 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFindings of the Shared Task on Offensive Span Identification from Code-Mixed Tamil-English Comments
May 12, 2022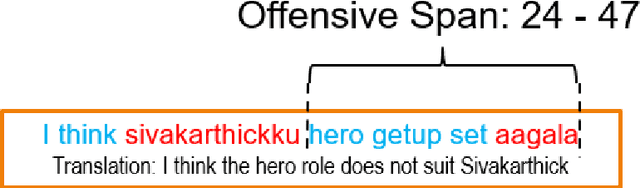
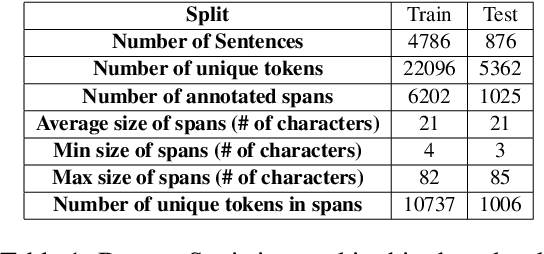
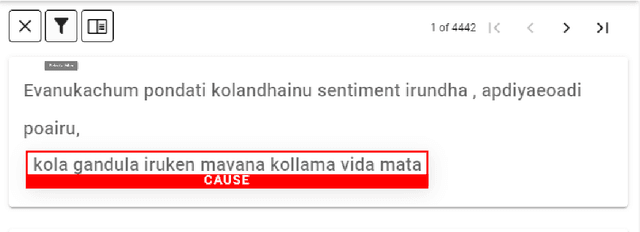
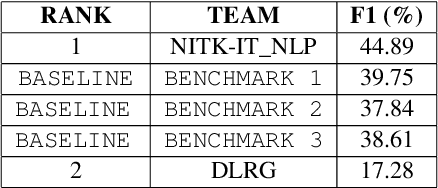
Offensive content moderation is vital in social media platforms to support healthy online discussions. However, their prevalence in codemixed Dravidian languages is limited to classifying whole comments without identifying part of it contributing to offensiveness. Such limitation is primarily due to the lack of annotated data for offensive spans. Accordingly, in this shared task, we provide Tamil-English code-mixed social comments with offensive spans. This paper outlines the dataset so released, methods, and results of the submitted systems
Overlapping Word Removal is All You Need: Revisiting Data Imbalance in Hope Speech Detection
Apr 12, 2022
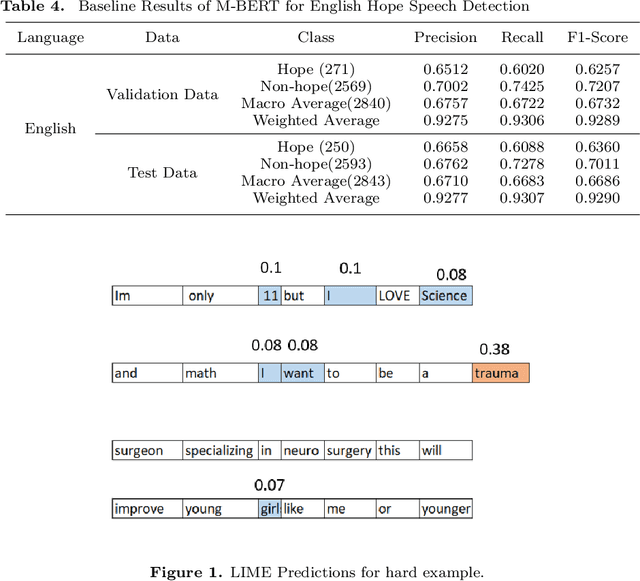


Hope Speech Detection, a task of recognizing positive expressions, has made significant strides recently. However, much of the current works focus on model development without considering the issue of inherent imbalance in the data. Our work revisits this issue in hope-speech detection by introducing focal loss, data augmentation, and pre-processing strategies. Accordingly, we find that introducing focal loss as part of Multilingual-BERT's (M-BERT) training process mitigates the effect of class imbalance and improves overall F1-Macro by 0.11. At the same time, contextual and back-translation-based word augmentation with M-BERT improves results by 0.10 over baseline despite imbalance. Finally, we show that overlapping word removal based on pre-processing, though simple, improves F1-Macro by 0.28. In due process, we present detailed studies depicting various behaviors of each of these strategies and summarize key findings from our empirical results for those interested in getting the most out of M-BERT for hope speech detection under real-world conditions of data imbalance.
Developing Successful Shared Tasks on Offensive Language Identification for Dravidian Languages
Nov 05, 2021
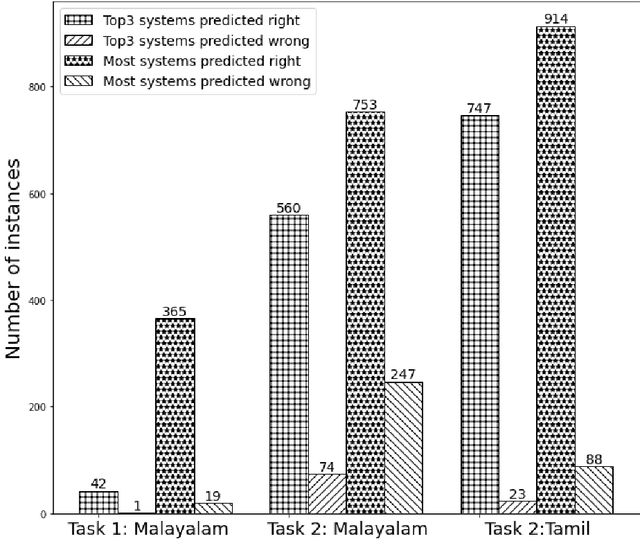

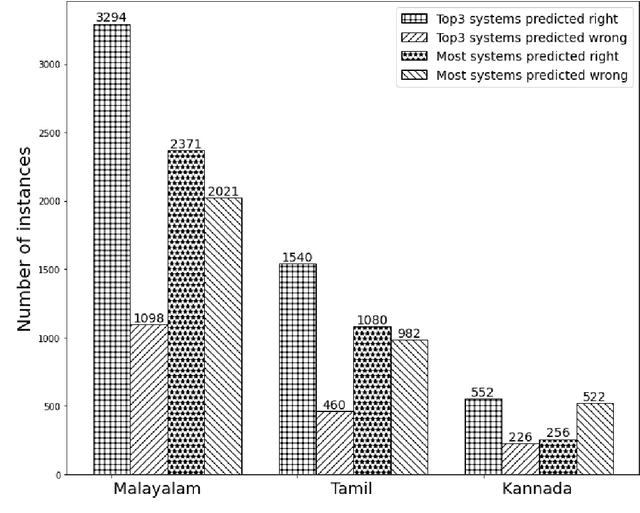
With the fast growth of mobile computing and Web technologies, offensive language has become more prevalent on social networking platforms. Since offensive language identification in local languages is essential to moderate the social media content, in this paper we work with three Dravidian languages, namely Malayalam, Tamil, and Kannada, that are under-resourced. We present an evaluation task at FIRE 2020- HASOC-DravidianCodeMix and DravidianLangTech at EACL 2021, designed to provide a framework for comparing different approaches to this problem. This paper describes the data creation, defines the task, lists the participating systems, and discusses various methods.