 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDevNous: An LLM-Based Multi-Agent System for Grounding IT Project Management in Unstructured Conversation
Aug 12, 2025The manual translation of unstructured team dialogue into the structured artifacts required for Information Technology (IT) project governance is a critical bottleneck in modern information systems management. We introduce DevNous, a Large Language Model-based (LLM) multi-agent expert system, to automate this unstructured-to-structured translation process. DevNous integrates directly into team chat environments, identifying actionable intents from informal dialogue and managing stateful, multi-turn workflows for core administrative tasks like automated task formalization and progress summary synthesis. To quantitatively evaluate the system, we introduce a new benchmark of 160 realistic, interactive conversational turns. The dataset was manually annotated with a multi-label ground truth and is publicly available. On this benchmark, DevNous achieves an exact match turn accuracy of 81.3\% and a multiset F1-Score of 0.845, providing strong evidence for its viability. The primary contributions of this work are twofold: (1) a validated architectural pattern for developing ambient administrative agents, and (2) the introduction of the first robust empirical baseline and public benchmark dataset for this challenging problem domain.
Design and implementation of an open source Greek POS Tagger and Entity Recognizer using spaCy
Dec 05, 2019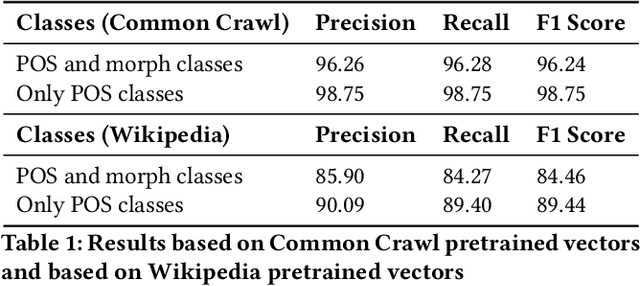

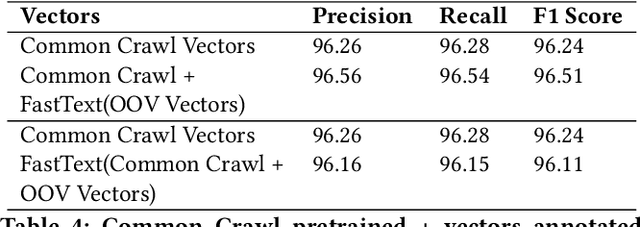

This paper proposes a machine learning approach to part-of-speech tagging and named entity recognition for Greek, focusing on the extraction of morphological features and classification of tokens into a small set of classes for named entities. The architecture model that was used is introduced. The greek version of the spaCy platform was added into the source code, a feature that did not exist before our contribution, and was used for building the models. Additionally, a part of speech tagger was trained that can detect the morphology of the tokens and performs higher than the state-of-the-art results when classifying only the part of speech. For named entity recognition using spaCy, a model that extends the standard ENAMEX type (organization, location, person) was built. Certain experiments that were conducted indicate the need for flexibility in out-of-vocabulary words and there is an effort for resolving this issue. Finally, the evaluation results are discussed.
Towards countering hate speech and personal attack in social media
Dec 05, 2019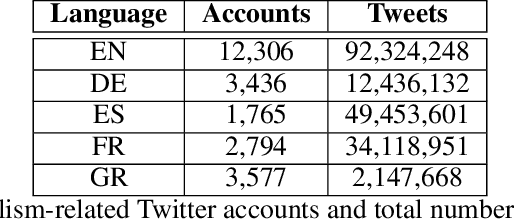
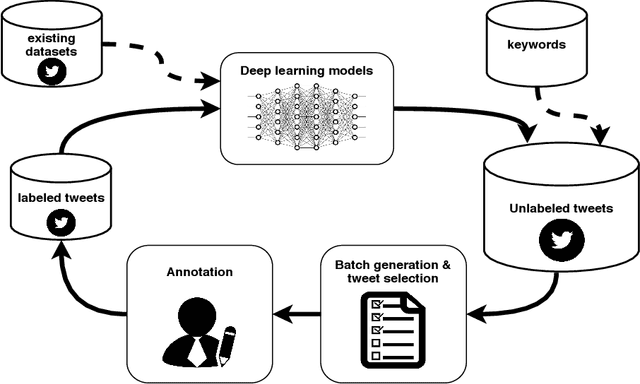
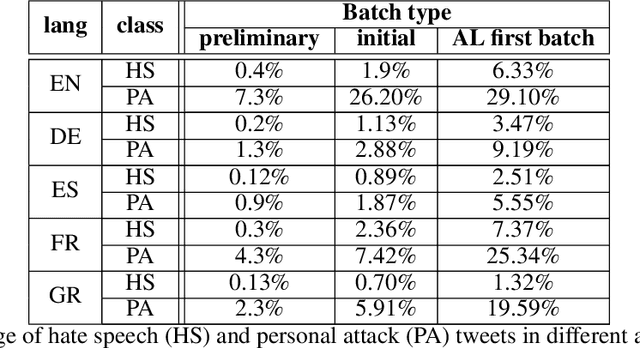
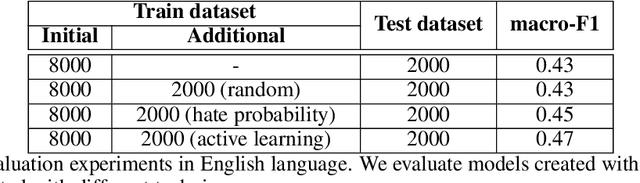
The damaging effects of hate speech in social media are evident during the last few years, and several organizations, researchers and the social media platforms themselves have tried to harness them without great success. Recently, following the advent of deep learning, several novel approaches appeared in the field of hate speech detection. However, it is apparent that such approaches depend on large-scale datasets in order to exhibit competitive performance. In this paper, we present a novel, publicly available collection of datasets in five different languages, that consists of tweets referring to journalism-related accounts, including high-quality human annotations for hate speech and personal attack. To build the datasets we follow a concise annotation strategy and employ an active learning approach. Additionally, we present a number of state-of-the-art deep learning architectures for hate speech detection and use these datasets to train and evaluate them. Finally, we propose an ensemble model that outperforms all individual models.