 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Study of Conformal Prediction in LLM with ASP Scaffolds for Robust Reasoning
Mar 07, 2025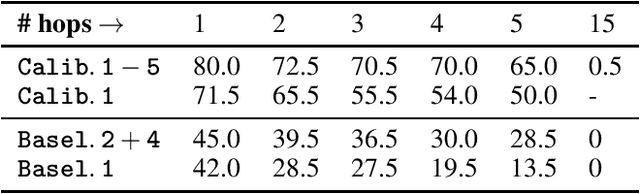

In this paper, we examine the use of Conformal Language Modelling (CLM) alongside Answer Set Programming (ASP) to enhance the performance of standard open-weight LLMs on complex multi-step reasoning tasks. Using the StepGame dataset, which requires spatial reasoning, we apply CLM to generate sets of ASP programs from an LLM, providing statistical guarantees on the correctness of the outputs. Experimental results show that CLM significantly outperforms baseline models that use standard sampling methods, achieving substantial accuracy improvements across different levels of reasoning complexity. Additionally, the LLM-as-Judge metric enhances CLM's performance, especially in assessing structurally and logically correct ASP outputs. However, calibrating CLM with diverse calibration sets did not improve generalizability for tasks requiring much longer reasoning steps, indicating limitations in handling more complex tasks.
Can Large Language Models Reason about the Region Connection Calculus?
Nov 29, 2024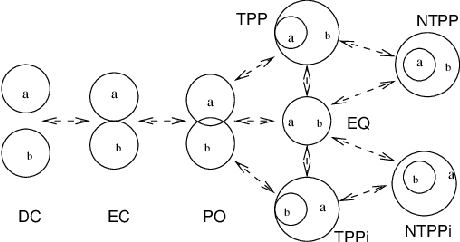

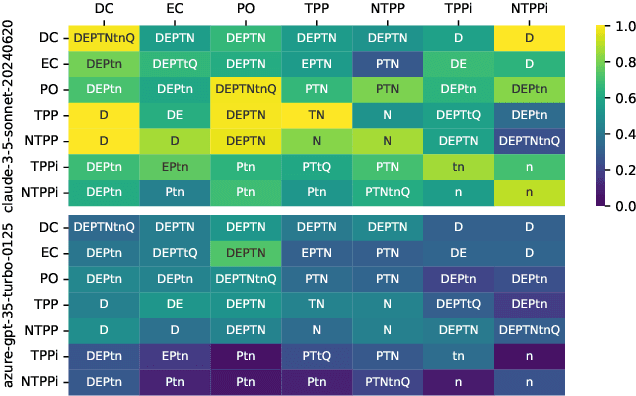
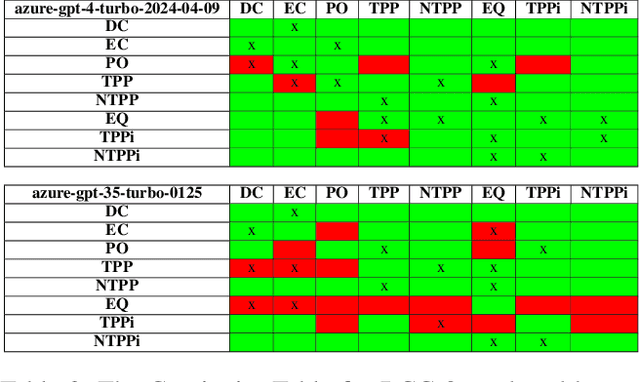
Qualitative Spatial Reasoning is a well explored area of Knowledge Representation and Reasoning and has multiple applications ranging from Geographical Information Systems to Robotics and Computer Vision. Recently, many claims have been made for the reasoning capabilities of Large Language Models (LLMs). Here, we investigate the extent to which a set of representative LLMs can perform classical qualitative spatial reasoning tasks on the mereotopological Region Connection Calculus, RCC-8. We conduct three pairs of experiments (reconstruction of composition tables, alignment to human composition preferences, conceptual neighbourhood reconstruction) using state-of-the-art LLMs; in each pair one experiment uses eponymous relations and one, anonymous relations (to test the extent to which the LLM relies on knowledge about the relation names obtained during training). All instances are repeated 30 times to measure the stochasticity of the LLMs.
