 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Rank-based Evaluation Metrics for Link Prediction in Knowledge Graphs
Paper and Code


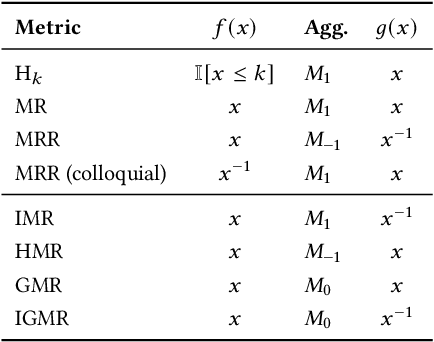
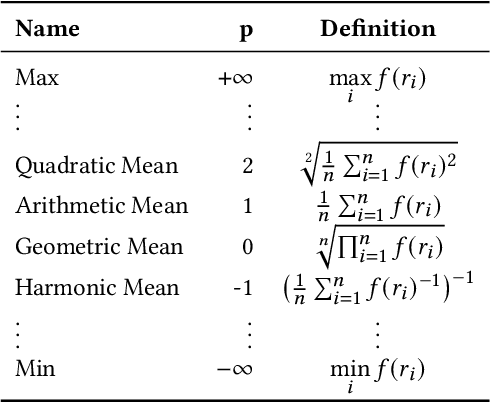
The link prediction task on knowledge graphs without explicit negative triples in the training data motivates the usage of rank-based metrics. Here, we review existing rank-based metrics and propose desiderata for improved metrics to address lack of interpretability and comparability of existing metrics to datasets of different sizes and properties. We introduce a simple theoretical framework for rank-based metrics upon which we investigate two avenues for improvements to existing metrics via alternative aggregation functions and concepts from probability theory. We finally propose several new rank-based metrics that are more easily interpreted and compared accompanied by a demonstration of their usage in a benchmarking of knowledge graph embedding models.