 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards countering hate speech and personal attack in social media
Paper and Code
Dec 05, 2019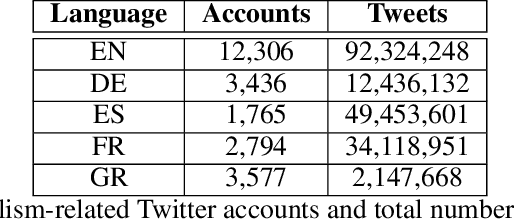
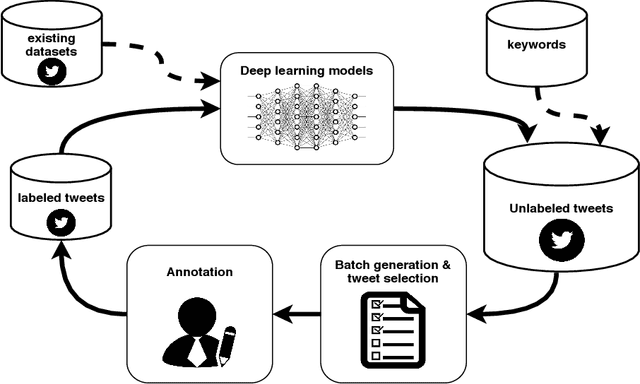
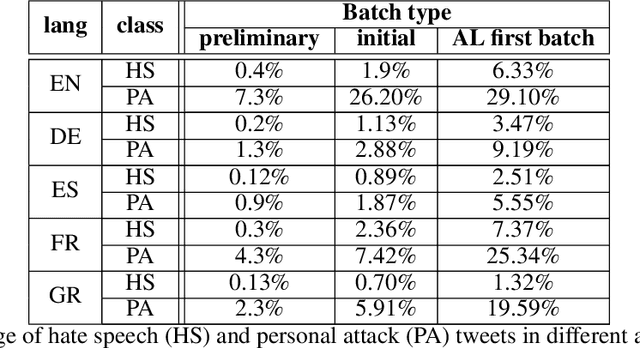
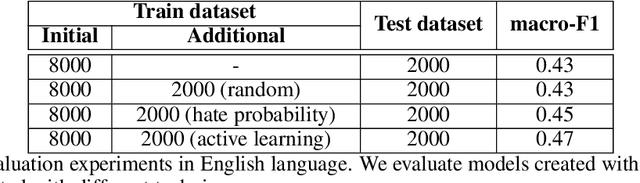
The damaging effects of hate speech in social media are evident during the last few years, and several organizations, researchers and the social media platforms themselves have tried to harness them without great success. Recently, following the advent of deep learning, several novel approaches appeared in the field of hate speech detection. However, it is apparent that such approaches depend on large-scale datasets in order to exhibit competitive performance. In this paper, we present a novel, publicly available collection of datasets in five different languages, that consists of tweets referring to journalism-related accounts, including high-quality human annotations for hate speech and personal attack. To build the datasets we follow a concise annotation strategy and employ an active learning approach. Additionally, we present a number of state-of-the-art deep learning architectures for hate speech detection and use these datasets to train and evaluate them. Finally, we propose an ensemble model that outperforms all individual models.