 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvidence of Human-Like Visual-Linguistic Integration in Multimodal Large Language Models During Predictive Language Processing
Aug 11, 2023The advanced language processing abilities of large language models (LLMs) have stimulated debate over their capacity to replicate human-like cognitive processes. One differentiating factor between language processing in LLMs and humans is that language input is often grounded in more than one perceptual modality, whereas most LLMs process solely text-based information. Multimodal grounding allows humans to integrate - e.g. visual context with linguistic information and thereby place constraints on the space of upcoming words, reducing cognitive load and improving perception and comprehension. Recent multimodal LLMs (mLLMs) combine visual and linguistic embedding spaces with a transformer type attention mechanism for next-word prediction. To what extent does predictive language processing based on multimodal input align in mLLMs and humans? To answer this question, 200 human participants watched short audio-visual clips and estimated the predictability of an upcoming verb or noun. The same clips were processed by the mLLM CLIP, with predictability scores based on a comparison of image and text feature vectors. Eye-tracking was used to estimate what visual features participants attended to, and CLIP's visual attention weights were recorded. We find that human estimates of predictability align significantly with CLIP scores, but not for a unimodal LLM of comparable parameter size. Further, alignment vanished when CLIP's visual attention weights were perturbed, and when the same input was fed to a multimodal model without attention. Analysing attention patterns, we find a significant spatial overlap between CLIP's visual attention weights and human eye-tracking data. Results suggest that comparable processes of integrating multimodal information, guided by attention to relevant visual features, supports predictive language processing in mLLMs and humans.
Are words equally surprising in audio and audio-visual comprehension?
Jul 14, 2023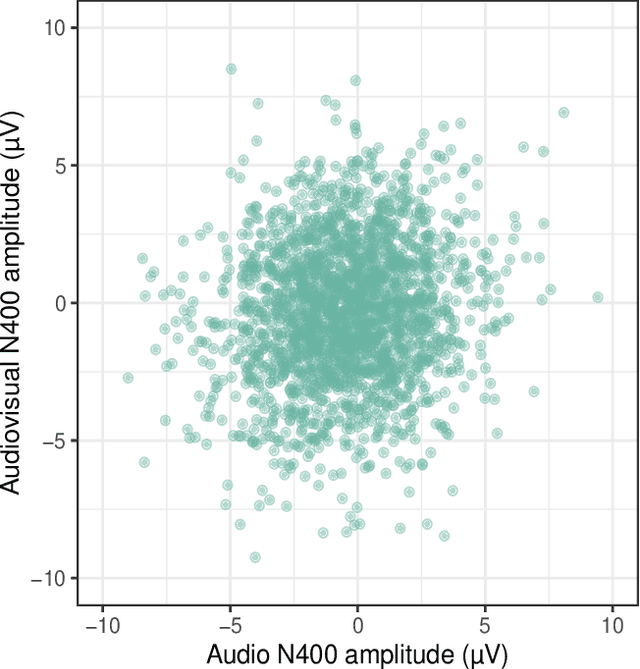
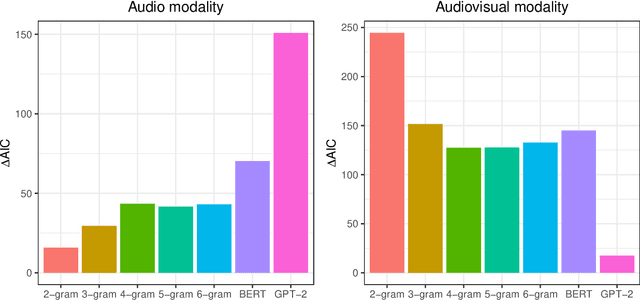
We report a controlled study investigating the effect of visual information (i.e., seeing the speaker) on spoken language comprehension. We compare the ERP signature (N400) associated with each word in audio-only and audio-visual presentations of the same verbal stimuli. We assess the extent to which surprisal measures (which quantify the predictability of words in their lexical context) are generated on the basis of different types of language models (specifically n-gram and Transformer models) that predict N400 responses for each word. Our results indicate that cognitive effort differs significantly between multimodal and unimodal settings. In addition, our findings suggest that while Transformer-based models, which have access to a larger lexical context, provide a better fit in the audio-only setting, 2-gram language models are more effective in the multimodal setting. This highlights the significant impact of local lexical context on cognitive processing in a multimodal environment.