 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssurance of AI Systems From a Dependability Perspective
Jul 18, 2024
We outline the principles of classical assurance for computer-based systems that pose significant risks. We then consider application of these principles to systems that employ Artificial Intelligence (AI) and Machine Learning (ML). A key element in this "dependability" perspective is a requirement to have near-complete understanding of the behavior of critical components, and this is considered infeasible for AI and ML. Hence the dependability perspective aims to minimize trust in AI and ML elements by using "defense in depth" with a hierarchy of less complex systems, some of which may be highly assured conventionally engineered components, to "guard" them. This may be contrasted with the "trustworthy" perspective that seeks to apply assurance to the AI and ML elements themselves. In cyber-physical and many other systems, it is difficult to provide guards that do not depend on AI and ML to perceive their environment (e.g., other vehicles sharing the road with a self-driving car), so both perspectives are needed and there is a continuum or spectrum between them. We focus on architectures toward the dependability end of the continuum and invite others to consider additional points along the spectrum. For guards that require perception using AI and ML, we examine ways to minimize the trust placed in these elements; they include diversity, defense in depth, explanations, and micro-ODDs. We also examine methods to enforce acceptable behavior, given a model of the world. These include classical cyber-physical calculations and envelopes, and normative rules based on overarching principles, constitutions, ethics, or reputation. We apply our perspective to autonomous systems, AI systems for specific functions, generic AI such as Large Language Models, and to Artificial General Intelligence (AGI), and we propose current best practice and an agenda for research.
The Misclassification Likelihood Matrix: Some Classes Are More Likely To Be Misclassified Than Others
Jul 10, 2024



