 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiTurnCleanup: A Benchmark for Multi-Turn Spoken Conversational Transcript Cleanup
May 19, 2023Current disfluency detection models focus on individual utterances each from a single speaker. However, numerous discontinuity phenomena in spoken conversational transcripts occur across multiple turns, hampering human readability and the performance of downstream NLP tasks. This study addresses these phenomena by proposing an innovative Multi-Turn Cleanup task for spoken conversational transcripts and collecting a new dataset, MultiTurnCleanup1. We design a data labeling schema to collect the high-quality dataset and provide extensive data analysis. Furthermore, we leverage two modeling approaches for experimental evaluation as benchmarks for future research.
Disfluency Detection with Unlabeled Data and Small BERT Models
Apr 21, 2021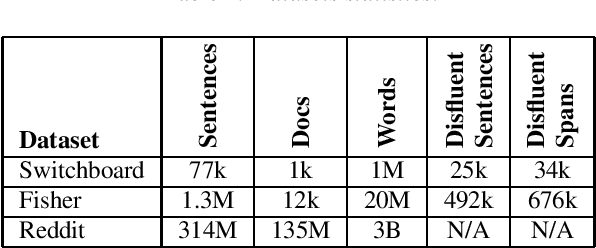
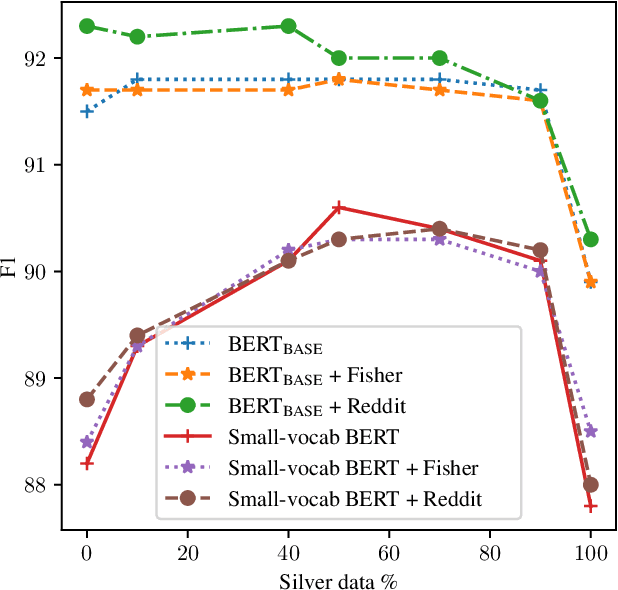
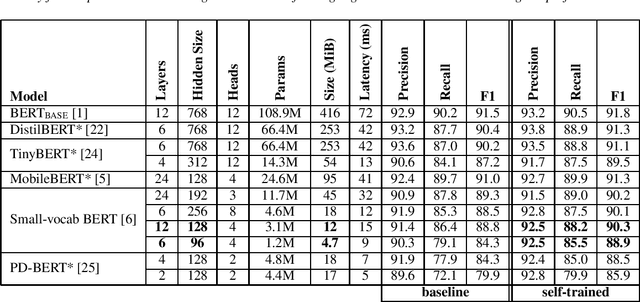
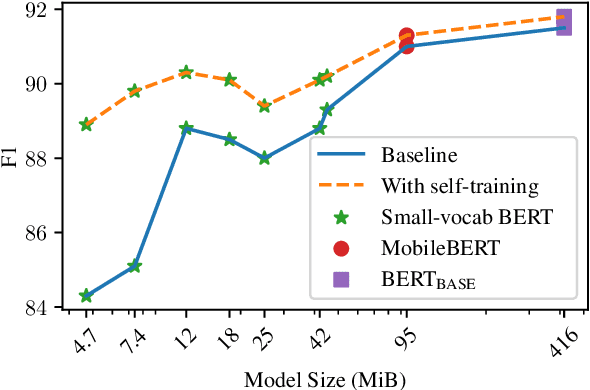
Disfluency detection models now approach high accuracy on English text. However, little exploration has been done in improving the size and inference time of the model. At the same time, automatic speech recognition (ASR) models are moving from server-side inference to local, on-device inference. Supporting models in the transcription pipeline (like disfluency detection) must follow suit. In this work we concentrate on the disfluency detection task, focusing on small, fast, on-device models based on the BERT architecture. We demonstrate it is possible to train disfluency detection models as small as 1.3 MiB, while retaining high performance. We build on previous work that showed the benefit of data augmentation approaches such as self-training. Then, we evaluate the effect of domain mismatch between conversational and written text on model performance. We find that domain adaptation and data augmentation strategies have a more pronounced effect on these smaller models, as compared to conventional BERT models.