Evaluating the Ability of Large Language Models to Reason about Cardinal Directions
Jun 24, 2024
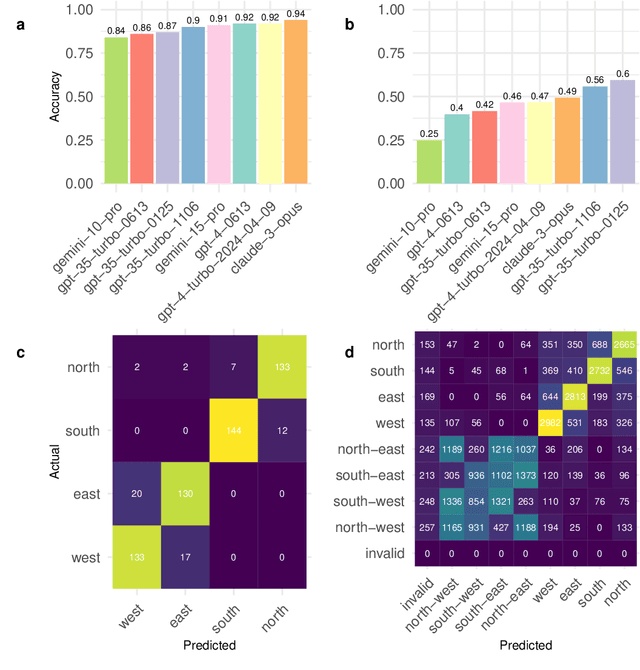
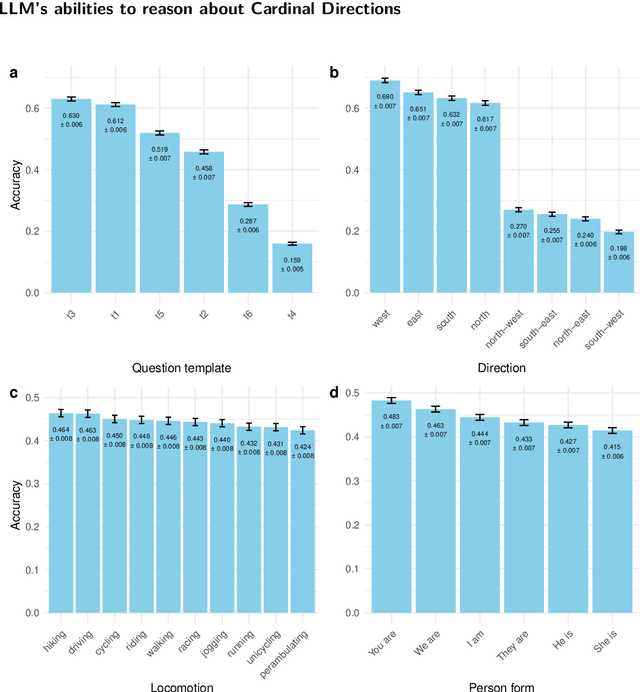
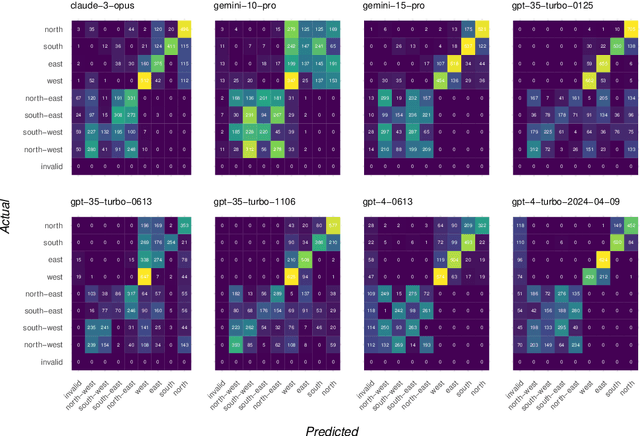
We investigate the abilities of a representative set of Large language Models (LLMs) to reason about cardinal directions (CDs). To do so, we create two datasets: the first, co-created with ChatGPT, focuses largely on recall of world knowledge about CDs; the second is generated from a set of templates, comprehensively testing an LLM's ability to determine the correct CD given a particular scenario. The templates allow for a number of degrees of variation such as means of locomotion of the agent involved, and whether set in the first , second or third person. Even with a temperature setting of zero, Our experiments show that although LLMs are able to perform well in the simpler dataset, in the second more complex dataset no LLM is able to reliably determine the correct CD, even with a temperature setting of zero.
An Evaluation of ChatGPT-4's Qualitative Spatial Reasoning Capabilities in RCC-8
Sep 27, 2023Qualitative Spatial Reasoning (QSR) is well explored area of Commonsense Reasoning and has multiple applications ranging from Geographical Information Systems to Robotics and Computer Vision. Recently many claims have been made for the capabilities of Large Language Models (LLMs). In this paper we investigate the extent to which one particular LLM can perform classical qualitative spatial reasoning tasks on the mereotopological calculus, RCC-8.
Dialectical language model evaluation: An initial appraisal of the commonsense spatial reasoning abilities of LLMs
Apr 22, 2023
Language models have become very popular recently and many claims have been made about their abilities, including for commonsense reasoning. Given the increasingly better results of current language models on previous static benchmarks for commonsense reasoning, we explore an alternative dialectical evaluation. The goal of this kind of evaluation is not to obtain an aggregate performance value but to find failures and map the boundaries of the system. Dialoguing with the system gives the opportunity to check for consistency and get more reassurance of these boundaries beyond anecdotal evidence. In this paper we conduct some qualitative investigations of this kind of evaluation for the particular case of spatial reasoning (which is a fundamental aspect of commonsense reasoning). We conclude with some suggestions for future work both to improve the capabilities of language models and to systematise this kind of dialectical evaluation.