 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Soft Linear Constraints with Application to Citation Field Extraction
Paper and Code
Oct 17, 2014

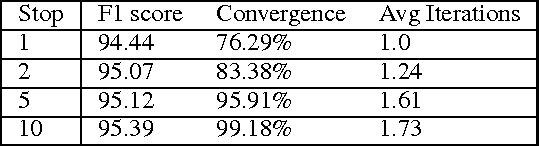
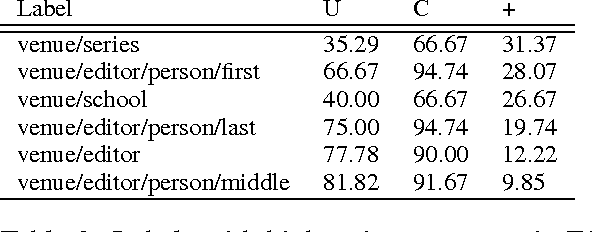
Accurately segmenting a citation string into fields for authors, titles, etc. is a challenging task because the output typically obeys various global constraints. Previous work has shown that modeling soft constraints, where the model is encouraged, but not require to obey the constraints, can substantially improve segmentation performance. On the other hand, for imposing hard constraints, dual decomposition is a popular technique for efficient prediction given existing algorithms for unconstrained inference. We extend the technique to perform prediction subject to soft constraints. Moreover, with a technique for performing inference given soft constraints, it is easy to automatically generate large families of constraints and learn their costs with a simple convex optimization problem during training. This allows us to obtain substantial gains in accuracy on a new, challenging citation extraction dataset.