 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hazard Analysis Framework for Code Synthesis Large Language Models
Jul 25, 2022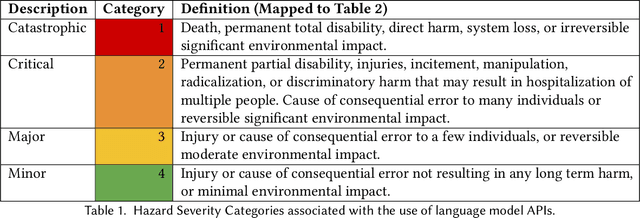
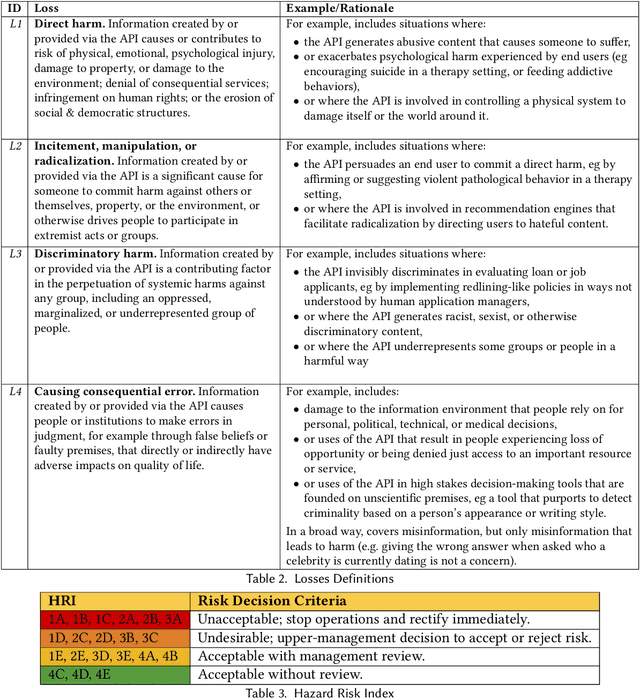
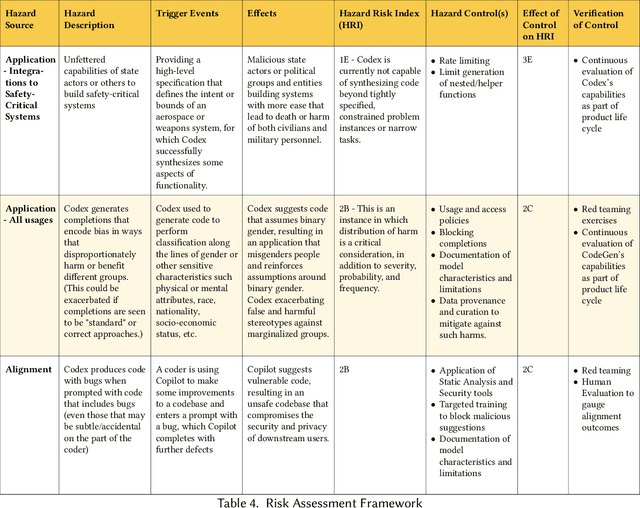
Codex, a large language model (LLM) trained on a variety of codebases, exceeds the previous state of the art in its capacity to synthesize and generate code. Although Codex provides a plethora of benefits, models that may generate code on such scale have significant limitations, alignment problems, the potential to be misused, and the possibility to increase the rate of progress in technical fields that may themselves have destabilizing impacts or have misuse potential. Yet such safety impacts are not yet known or remain to be explored. In this paper, we outline a hazard analysis framework constructed at OpenAI to uncover hazards or safety risks that the deployment of models like Codex may impose technically, socially, politically, and economically. The analysis is informed by a novel evaluation framework that determines the capacity of advanced code generation techniques against the complexity and expressivity of specification prompts, and their capability to understand and execute them relative to human ability.
