 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Inconsistencies and How to Mitigate Them in Deep Learning
Apr 03, 2025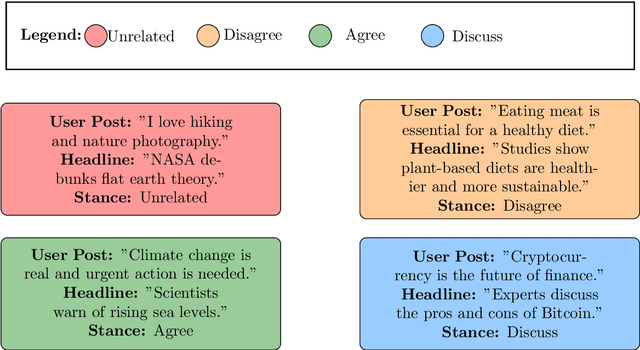



The recent advancements in Deep Learning models and techniques have led to significant strides in performance across diverse tasks and modalities. However, while the overall capabilities of models show promising growth, our understanding of their internal reasoning processes remains limited, particularly concerning systematic inconsistencies or errors patterns of logical or inferential flaws. These inconsistencies may manifest as contradictory outputs, failure to generalize across similar tasks, or erroneous conclusions in specific contexts. Even detecting and measuring such reasoning discrepancies is challenging, as they may arise from opaque internal procedures, biases and imbalances in training data, or the inherent complexity of the task. Without effective methods to detect, measure, and mitigate these errors, there is a risk of deploying models that are biased, exploitable, or logically unreliable. This thesis aims to address these issues by producing novel methods for deep learning models that reason over knowledge graphs, natural language, and images. The thesis contributes two techniques for detecting and quantifying predictive inconsistencies originating from opaque internal procedures in natural language and image processing models. To mitigate inconsistencies from biases in training data, this thesis presents a data efficient sampling method to improve fairness and performance and a synthetic dataset generation approach in low resource scenarios. Finally, the thesis offers two techniques to optimize the models for complex reasoning tasks. These methods enhance model performance while allowing for more faithful and interpretable exploration and exploitation during inference. Critically, this thesis provides a comprehensive framework to improve the robustness, fairness, and interpretability of deep learning models across diverse tasks and modalities.
L0-Reasoning Bench: Evaluating Procedural Correctness in Language Models via Simple Program Execution
Mar 28, 2025Complex reasoning tasks often rely on the ability to consistently and accurately apply simple rules across incremental steps, a foundational capability which we term "level-0" reasoning. To systematically evaluate this capability, we introduce L0-Bench, a language model benchmark for testing procedural correctness -- the ability to generate correct reasoning processes, complementing existing benchmarks that primarily focus on outcome correctness. Given synthetic Python functions with simple operations, L0-Bench grades models on their ability to generate step-by-step, error-free execution traces. The synthetic nature of L0-Bench enables systematic and scalable generation of test programs along various axes (e.g., number of trace steps). We evaluate a diverse array of recent closed-source and open-weight models on a baseline test set. All models exhibit degradation as the number of target trace steps increases, while larger models and reasoning-enhanced models better maintain correctness over multiple steps. Additionally, we use L0-Bench to explore test-time scaling along three dimensions: input context length, number of solutions for majority voting, and inference steps. Our results suggest substantial room to improve "level-0" reasoning and potential directions to build more reliable reasoning systems.
With Great Backbones Comes Great Adversarial Transferability
Jan 21, 2025



Advances in self-supervised learning (SSL) for machine vision have improved representation robustness and model performance, giving rise to pre-trained backbones like \emph{ResNet} and \emph{ViT} models tuned with SSL methods such as \emph{SimCLR}. Due to the computational and data demands of pre-training, the utilization of such backbones becomes a strenuous necessity. However, employing these backbones may inherit vulnerabilities to adversarial attacks. While adversarial robustness has been studied under \emph{white-box} and \emph{black-box} settings, the robustness of models tuned on pre-trained backbones remains largely unexplored. Additionally, the role of tuning meta-information in mitigating exploitation risks is unclear. This work systematically evaluates the adversarial robustness of such models across $20,000$ combinations of tuning meta-information, including fine-tuning techniques, backbone families, datasets, and attack types. We propose using proxy models to transfer attacks, simulating varying levels of target knowledge by fine-tuning these proxies with diverse configurations. Our findings reveal that proxy-based attacks approach the effectiveness of \emph{white-box} methods, even with minimal tuning knowledge. We also introduce a naive "backbone attack," leveraging only the backbone to generate adversarial samples, which outperforms \emph{black-box} attacks and rivals \emph{white-box} methods, highlighting critical risks in model-sharing practices. Finally, our ablations reveal how increasing tuning meta-information impacts attack transferability, measuring each meta-information combination.