This study introduces the Misclassification Likelihood Matrix (MLM) as a novel tool for quantifying the reliability of neural network predictions under distribution shifts. The MLM is obtained by leveraging softmax outputs and clustering techniques to measure the distances between the predictions of a trained neural network and class centroids. By analyzing these distances, the MLM provides a comprehensive view of the model's misclassification tendencies, enabling decision-makers to identify the most common and critical sources of errors. The MLM allows for the prioritization of model improvements and the establishment of decision thresholds based on acceptable risk levels. The approach is evaluated on the MNIST dataset using a Convolutional Neural Network (CNN) and a perturbed version of the dataset to simulate distribution shifts. The results demonstrate the effectiveness of the MLM in assessing the reliability of predictions and highlight its potential in enhancing the interpretability and risk mitigation capabilities of neural networks. The implications of this work extend beyond image classification, with ongoing applications in autonomous systems, such as self-driving cars, to improve the safety and reliability of decision-making in complex, real-world environments.
When to Accept Automated Predictions and When to Defer to Human Judgment?
Jul 10, 2024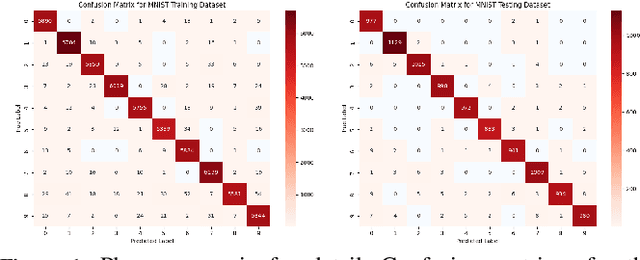
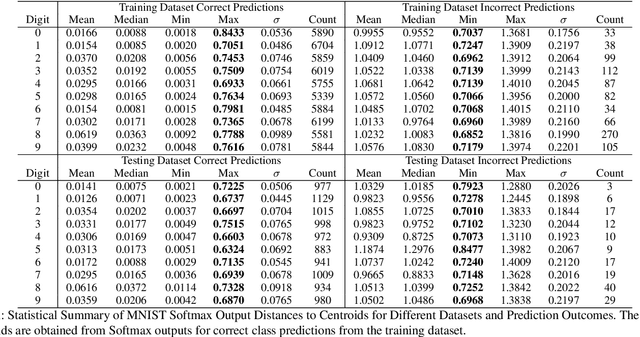
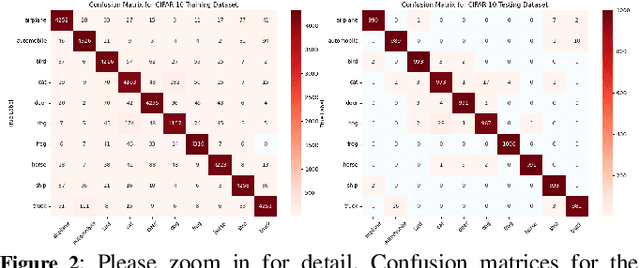
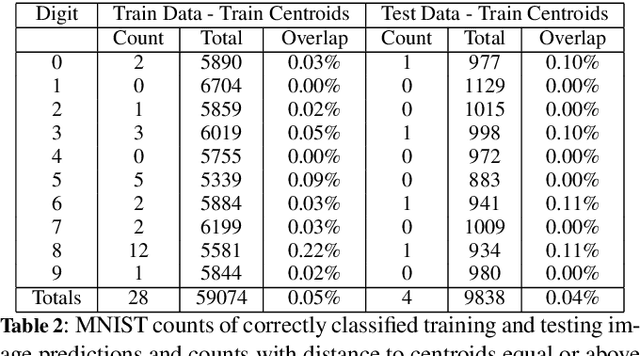
Ensuring the reliability and safety of automated decision-making is crucial. It is well-known that data distribution shifts in machine learning can produce unreliable outcomes. This paper proposes a new approach for measuring the reliability of predictions under distribution shifts. We analyze how the outputs of a trained neural network change using clustering to measure distances between outputs and class centroids. We propose this distance as a metric to evaluate the confidence of predictions under distribution shifts. We assign each prediction to a cluster with centroid representing the mean softmax output for all correct predictions of a given class. We then define a safety threshold for a class as the smallest distance from an incorrect prediction to the given class centroid. We evaluate the approach on the MNIST and CIFAR-10 datasets using a Convolutional Neural Network and a Vision Transformer, respectively. The results show that our approach is consistent across these data sets and network models, and indicate that the proposed metric can offer an efficient way of determining when automated predictions are acceptable and when they should be deferred to human operators given a distribution shift.
