 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA large scale study of SVM based methods for abstract screening in systematic reviews
Jan 16, 2018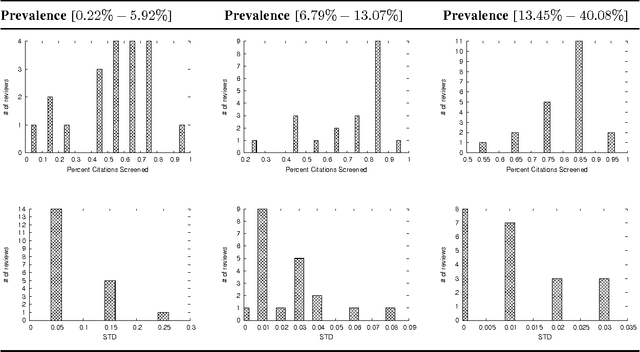
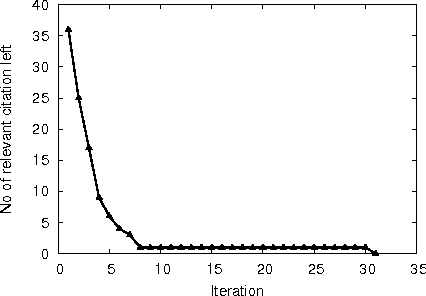


A major task in systematic reviews is abstract screening, i.e., excluding, often hundreds or thousand of, irrelevant citations returned from a database search based on titles and abstracts. Thus, a systematic review platform that can automate the abstract screening process is of huge importance. Several methods have been proposed for this task. However, it is very hard to clearly understand the applicability of these methods in a systematic review platform because of the following challenges: (1) the use of non-overlapping metrics for the evaluation of the proposed methods, (2) usage of features that are very hard to collect, (3) using a small set of reviews for the evaluation, and (4) no solid statistical testing or equivalence grouping of the methods. In this paper, we use feature representation that can be extracted per citation. We evaluate SVM-based methods (commonly used) on a large set of reviews ($61$) and metrics ($11$) to provide equivalence grouping of methods based on a solid statistical test. Our analysis also includes a strong variability of the metrics using $500$x$2$ cross validation. While some methods shine for different metrics and for different datasets, there is no single method that dominates the pack. Furthermore, we observe that in some cases relevant (included) citations can be found after screening only 15-20% of them via a certainty based sampling. A few included citations present outlying characteristics and can only be found after a very large number of screening steps. Finally, we present an ensemble algorithm for producing a $5$-star rating of citations based on their relevance. Such algorithm combines the best methods from our evaluation and through its $5$-star rating outputs a more easy-to-consume prediction.