 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Multi-Stream Fusion Network for Image Splicing Localization
Dec 02, 2022



In this paper, we address the problem of image splicing localization with a multi-stream network architecture that processes the raw RGB image in parallel with other handcrafted forensic signals. Unlike previous methods that either use only the RGB images or stack several signals in a channel-wise manner, we propose an encoder-decoder architecture that consists of multiple encoder streams. Each stream is fed with either the tampered image or handcrafted signals and processes them separately to capture relevant information from each one independently. Finally, the extracted features from the multiple streams are fused in the bottleneck of the architecture and propagated to the decoder network that generates the output localization map. We experiment with two handcrafted algorithms, i.e., DCT and Splicebuster. Our proposed approach is benchmarked on three public forensics datasets, demonstrating competitive performance against several competing methods and achieving state-of-the-art results, e.g., 0.898 AUC on CASIA.
Operation-wise Attention Network for Tampering Localization Fusion
May 13, 2021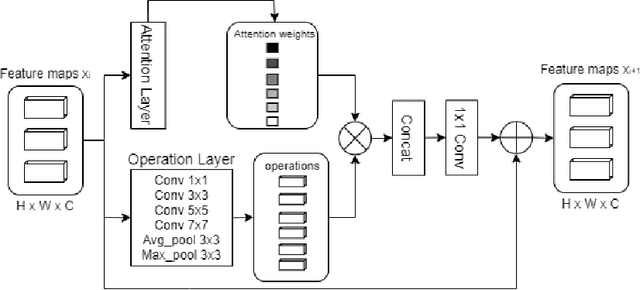
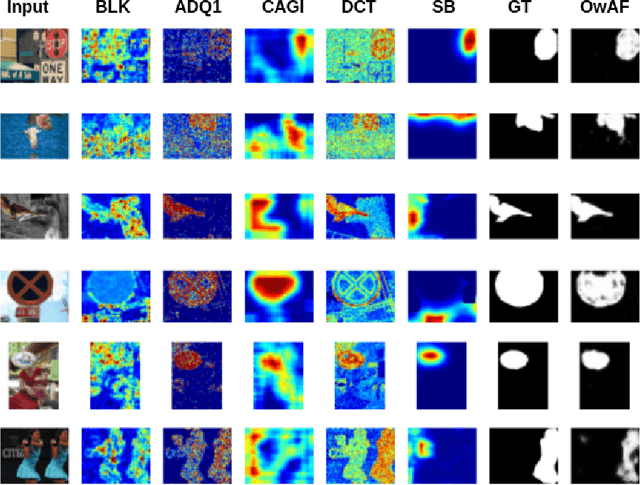

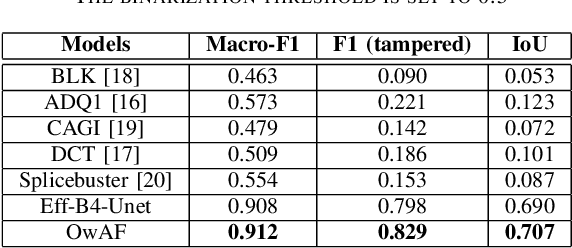
In this work, we present a deep learning-based approach for image tampering localization fusion. This approach is designed to combine the outcomes of multiple image forensics algorithms and provides a fused tampering localization map, which requires no expert knowledge and is easier to interpret by end users. Our fusion framework includes a set of five individual tampering localization methods for splicing localization on JPEG images. The proposed deep learning fusion model is an adapted architecture, initially proposed for the image restoration task, that performs multiple operations in parallel, weighted by an attention mechanism to enable the selection of proper operations depending on the input signals. This weighting process can be very beneficial for cases where the input signal is very diverse, as in our case where the output signals of multiple image forensics algorithms are combined. Evaluation in three publicly available forensics datasets demonstrates that the performance of the proposed approach is competitive, outperforming the individual forensics techniques as well as another recently proposed fusion framework in the majority of cases.
A Face Preprocessing Approach for Improved DeepFake Detection
Jun 12, 2020

