 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLARE: Faithful Logic-Aided Reasoning and Exploration
Paper and Code
Oct 14, 2024
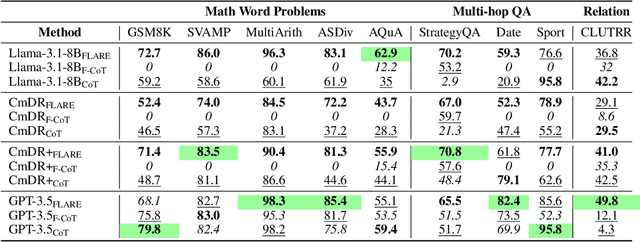
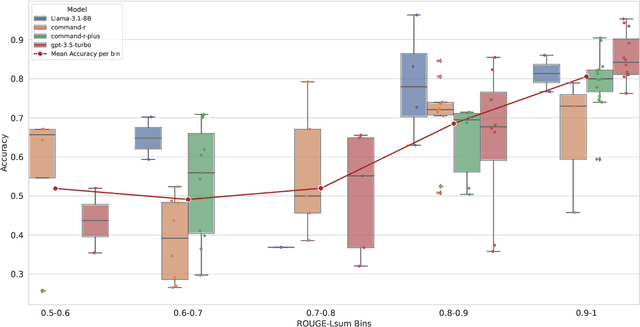

Modern Question Answering (QA) and Reasoning approaches based on Large Language Models (LLMs) commonly use prompting techniques, such as Chain-of-Thought (CoT), assuming the resulting generation will have a more granular exploration and reasoning over the question space and scope. However, such methods struggle with generating outputs that are faithful to the intermediate chain of reasoning produced by the model. On the other end of the spectrum, neuro-symbolic methods such as Faithful CoT (F-CoT) propose to combine LLMs with external symbolic solvers. While such approaches boast a high degree of faithfulness, they usually require a model trained for code generation and struggle with tasks that are ambiguous or hard to formalise strictly. We introduce \textbf{F}aithful \textbf{L}ogic-\textbf{A}ided \textbf{R}easoning and \textbf{E}xploration (\textbf{\ours}), a novel interpretable approach for traversing the problem space using task decompositions. We use the LLM to plan a solution, soft-formalise the query into facts and predicates using a logic programming code and simulate that code execution using an exhaustive multi-hop search over the defined space. Our method allows us to compute the faithfulness of the reasoning process w.r.t. the generated code and analyse the steps of the multi-hop search without relying on external solvers. Our methods achieve SOTA results on $\mathbf{7}$ out of $\mathbf{9}$ diverse reasoning benchmarks. We also show that model faithfulness positively correlates with overall performance and further demonstrate that {\textbf{\ours}} allows pinpointing the decisive factors sufficient for and leading to the correct answer with optimal reasoning during the multi-hop search.