 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable AI for Bioinformatics: Methods, Tools, and Applications
Dec 25, 2022Artificial intelligence(AI) systems based on deep neural networks (DNNs) and machine learning (ML) algorithms are increasingly used to solve critical problems in bioinformatics, biomedical informatics, and precision medicine. However, complex DNN or ML models that are unavoidably opaque and perceived as black-box methods, may not be able to explain why and how they make certain decisions. Such black-box models are difficult to comprehend not only for targeted users and decision-makers but also for AI developers. Besides, in sensitive areas like healthcare, explainability and accountability are not only desirable properties of AI but also legal requirements -- especially when AI may have significant impacts on human lives. Explainable artificial intelligence (XAI) is an emerging field that aims to mitigate the opaqueness of black-box models and make it possible to interpret how AI systems make their decisions with transparency. An interpretable ML model can explain how it makes predictions and which factors affect the model's outcomes. The majority of state-of-the-art interpretable ML methods have been developed in a domain-agnostic way and originate from computer vision, automated reasoning, or even statistics. Many of these methods cannot be directly applied to bioinformatics problems, without prior customization, extension, and domain adoption. In this paper, we discuss the importance of explainability with a focus on bioinformatics. We analyse and comprehensively overview of model-specific and model-agnostic interpretable ML methods and tools. Via several case studies covering bioimaging, cancer genomics, and biomedical text mining, we show how bioinformatics research could benefit from XAI methods and how they could help improve decision fairness.
Multimodal Hate Speech Detection from Bengali Memes and Texts
Apr 19, 2022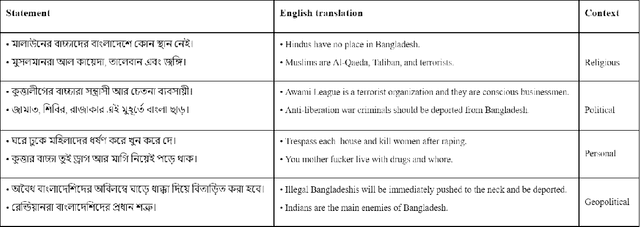
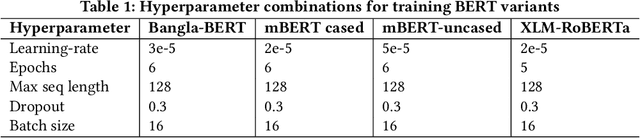
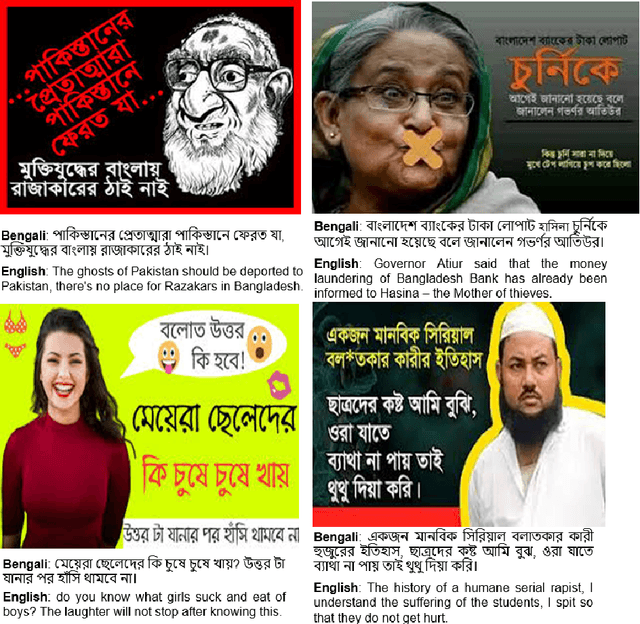
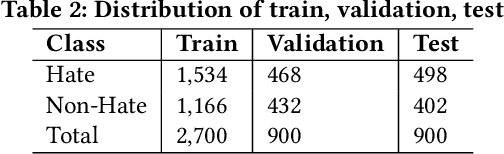
Numerous works have been proposed to employ machine learning (ML) and deep learning (DL) techniques to utilize textual data from social media for anti-social behavior analysis such as cyberbullying, fake news propagation, and hate speech mainly for highly resourced languages like English. However, despite having a lot of diversity and millions of native speakers, some languages such as Bengali are under-resourced, which is due to a lack of computational resources for natural language processing (NLP). Like English, Bengali social media content also includes images along with texts (e.g., multimodal contents are posted by embedding short texts into images on Facebook), only the textual data is not enough to judge them (e.g., to determine they are hate speech). In those cases, images might give extra context to properly judge. This paper is about hate speech detection from multimodal Bengali memes and texts. We prepared the only multimodal hate speech detection dataset1 for a kind of problem for Bengali. We train several neural architectures (i.e., neural networks like Bi-LSTM/Conv-LSTM with word embeddings, EfficientNet + transformer architectures such as monolingual Bangla BERT, multilingual BERT-cased/uncased, and XLM-RoBERTa) jointly analyze textual and visual information for hate speech detection. The Conv-LSTM and XLM-RoBERTa models performed best for texts, yielding F1 scores of 0.78 and 0.82, respectively. As of memes, ResNet152 and DenseNet201 models yield F1 scores of 0.78 and 0.7, respectively. The multimodal fusion of mBERT-uncased + EfficientNet-B1 performed the best, yielding an F1 score of 0.80. Our study suggests that memes are moderately useful for hate speech detection in Bengali, but none of the multimodal models outperform unimodal models analyzing only textual data.