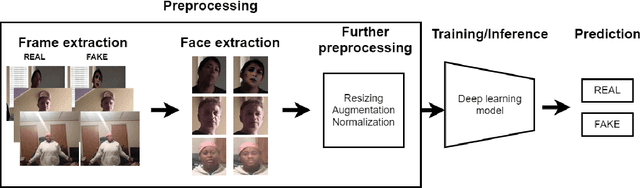

Recent advancements in content generation technologies (also widely known as DeepFakes) along with the online proliferation of manipulated media and disinformation campaigns render the detection of such manipulations a task of increasing importance. There are numerous works related to DeepFake detection but there is little focus on the impact of dataset preprocessing on the detection accuracy of the models. In this paper, we focus on this aspect of the DeepFake detection task and propose a preprocessing step to improve the quality of training datasets for the problem. We also examine its effects on the DeepFake detection performance. Experimental results demonstrate that the proposed preprocessing approach leads to measurable improvements in the performance of detection models.
Towards countering hate speech and personal attack in social media
Dec 05, 2019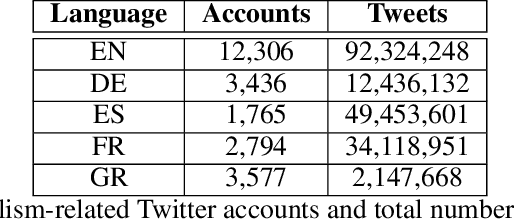
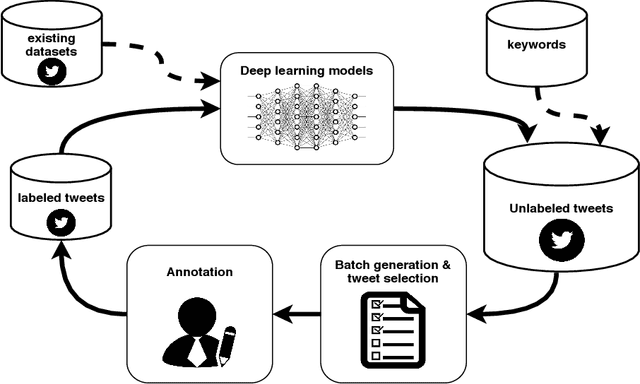
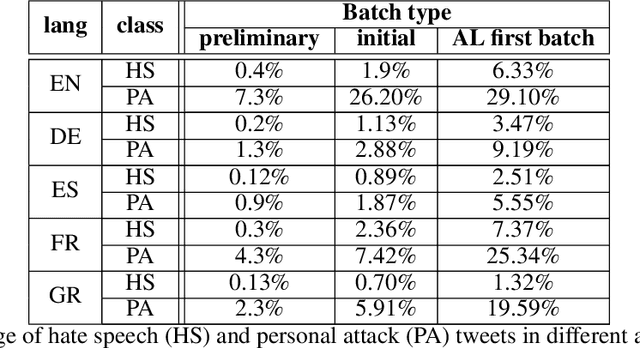
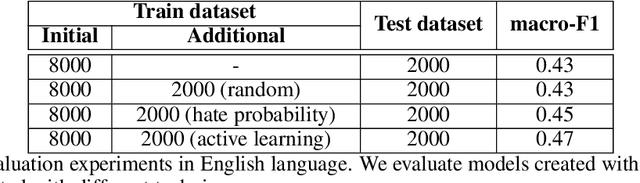
The damaging effects of hate speech in social media are evident during the last few years, and several organizations, researchers and the social media platforms themselves have tried to harness them without great success. Recently, following the advent of deep learning, several novel approaches appeared in the field of hate speech detection. However, it is apparent that such approaches depend on large-scale datasets in order to exhibit competitive performance. In this paper, we present a novel, publicly available collection of datasets in five different languages, that consists of tweets referring to journalism-related accounts, including high-quality human annotations for hate speech and personal attack. To build the datasets we follow a concise annotation strategy and employ an active learning approach. Additionally, we present a number of state-of-the-art deep learning architectures for hate speech detection and use these datasets to train and evaluate them. Finally, we propose an ensemble model that outperforms all individual models.