Assessing Confidence with Assurance 2.0
May 03, 2022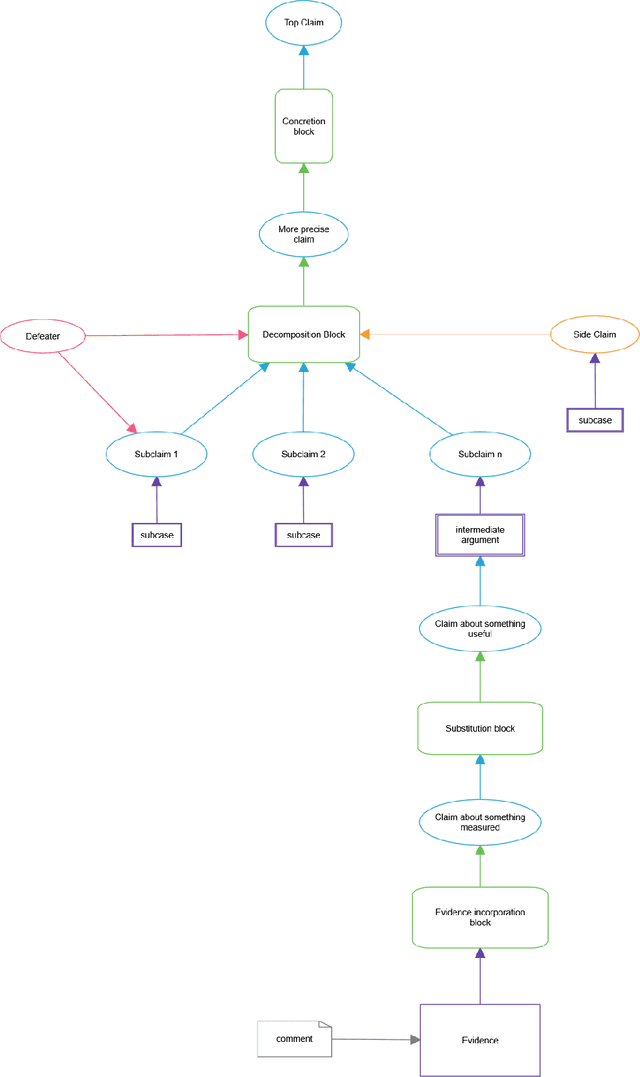
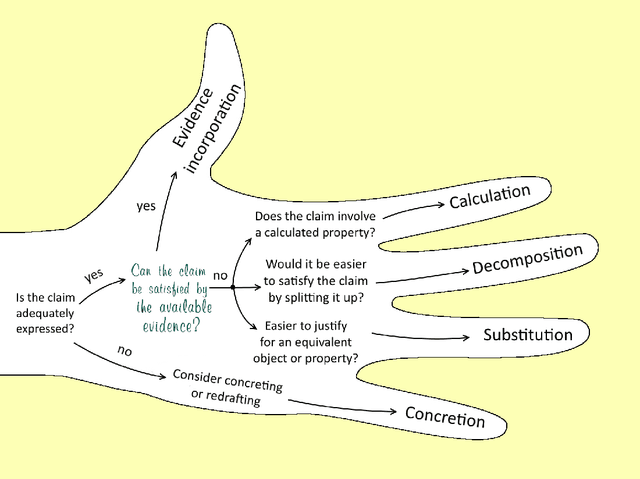
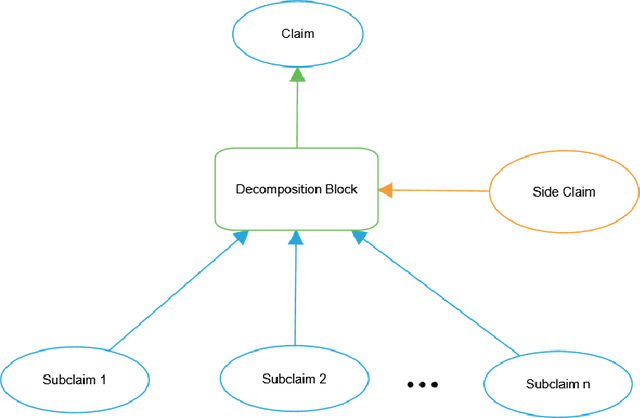
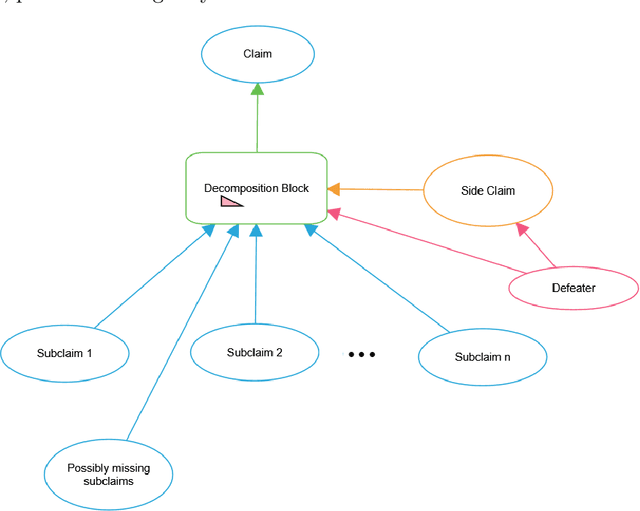
An assurance case is intended to provide justifiable confidence in the truth of its top claim, which typically concerns safety or security. A natural question is then "how much" confidence does the case provide? We argue that confidence cannot be reduced to a single attribute or measurement. Instead, we suggest it should be based on attributes that draw on three different perspectives: positive, negative, and residual doubts. Positive Perspectives consider the extent to which the evidence and overall argument of the case combine to make a positive statement justifying belief in its claims. We set a high bar for justification, requiring it to be indefeasible. The primary positive measure for this is soundness, which interprets the argument as a logical proof. Confidence in evidence can be expressed probabilistically and we use confirmation measures to ensure that the "weight" of evidence crosses some threshold. In addition, probabilities can be aggregated from evidence through the steps of the argument using probability logics to yield what we call probabilistic valuations for the claims. Negative Perspectives record doubts and challenges to the case, typically expressed as defeaters, and their exploration and resolution. Assurance developers must guard against confirmation bias and should vigorously explore potential defeaters as they develop the case, and should record them and their resolution to avoid rework and to aid reviewers. Residual Doubts: the world is uncertain so not all potential defeaters can be resolved. We explore risks and may deem them acceptable or unavoidable. It is crucial however that these judgments are conscious ones and that they are recorded in the assurance case. This report examines the perspectives in detail and indicates how Clarissa, our prototype toolset for Assurance 2.0, assists in their evaluation.
