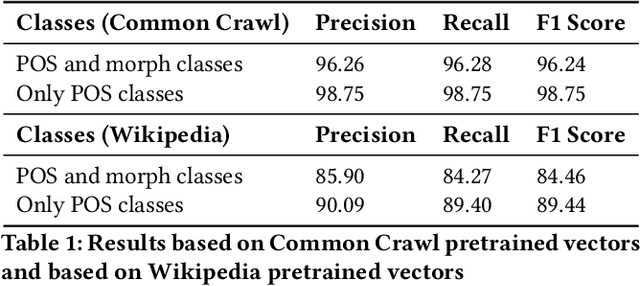

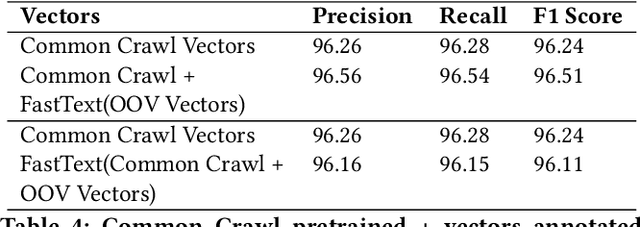

This paper proposes a machine learning approach to part-of-speech tagging and named entity recognition for Greek, focusing on the extraction of morphological features and classification of tokens into a small set of classes for named entities. The architecture model that was used is introduced. The greek version of the spaCy platform was added into the source code, a feature that did not exist before our contribution, and was used for building the models. Additionally, a part of speech tagger was trained that can detect the morphology of the tokens and performs higher than the state-of-the-art results when classifying only the part of speech. For named entity recognition using spaCy, a model that extends the standard ENAMEX type (organization, location, person) was built. Certain experiments that were conducted indicate the need for flexibility in out-of-vocabulary words and there is an effort for resolving this issue. Finally, the evaluation results are discussed.
Multi-Target Regression via Input Space Expansion: Treating Targets as Inputs
Jan 27, 2016
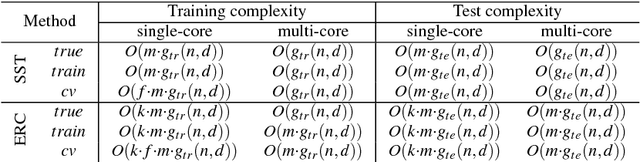


In many practical applications of supervised learning the task involves the prediction of multiple target variables from a common set of input variables. When the prediction targets are binary the task is called multi-label classification, while when the targets are continuous the task is called multi-target regression. In both tasks, target variables often exhibit statistical dependencies and exploiting them in order to improve predictive accuracy is a core challenge. A family of multi-label classification methods address this challenge by building a separate model for each target on an expanded input space where other targets are treated as additional input variables. Despite the success of these methods in the multi-label classification domain, their applicability and effectiveness in multi-target regression has not been studied until now. In this paper, we introduce two new methods for multi-target regression, called Stacked Single-Target and Ensemble of Regressor Chains, by adapting two popular multi-label classification methods of this family. Furthermore, we highlight an inherent problem of these methods - a discrepancy of the values of the additional input variables between training and prediction - and develop extensions that use out-of-sample estimates of the target variables during training in order to tackle this problem. The results of an extensive experimental evaluation carried out on a large and diverse collection of datasets show that, when the discrepancy is appropriately mitigated, the proposed methods attain consistent improvements over the independent regressions baseline. Moreover, two versions of Ensemble of Regression Chains perform significantly better than four state-of-the-art methods including regularization-based multi-task learning methods and a multi-objective random forest approach.
Multi-Target Regression via Random Linear Target Combinations
Apr 20, 2014



Multi-target regression is concerned with the simultaneous prediction of multiple continuous target variables based on the same set of input variables. It arises in several interesting industrial and environmental application domains, such as ecological modelling and energy forecasting. This paper presents an ensemble method for multi-target regression that constructs new target variables via random linear combinations of existing targets. We discuss the connection of our approach with multi-label classification algorithms, in particular RA$k$EL, which originally inspired this work, and a family of recent multi-label classification algorithms that involve output coding. Experimental results on 12 multi-target datasets show that it performs significantly better than a strong baseline that learns a single model for each target using gradient boosting and compares favourably to multi-objective random forest approach, which is a state-of-the-art approach. The experiments further show that our approach improves more when stronger unconditional dependencies exist among the targets.