 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Face Preprocessing Approach for Improved DeepFake Detection
Paper and Code
Jun 12, 2020

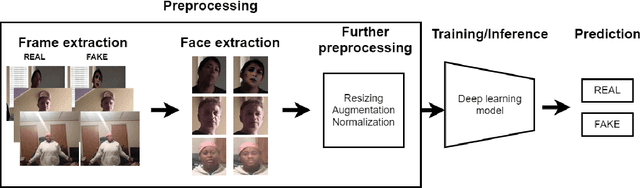

Recent advancements in content generation technologies (also widely known as DeepFakes) along with the online proliferation of manipulated media and disinformation campaigns render the detection of such manipulations a task of increasing importance. There are numerous works related to DeepFake detection but there is little focus on the impact of dataset preprocessing on the detection accuracy of the models. In this paper, we focus on this aspect of the DeepFake detection task and propose a preprocessing step to improve the quality of training datasets for the problem. We also examine its effects on the DeepFake detection performance. Experimental results demonstrate that the proposed preprocessing approach leads to measurable improvements in the performance of detection models.