 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRapid Parameter Inference with Uncertainty Quantification for a Radiological Plume Source Identification Problem
Feb 20, 2025


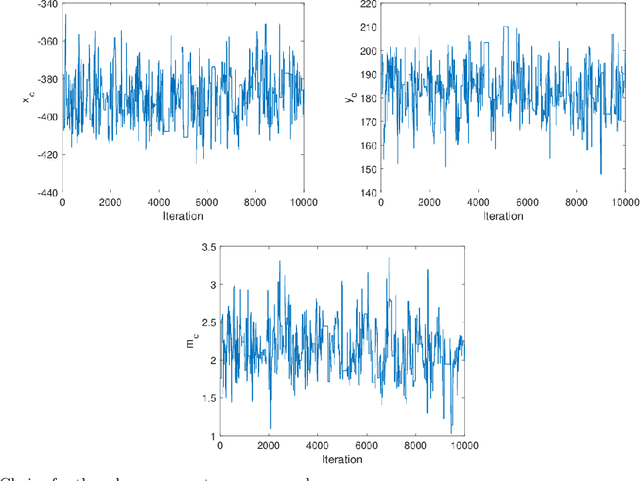
In the event of a nuclear accident, or the detonation of a radiological dispersal device, quickly locating the source of the accident or blast is important for emergency response and environmental decontamination. At a specified time after a simulated instantaneous release of an aerosolized radioactive contaminant, measurements are recorded downwind from an array of radiation sensors. Neural networks are employed to infer the source release parameters in an accurate and rapid manner using sensor and mean wind speed data. We consider two neural network constructions that quantify the uncertainty of the predicted values; a categorical classification neural network and a Bayesian neural network. With the categorical classification neural network, we partition the spatial domain and treat each partition as a separate class for which we estimate the probability that it contains the true source location. In a Bayesian neural network, the weights and biases have a distribution rather than a single optimal value. With each evaluation, these distributions are sampled, yielding a different prediction with each evaluation. The trained Bayesian neural network is thus evaluated to construct posterior densities for the release parameters. Results are compared to Markov chain Monte Carlo (MCMC) results found using the Delayed Rejection Adaptive Metropolis Algorithm. The Bayesian neural network approach is generally much cheaper computationally than the MCMC approach as it relies on the computational cost of the neural network evaluation to generate posterior densities as opposed to the MCMC approach which depends on the computational expense of the transport and radiation detection models.
Evidence of Human-Like Visual-Linguistic Integration in Multimodal Large Language Models During Predictive Language Processing
Aug 11, 2023The advanced language processing abilities of large language models (LLMs) have stimulated debate over their capacity to replicate human-like cognitive processes. One differentiating factor between language processing in LLMs and humans is that language input is often grounded in more than one perceptual modality, whereas most LLMs process solely text-based information. Multimodal grounding allows humans to integrate - e.g. visual context with linguistic information and thereby place constraints on the space of upcoming words, reducing cognitive load and improving perception and comprehension. Recent multimodal LLMs (mLLMs) combine visual and linguistic embedding spaces with a transformer type attention mechanism for next-word prediction. To what extent does predictive language processing based on multimodal input align in mLLMs and humans? To answer this question, 200 human participants watched short audio-visual clips and estimated the predictability of an upcoming verb or noun. The same clips were processed by the mLLM CLIP, with predictability scores based on a comparison of image and text feature vectors. Eye-tracking was used to estimate what visual features participants attended to, and CLIP's visual attention weights were recorded. We find that human estimates of predictability align significantly with CLIP scores, but not for a unimodal LLM of comparable parameter size. Further, alignment vanished when CLIP's visual attention weights were perturbed, and when the same input was fed to a multimodal model without attention. Analysing attention patterns, we find a significant spatial overlap between CLIP's visual attention weights and human eye-tracking data. Results suggest that comparable processes of integrating multimodal information, guided by attention to relevant visual features, supports predictive language processing in mLLMs and humans.