FLARE: Faithful Logic-Aided Reasoning and Exploration
Oct 14, 2024
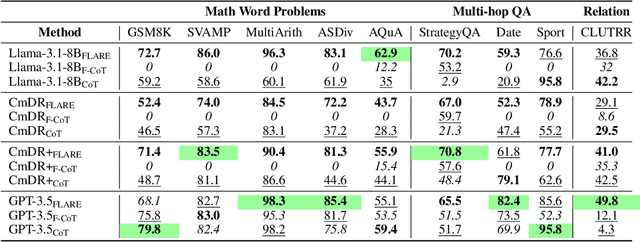

Modern Question Answering (QA) and Reasoning approaches based on Large Language Models (LLMs) commonly use prompting techniques, such as Chain-of-Thought (CoT), assuming the resulting generation will have a more granular exploration and reasoning over the question space and scope. However, such methods struggle with generating outputs that are faithful to the intermediate chain of reasoning produced by the model. On the other end of the spectrum, neuro-symbolic methods such as Faithful CoT (F-CoT) propose to combine LLMs with external symbolic solvers. While such approaches boast a high degree of faithfulness, they usually require a model trained for code generation and struggle with tasks that are ambiguous or hard to formalise strictly. We introduce \textbf{F}aithful \textbf{L}ogic-\textbf{A}ided \textbf{R}easoning and \textbf{E}xploration (\textbf{\ours}), a novel interpretable approach for traversing the problem space using task decompositions. We use the LLM to plan a solution, soft-formalise the query into facts and predicates using a logic programming code and simulate that code execution using an exhaustive multi-hop search over the defined space. Our method allows us to compute the faithfulness of the reasoning process w.r.t. the generated code and analyse the steps of the multi-hop search without relying on external solvers. Our methods achieve SOTA results on $\mathbf{7}$ out of $\mathbf{9}$ diverse reasoning benchmarks. We also show that model faithfulness positively correlates with overall performance and further demonstrate that {\textbf{\ours}} allows pinpointing the decisive factors sufficient for and leading to the correct answer with optimal reasoning during the multi-hop search.
SynDARin: Synthesising Datasets for Automated Reasoning in Low-Resource Languages
Jun 20, 2024


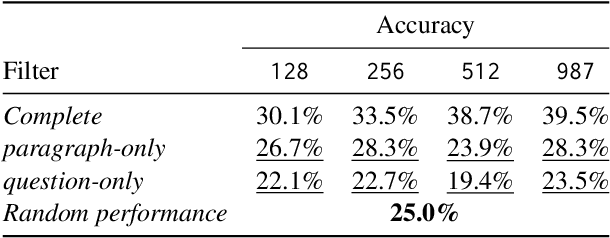
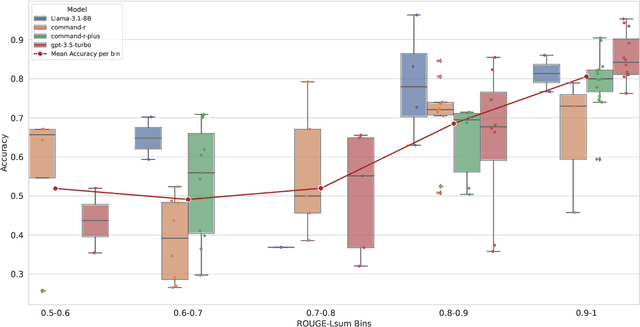
Question Answering (QA) datasets have been instrumental in developing and evaluating Large Language Model (LLM) capabilities. However, such datasets are scarce for languages other than English due to the cost and difficulties of collection and manual annotation. This means that producing novel models and measuring the performance of multilingual LLMs in low-resource languages is challenging. To mitigate this, we propose $\textbf{S}$yn$\textbf{DAR}$in, a method for generating and validating QA datasets for low-resource languages. We utilize parallel content mining to obtain $\textit{human-curated}$ paragraphs between English and the target language. We use the English data as context to $\textit{generate}$ synthetic multiple-choice (MC) question-answer pairs, which are automatically translated and further validated for quality. Combining these with their designated non-English $\textit{human-curated}$ paragraphs form the final QA dataset. The method allows to maintain the content quality, reduces the likelihood of factual errors, and circumvents the need for costly annotation. To test the method, we created a QA dataset with $1.2$K samples for the Armenian language. The human evaluation shows that $98\%$ of the generated English data maintains quality and diversity in the question types and topics, while the translation validation pipeline can filter out $\sim70\%$ of data with poor quality. We use the dataset to benchmark state-of-the-art LLMs, showing their inability to achieve human accuracy with some model performances closer to random chance. This shows that the generated dataset is non-trivial and can be used to evaluate reasoning capabilities in low-resource language.
