 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynDARin: Synthesising Datasets for Automated Reasoning in Low-Resource Languages
Paper and Code
Jun 20, 2024


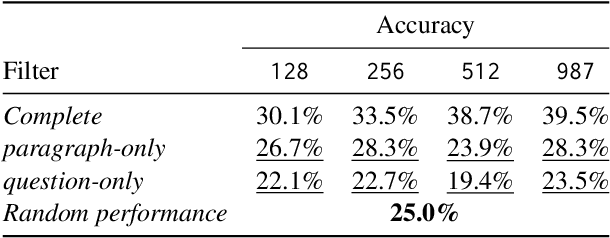
Question Answering (QA) datasets have been instrumental in developing and evaluating Large Language Model (LLM) capabilities. However, such datasets are scarce for languages other than English due to the cost and difficulties of collection and manual annotation. This means that producing novel models and measuring the performance of multilingual LLMs in low-resource languages is challenging. To mitigate this, we propose $\textbf{S}$yn$\textbf{DAR}$in, a method for generating and validating QA datasets for low-resource languages. We utilize parallel content mining to obtain $\textit{human-curated}$ paragraphs between English and the target language. We use the English data as context to $\textit{generate}$ synthetic multiple-choice (MC) question-answer pairs, which are automatically translated and further validated for quality. Combining these with their designated non-English $\textit{human-curated}$ paragraphs form the final QA dataset. The method allows to maintain the content quality, reduces the likelihood of factual errors, and circumvents the need for costly annotation. To test the method, we created a QA dataset with $1.2$K samples for the Armenian language. The human evaluation shows that $98\%$ of the generated English data maintains quality and diversity in the question types and topics, while the translation validation pipeline can filter out $\sim70\%$ of data with poor quality. We use the dataset to benchmark state-of-the-art LLMs, showing their inability to achieve human accuracy with some model performances closer to random chance. This shows that the generated dataset is non-trivial and can be used to evaluate reasoning capabilities in low-resource language.