Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Learning for Argument Strength Estimation
Sep 23, 2021
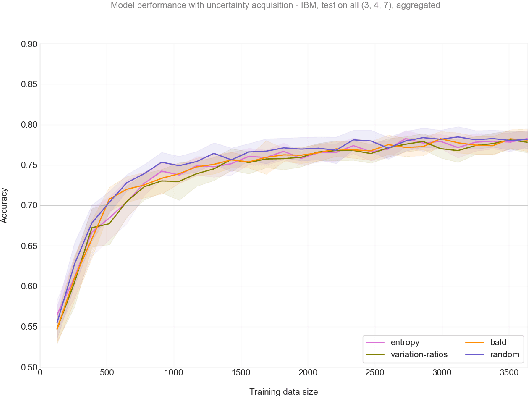

High-quality arguments are an essential part of decision-making. Automatically predicting the quality of an argument is a complex task that recently got much attention in argument mining. However, the annotation effort for this task is exceptionally high. Therefore, we test uncertainty-based active learning (AL) methods on two popular argument-strength data sets to estimate whether sample-efficient learning can be enabled. Our extensive empirical evaluation shows that uncertainty-based acquisition functions can not surpass the accuracy reached with the random acquisition on these data sets.
Via