Semantic Sensitivities and Inconsistent Predictions: Measuring the Fragility of NLI Models
Jan 31, 2024



Recent studies of the emergent capabilities of transformer-based Natural Language Understanding (NLU) models have indicated that they have an understanding of lexical and compositional semantics. We provide evidence that suggests these claims should be taken with a grain of salt: we find that state-of-the-art Natural Language Inference (NLI) models are sensitive towards minor semantics preserving surface-form variations, which lead to sizable inconsistent model decisions during inference. Notably, this behaviour differs from valid and in-depth comprehension of compositional semantics, however does neither emerge when evaluating model accuracy on standard benchmarks nor when probing for syntactic, monotonic, and logically robust reasoning. We propose a novel framework to measure the extent of semantic sensitivity. To this end, we evaluate NLI models on adversarially generated examples containing minor semantics-preserving surface-form input noise. This is achieved using conditional text generation, with the explicit condition that the NLI model predicts the relationship between the original and adversarial inputs as a symmetric equivalence entailment. We systematically study the effects of the phenomenon across NLI models for $\textbf{in-}$ and $\textbf{out-of-}$ domain settings. Our experiments show that semantic sensitivity causes performance degradations of $12.92\%$ and $23.71\%$ average over $\textbf{in-}$ and $\textbf{out-of-}$ domain settings, respectively. We further perform ablation studies, analysing this phenomenon across models, datasets, and variations in inference and show that semantic sensitivity can lead to major inconsistency within model predictions.
Approximate Answering of Graph Queries
Aug 12, 2023Knowledge graphs (KGs) are inherently incomplete because of incomplete world knowledge and bias in what is the input to the KG. Additionally, world knowledge constantly expands and evolves, making existing facts deprecated or introducing new ones. However, we would still want to be able to answer queries as if the graph were complete. In this chapter, we will give an overview of several methods which have been proposed to answer queries in such a setting. We will first provide an overview of the different query types which can be supported by these methods and datasets typically used for evaluation, as well as an insight into their limitations. Then, we give an overview of the different approaches and describe them in terms of expressiveness, supported graph types, and inference capabilities.
Topic-Guided Sampling For Data-Efficient Multi-Domain Stance Detection
Jun 01, 2023Stance Detection is concerned with identifying the attitudes expressed by an author towards a target of interest. This task spans a variety of domains ranging from social media opinion identification to detecting the stance for a legal claim. However, the framing of the task varies within these domains, in terms of the data collection protocol, the label dictionary and the number of available annotations. Furthermore, these stance annotations are significantly imbalanced on a per-topic and inter-topic basis. These make multi-domain stance detection a challenging task, requiring standardization and domain adaptation. To overcome this challenge, we propose $\textbf{T}$opic $\textbf{E}$fficient $\textbf{St}$anc$\textbf{E}$ $\textbf{D}$etection (TESTED), consisting of a topic-guided diversity sampling technique and a contrastive objective that is used for fine-tuning a stance classifier. We evaluate the method on an existing benchmark of $16$ datasets with in-domain, i.e. all topics seen and out-of-domain, i.e. unseen topics, experiments. The results show that our method outperforms the state-of-the-art with an average of $3.5$ F1 points increase in-domain, and is more generalizable with an averaged increase of $10.2$ F1 on out-of-domain evaluation while using $\leq10\%$ of the training data. We show that our sampling technique mitigates both inter- and per-topic class imbalances. Finally, our analysis demonstrates that the contrastive learning objective allows the model a more pronounced segmentation of samples with varying labels.