Evaluating Large Language Models Trained on Code
Jul 14, 2021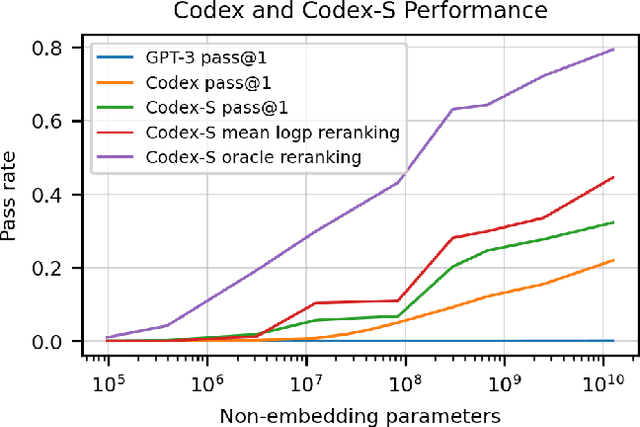
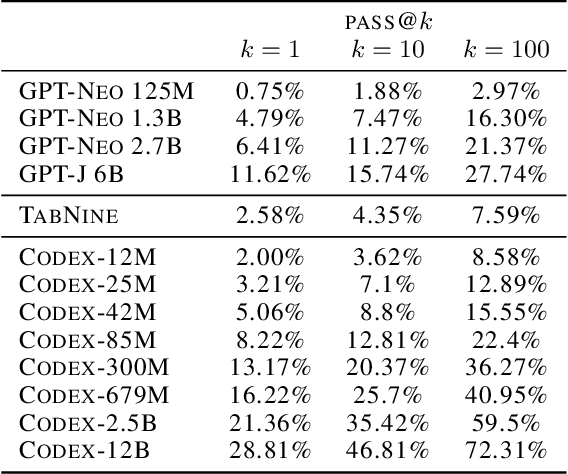
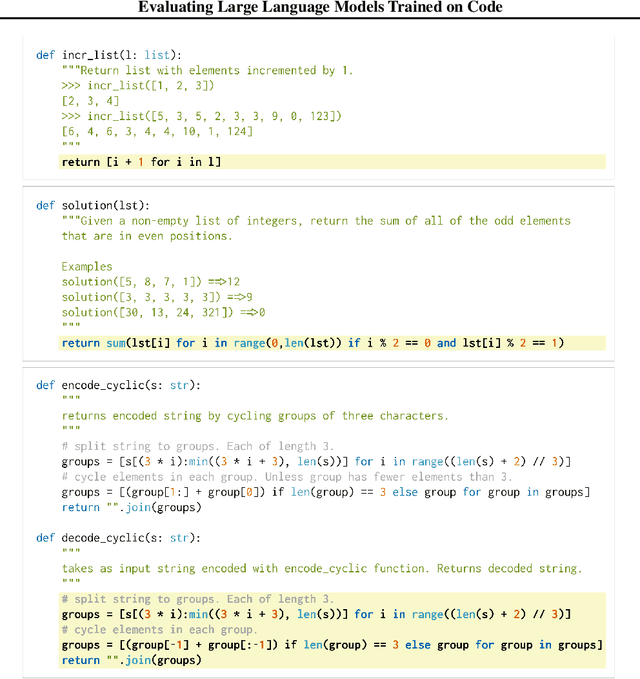
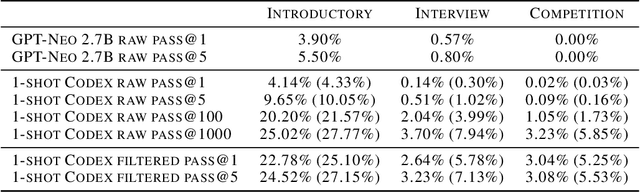
We introduce Codex, a GPT language model fine-tuned on publicly available code from GitHub, and study its Python code-writing capabilities. A distinct production version of Codex powers GitHub Copilot. On HumanEval, a new evaluation set we release to measure functional correctness for synthesizing programs from docstrings, our model solves 28.8% of the problems, while GPT-3 solves 0% and GPT-J solves 11.4%. Furthermore, we find that repeated sampling from the model is a surprisingly effective strategy for producing working solutions to difficult prompts. Using this method, we solve 70.2% of our problems with 100 samples per problem. Careful investigation of our model reveals its limitations, including difficulty with docstrings describing long chains of operations and with binding operations to variables. Finally, we discuss the potential broader impacts of deploying powerful code generation technologies, covering safety, security, and economics.