Safety Case Templates for Autonomous Systems
Jan 29, 2021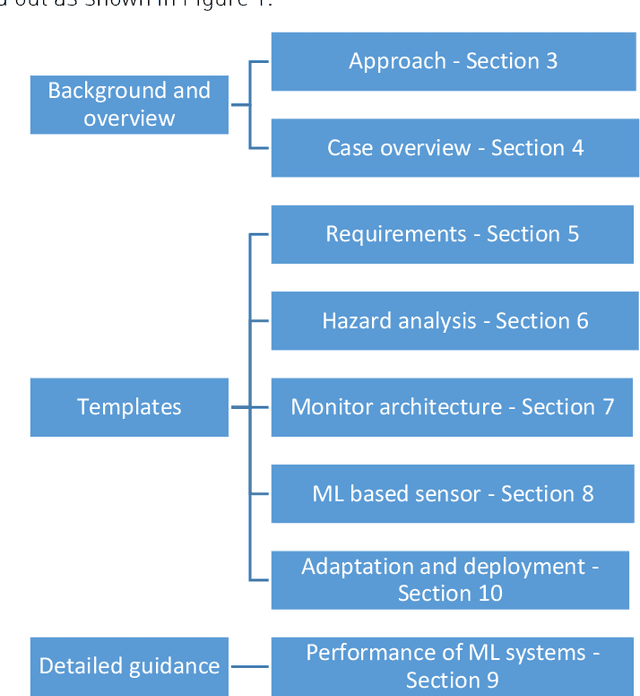
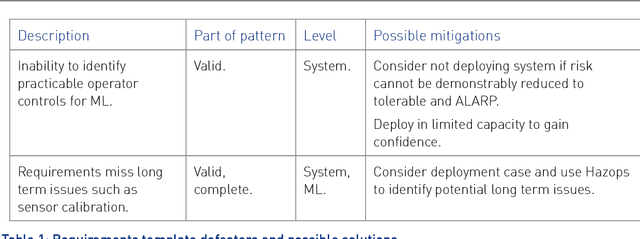
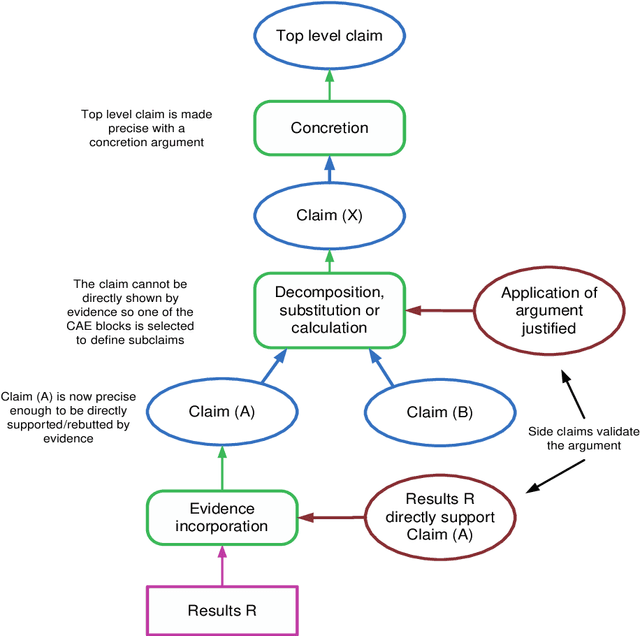

This report documents safety assurance argument templates to support the deployment and operation of autonomous systems that include machine learning (ML) components. The document presents example safety argument templates covering: the development of safety requirements, hazard analysis, a safety monitor architecture for an autonomous system including at least one ML element, a component with ML and the adaptation and change of the system over time. The report also presents generic templates for argument defeaters and evidence confidence that can be used to strengthen, review, and adapt the templates as necessary. This Interim Report is made available to get feedback on the approach and on the templates. This work is being sponsored by the UK Dstl under the R-cloud framework.
Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS -- a collection of Technical Notes Part 2
Feb 28, 2020
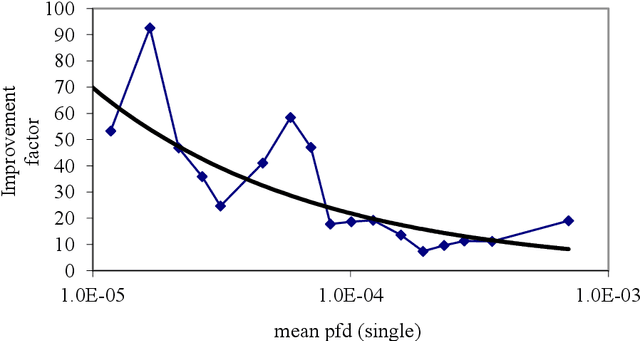

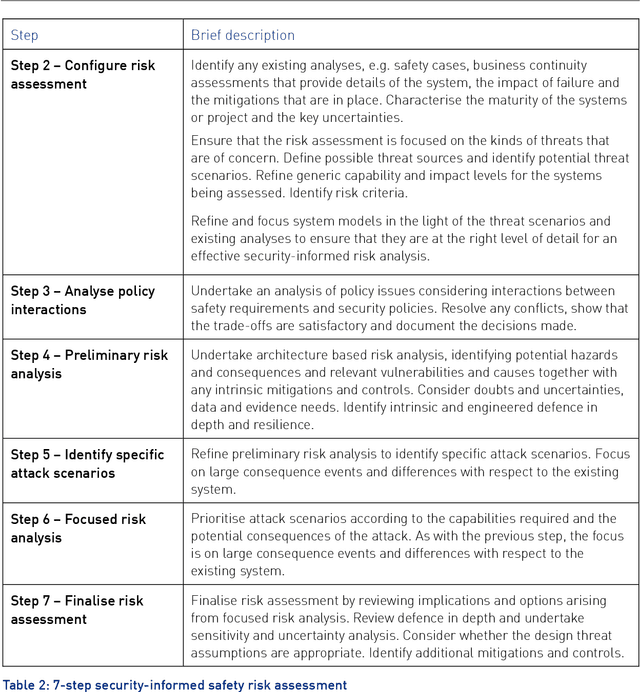
This report provides an introduction and overview of the Technical Topic Notes (TTNs) produced in the Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS (Tigars) project. These notes aim to support the development and evaluation of autonomous vehicles. Part 1 addresses: Assurance-overview and issues, Resilience and Safety Requirements, Open Systems Perspective and Formal Verification and Static Analysis of ML Systems. This report is Part 2 and discusses: Simulation and Dynamic Testing, Defence in Depth and Diversity, Security-Informed Safety Analysis, Standards and Guidelines.
Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS -- a collection of Technical Notes Part 1
Feb 28, 2020This report provides an introduction and overview of the Technical Topic Notes (TTNs) produced in the Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS (Tigars) project. These notes aim to support the development and evaluation of autonomous vehicles. Part 1 addresses: Assurance-overview and issues, Resilience and Safety Requirements, Open Systems Perspective and Formal Verification and Static Analysis of ML Systems. Part 2: Simulation and Dynamic Testing, Defence in Depth and Diversity, Security-Informed Safety Analysis, Standards and Guidelines.