 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Detection of Sub-events in Large Scale Disasters
Dec 13, 2019
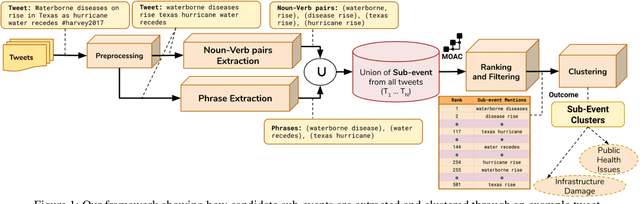
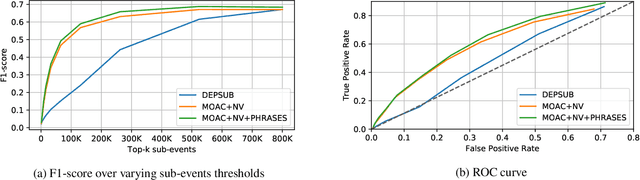

Social media plays a major role during and after major natural disasters (e.g., hurricanes, large-scale fires, etc.), as people ``on the ground'' post useful information on what is actually happening. Given the large amounts of posts, a major challenge is identifying the information that is useful and actionable. Emergency responders are largely interested in finding out what events are taking place so they can properly plan and deploy resources. In this paper we address the problem of automatically identifying important sub-events (within a large-scale emergency ``event'', such as a hurricane). In particular, we present a novel, unsupervised learning framework to detect sub-events in Tweets for retrospective crisis analysis. We first extract noun-verb pairs and phrases from raw tweets as sub-event candidates. Then, we learn a semantic embedding of extracted noun-verb pairs and phrases, and rank them against a crisis-specific ontology. We filter out noisy and irrelevant information then cluster the noun-verb pairs and phrases so that the top-ranked ones describe the most important sub-events. Through quantitative experiments on two large crisis data sets (Hurricane Harvey and the 2015 Nepal Earthquake), we demonstrate the effectiveness of our approach over the state-of-the-art. Our qualitative evaluation shows better performance compared to our baseline.
Learning Soft Linear Constraints with Application to Citation Field Extraction
Oct 17, 2014

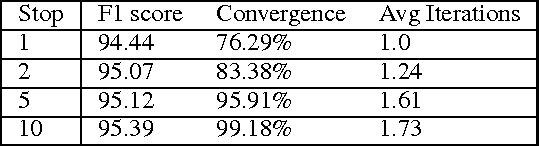
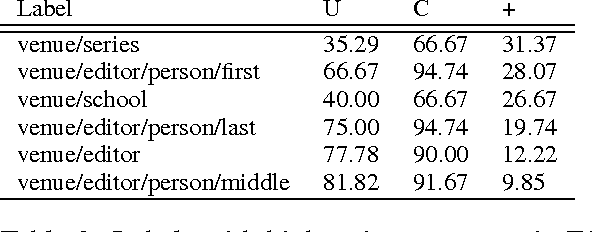
Accurately segmenting a citation string into fields for authors, titles, etc. is a challenging task because the output typically obeys various global constraints. Previous work has shown that modeling soft constraints, where the model is encouraged, but not require to obey the constraints, can substantially improve segmentation performance. On the other hand, for imposing hard constraints, dual decomposition is a popular technique for efficient prediction given existing algorithms for unconstrained inference. We extend the technique to perform prediction subject to soft constraints. Moreover, with a technique for performing inference given soft constraints, it is easy to automatically generate large families of constraints and learn their costs with a simple convex optimization problem during training. This allows us to obtain substantial gains in accuracy on a new, challenging citation extraction dataset.