Safety Case Templates for Autonomous Systems
Jan 29, 2021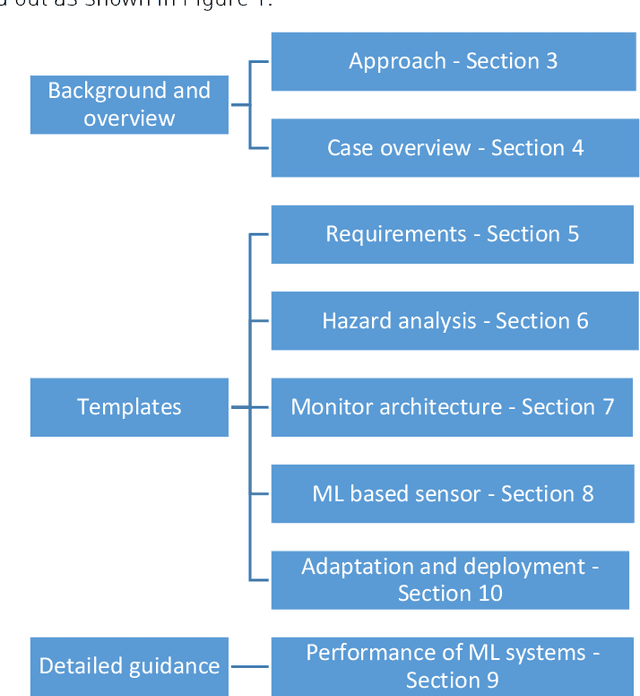
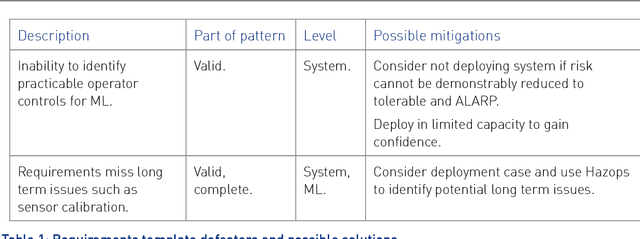
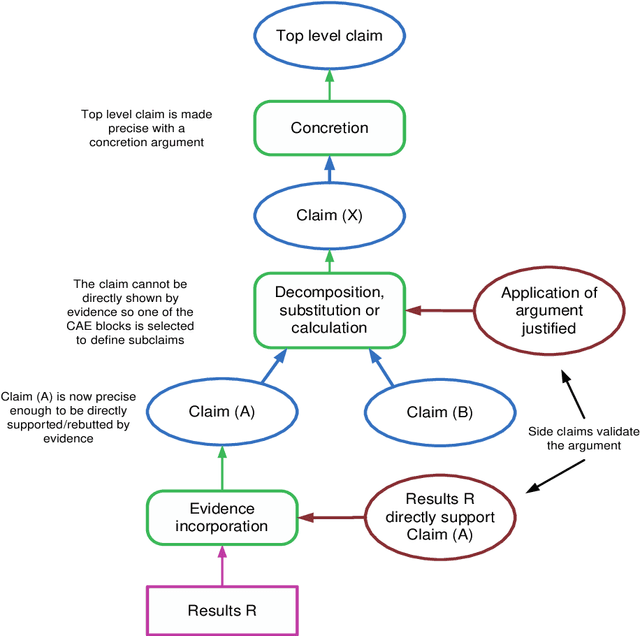

This report documents safety assurance argument templates to support the deployment and operation of autonomous systems that include machine learning (ML) components. The document presents example safety argument templates covering: the development of safety requirements, hazard analysis, a safety monitor architecture for an autonomous system including at least one ML element, a component with ML and the adaptation and change of the system over time. The report also presents generic templates for argument defeaters and evidence confidence that can be used to strengthen, review, and adapt the templates as necessary. This Interim Report is made available to get feedback on the approach and on the templates. This work is being sponsored by the UK Dstl under the R-cloud framework.
Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS -- a collection of Technical Notes Part 2
Feb 28, 2020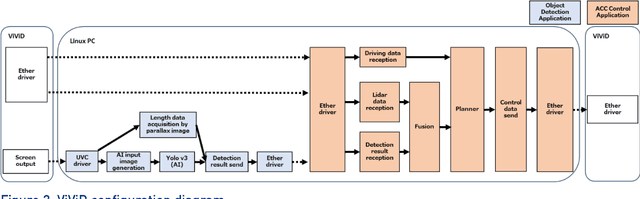
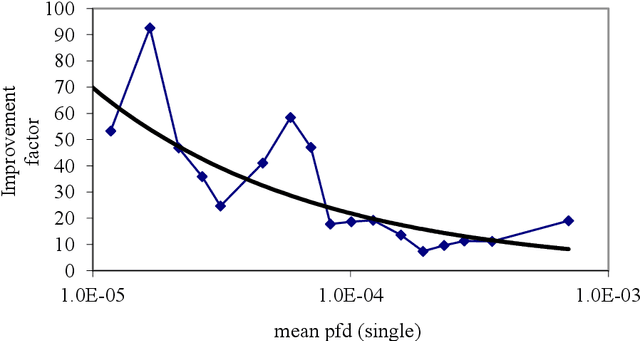

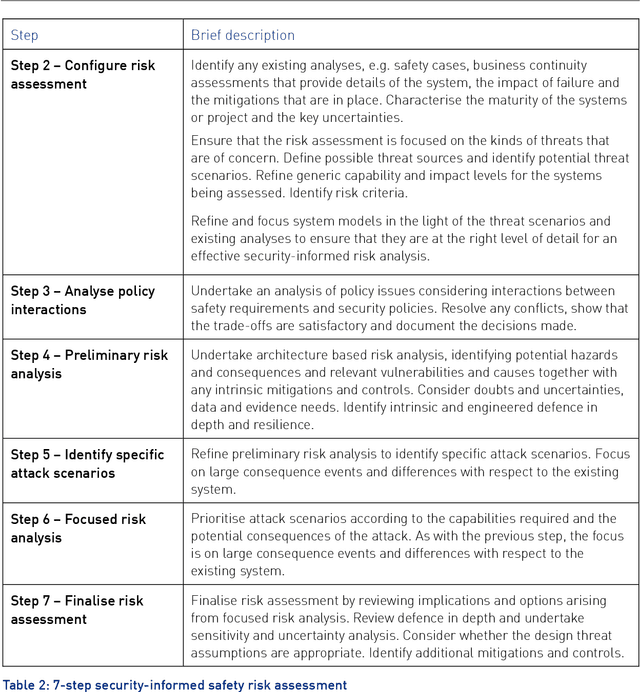
This report provides an introduction and overview of the Technical Topic Notes (TTNs) produced in the Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS (Tigars) project. These notes aim to support the development and evaluation of autonomous vehicles. Part 1 addresses: Assurance-overview and issues, Resilience and Safety Requirements, Open Systems Perspective and Formal Verification and Static Analysis of ML Systems. This report is Part 2 and discusses: Simulation and Dynamic Testing, Defence in Depth and Diversity, Security-Informed Safety Analysis, Standards and Guidelines.
Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS -- a collection of Technical Notes Part 1
Feb 28, 2020This report provides an introduction and overview of the Technical Topic Notes (TTNs) produced in the Towards Identifying and closing Gaps in Assurance of autonomous Road vehicleS (Tigars) project. These notes aim to support the development and evaluation of autonomous vehicles. Part 1 addresses: Assurance-overview and issues, Resilience and Safety Requirements, Open Systems Perspective and Formal Verification and Static Analysis of ML Systems. Part 2: Simulation and Dynamic Testing, Defence in Depth and Diversity, Security-Informed Safety Analysis, Standards and Guidelines.