Adapting Neural Link Predictors for Complex Query Answering
Jan 29, 2023Answering complex queries on incomplete knowledge graphs is a challenging task where a model needs to answer complex logical queries in the presence of missing knowledge. Recently, Arakelyan et al. (2021); Minervini et al. (2022) showed that neural link predictors could also be used for answering complex queries: their Continuous Query Decomposition (CQD) method works by decomposing complex queries into atomic sub-queries, answers them using neural link predictors and aggregates their scores via t-norms for ranking the answers to each complex query. However, CQD does not handle negations and only uses the training signal from atomic training queries: neural link prediction scores are not calibrated to interact together via fuzzy logic t-norms during complex query answering. In this work, we propose to address this problem by training a parameter-efficient score adaptation model to re-calibrate neural link prediction scores: this new component is trained on complex queries by back-propagating through the complex query-answering process. Our method, CQD$^{A}$, produces significantly more accurate results than current state-of-the-art methods, improving from $34.4$ to $35.1$ Mean Reciprocal Rank values averaged across all datasets and query types while using $\leq 35\%$ of the available training query types. We further show that CQD$^{A}$ is data-efficient, achieving competitive results with only $1\%$ of the training data, and robust in out-of-domain evaluations.
Complex Query Answering with Neural Link Predictors
Nov 06, 2020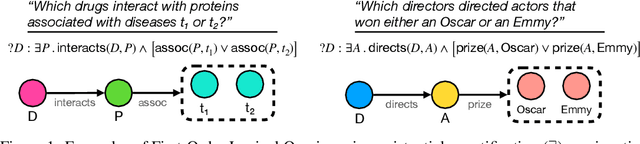
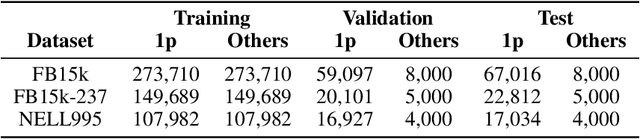

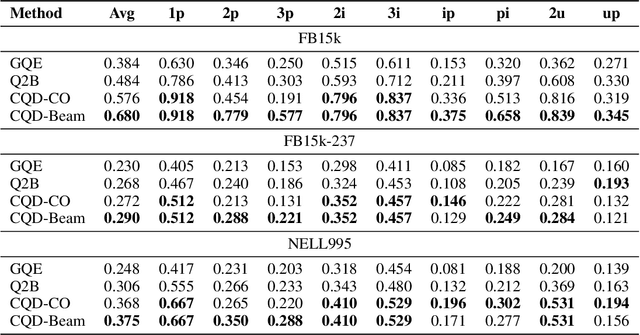
Neural link predictors are immensely useful for identifying missing edges in large scale Knowledge Graphs. However, it is still not clear how to use these models for answering more complex queries that arise in a number of domains, such as queries using logical conjunctions, disjunctions, and existential quantifiers, while accounting for missing edges. In this work, we propose a framework for efficiently answering complex queries on incomplete Knowledge Graphs. We translate each query into an end-to-end differentiable objective, where the truth value of each atom is computed by a pre-trained neural link predictor. We then analyse two solutions to the optimisation problem, including gradient-based and combinatorial search. In our experiments, the proposed approach produces more accurate results than state-of-the-art methods -- black-box neural models trained on millions of generated queries -- without the need of training on a large and diverse set of complex queries. Using orders of magnitude less training data, we obtain relative improvements ranging from 8% up to 40% in Hits@3 across different knowledge graphs containing factual information. Finally, we demonstrate that it is possible to explain the outcome of our model in terms of the intermediate solutions identified for each of the complex query atoms.