 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpert Evaluation of LLM World Models: A High-$T_c$ Superconductivity Case Study
Nov 05, 2025Large Language Models (LLMs) show great promise as a powerful tool for scientific literature exploration. However, their effectiveness in providing scientifically accurate and comprehensive answers to complex questions within specialized domains remains an active area of research. Using the field of high-temperature cuprates as an exemplar, we evaluate the ability of LLM systems to understand the literature at the level of an expert. We construct an expert-curated database of 1,726 scientific papers that covers the history of the field, and a set of 67 expert-formulated questions that probe deep understanding of the literature. We then evaluate six different LLM-based systems for answering these questions, including both commercially available closed models and a custom retrieval-augmented generation (RAG) system capable of retrieving images alongside text. Experts then evaluate the answers of these systems against a rubric that assesses balanced perspectives, factual comprehensiveness, succinctness, and evidentiary support. Among the six systems two using RAG on curated literature outperformed existing closed models across key metrics, particularly in providing comprehensive and well-supported answers. We discuss promising aspects of LLM performances as well as critical short-comings of all the models. The set of expert-formulated questions and the rubric will be valuable for assessing expert level performance of LLM based reasoning systems.
Towards AI-assisted Academic Writing
Mar 17, 2025We present components of an AI-assisted academic writing system including citation recommendation and introduction writing. The system recommends citations by considering the user's current document context to provide relevant suggestions. It generates introductions in a structured fashion, situating the contributions of the research relative to prior work. We demonstrate the effectiveness of the components through quantitative evaluations. Finally, the paper presents qualitative research exploring how researchers incorporate citations into their writing workflows. Our findings indicate that there is demand for precise AI-assisted writing systems and simple, effective methods for meeting those needs.
Chronological Self-Training for Real-Time Speaker Diarization
Aug 05, 2022


Diarization partitions an audio stream into segments based on the voices of the speakers. Real-time diarization systems that include an enrollment step should limit enrollment training samples to reduce user interaction time. Although training on a small number of samples yields poor performance, we show that the accuracy can be improved dramatically using a chronological self-training approach. We studied the tradeoff between training time and classification performance and found that 1 second is sufficient to reach over 95% accuracy. We evaluated on 700 audio conversation files of about 10 minutes each from 6 different languages and demonstrated average diarization error rates as low as 10%.
* 5 pages, 5 figures, ICASSP 2021
Disfluency Detection with Unlabeled Data and Small BERT Models
Apr 21, 2021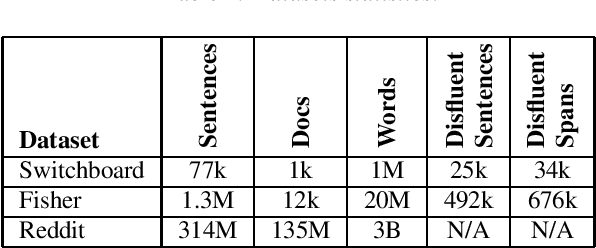
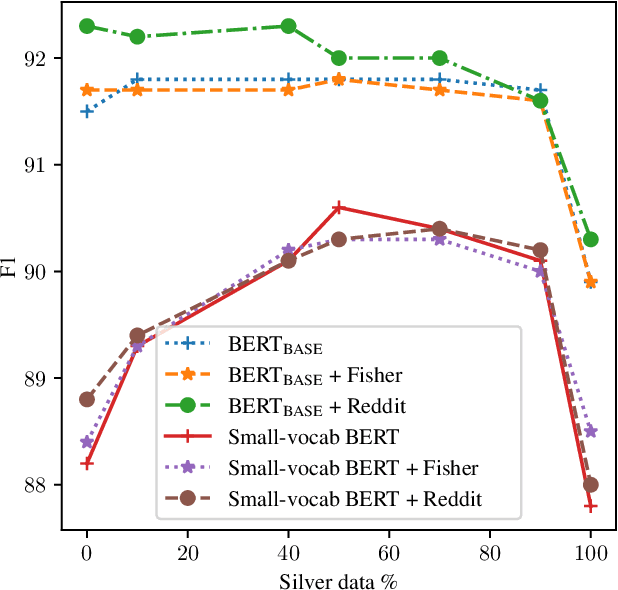
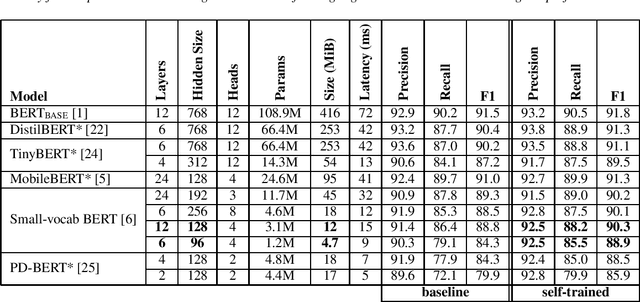
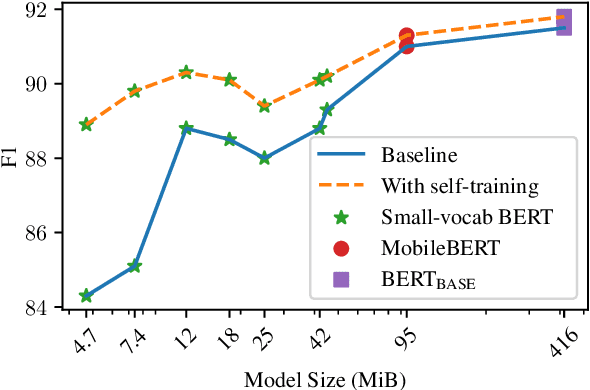
Disfluency detection models now approach high accuracy on English text. However, little exploration has been done in improving the size and inference time of the model. At the same time, automatic speech recognition (ASR) models are moving from server-side inference to local, on-device inference. Supporting models in the transcription pipeline (like disfluency detection) must follow suit. In this work we concentrate on the disfluency detection task, focusing on small, fast, on-device models based on the BERT architecture. We demonstrate it is possible to train disfluency detection models as small as 1.3 MiB, while retaining high performance. We build on previous work that showed the benefit of data augmentation approaches such as self-training. Then, we evaluate the effect of domain mismatch between conversational and written text on model performance. We find that domain adaptation and data augmentation strategies have a more pronounced effect on these smaller models, as compared to conventional BERT models.