 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Large Language Models to Knowledge Graphs for Biomarker Discovery in Cancer
Oct 12, 2023Domain experts often rely on up-to-date knowledge for apprehending and disseminating specific biological processes that help them design strategies to develop prevention and therapeutic decision-making. A challenging scenario for artificial intelligence (AI) is using biomedical data (e.g., texts, imaging, omics, and clinical) to provide diagnosis and treatment recommendations for cancerous conditions. Data and knowledge about cancer, drugs, genes, proteins, and their mechanism is spread across structured (knowledge bases (KBs)) and unstructured (e.g., scientific articles) sources. A large-scale knowledge graph (KG) can be constructed by integrating these data, followed by extracting facts about semantically interrelated entities and relations. Such KGs not only allow exploration and question answering (QA) but also allow domain experts to deduce new knowledge. However, exploring and querying large-scale KGs is tedious for non-domain users due to a lack of understanding of the underlying data assets and semantic technologies. In this paper, we develop a domain KG to leverage cancer-specific biomarker discovery and interactive QA. For this, a domain ontology called OncoNet Ontology (ONO) is developed to enable semantic reasoning for validating gene-disease relations. The KG is then enriched by harmonizing the ONO, controlled vocabularies, and additional biomedical concepts from scientific articles by employing BioBERT- and SciBERT-based information extraction (IE) methods. Further, since the biomedical domain is evolving, where new findings often replace old ones, without employing up-to-date findings, there is a high chance an AI system exhibits concept drift while providing diagnosis and treatment. Therefore, we finetuned the KG using large language models (LLMs) based on more recent articles and KBs that might not have been seen by the named entity recognition models.
A Biomedical Knowledge Graph for Biomarker Discovery in Cancer
Feb 23, 2023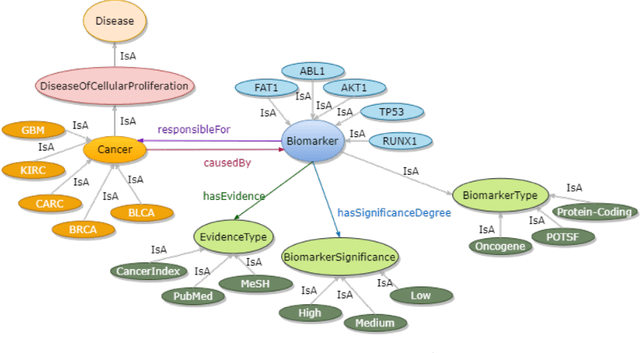
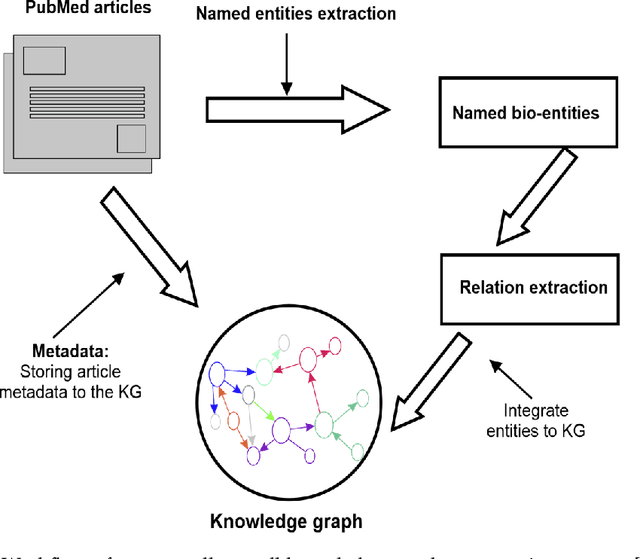

Structured and unstructured data and facts about drugs, genes, protein, viruses, and their mechanism are spread across a huge number of scientific articles. These articles are a large-scale knowledge source and can have a huge impact on disseminating knowledge about the mechanisms of certain biological processes. A domain-specific knowledge graph~(KG) is an explicit conceptualization of a specific subject-matter domain represented w.r.t semantically interrelated entities and relations. A KG can be constructed by integrating such facts and data and be used for data integration, exploration, and federated queries. However, exploration and querying large-scale KGs is tedious for certain groups of users due to a lack of knowledge about underlying data assets or semantic technologies. Such a KG will not only allow deducing new knowledge and question answering(QA) but also allows domain experts to explore. Since cross-disciplinary explanations are important for accurate diagnosis, it is important to query the KG to provide interactive explanations about learned biomarkers. Inspired by these, we construct a domain-specific KG, particularly for cancer-specific biomarker discovery. The KG is constructed by integrating cancer-related knowledge and facts from multiple sources. First, we construct a domain-specific ontology, which we call OncoNet Ontology (ONO). The ONO ontology is developed to enable semantic reasoning for verification of the predictions for relations between diseases and genes. The KG is then developed and enriched by harmonizing the ONO, additional metadata schemas, ontologies, controlled vocabularies, and additional concepts from external sources using a BERT-based information extraction method. BioBERT and SciBERT are finetuned with the selected articles crawled from PubMed. We listed down some queries and some examples of QA and deducing knowledge based on the KG.