A Deep Neural Network Approach for Crop Selection and Yield Prediction in Bangladesh
Aug 06, 2021
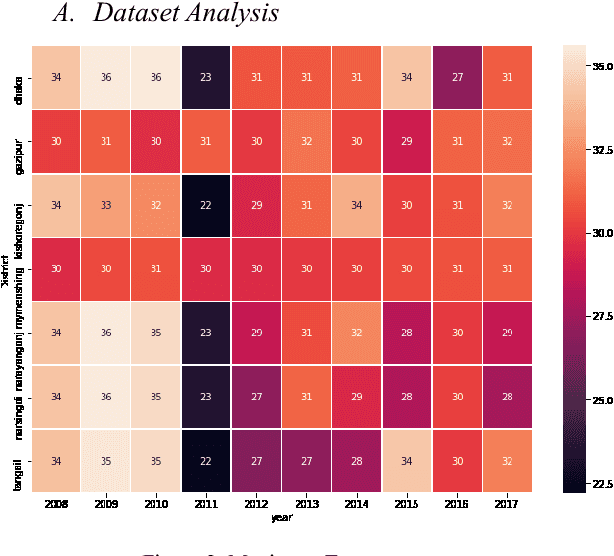

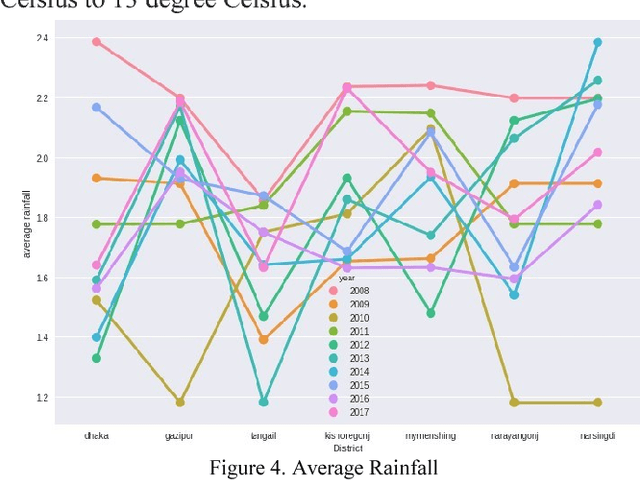
Agriculture is the essential ingredients to mankind which is a major source of livelihood. Agriculture work in Bangladesh is mostly done in old ways which directly affects our economy. In addition, institutions of agriculture are working with manual data which cannot provide a proper solution for crop selection and yield prediction. This paper shows the best way of crop selection and yield prediction in minimum cost and effort. Artificial Neural Network is considered robust tools for modeling and prediction. This algorithm aims to get better output and prediction, as well as, support vector machine, Logistic Regression, and random forest algorithm is also considered in this study for comparing the accuracy and error rate. Moreover, all of these algorithms used here are just to see how well they performed for a dataset which is over 0.3 million. We have collected 46 parameters such as maximum and minimum temperature, average rainfall, humidity, climate, weather, and types of land, types of chemical fertilizer, types of soil, soil structure, soil composition, soil moisture, soil consistency, soil reaction and soil texture for applying into this prediction process. In this paper, we have suggested using the deep neural network for agricultural crop selection and yield prediction.