 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching the Clinical Reality: Accurate OCT-Based Diagnosis From Few Labels
Oct 23, 2020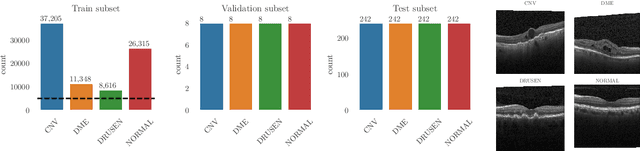
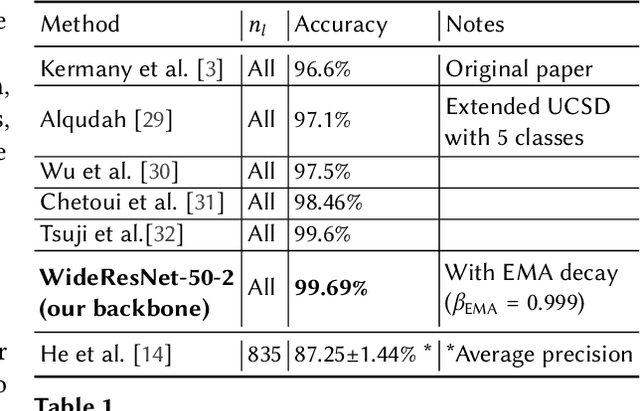

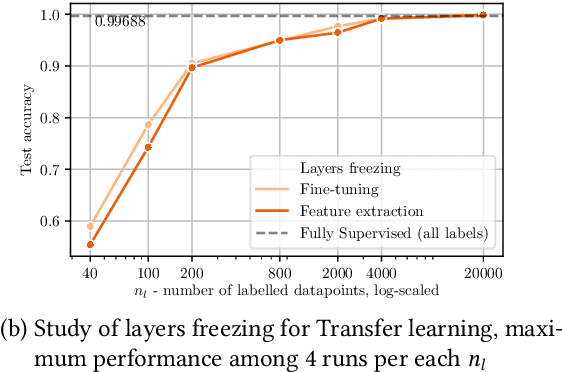
Unlabeled data is often abundant in the clinic, making machine learning methods based on semi-supervised learning a good match for this setting. Despite this, they are currently receiving relatively little attention in medical image analysis literature. Instead, most practitioners and researchers focus on supervised or transfer learning approaches. The recently proposed MixMatch and FixMatch algorithms have demonstrated promising results in extracting useful representations while requiring very few labels. Motivated by these recent successes, we apply MixMatch and FixMatch in an ophthalmological diagnostic setting and investigate how they fare against standard transfer learning. We find that both algorithms outperform the transfer learning baseline on all fractions of labelled data. Furthermore, our experiments show that exponential moving average (EMA) of model parameters, which is a component of both algorithms, is not needed for our classification problem, as disabling it leaves the outcome unchanged. Our code is available online: https://github.com/Valentyn1997/oct-diagn-semi-supervised
Walking the Tightrope: An Investigation of the Convolutional Autoencoder Bottleneck
Nov 18, 2019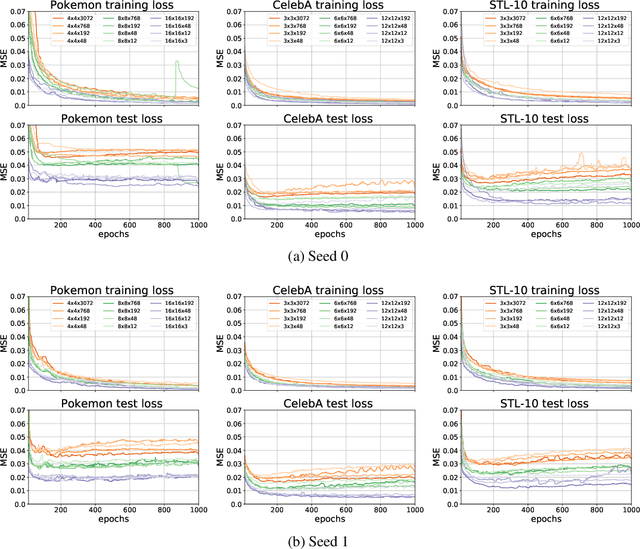

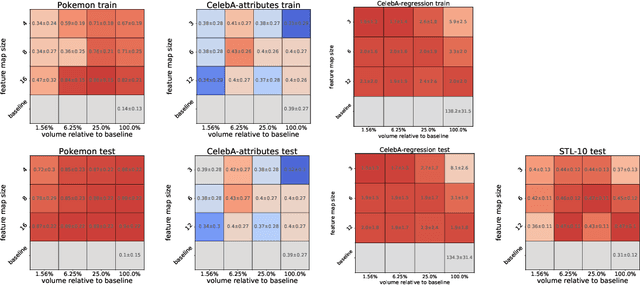
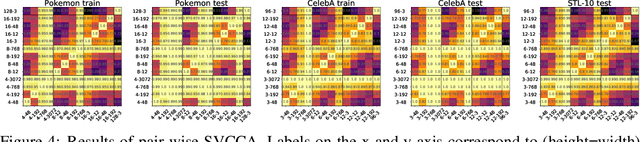
In this paper, we present an in-depth investigation of the convolutional autoencoder (CAE) bottleneck. Autoencoders (AE), and especially their convolutional variants, play a vital role in the current deep learning toolbox. Researchers and practitioners employ CAEs for a variety of tasks, ranging from outlier detection and compression to transfer and representation learning. Despite their widespread adoption, we have limited insight into how the bottleneck shape impacts the emergent properties of the CAE. We demonstrate that increased height and width of the bottleneck drastically improves generalization, which in turn leads to better performance of the latent codes in downstream transfer learning tasks. The number of channels in the bottleneck, on the other hand, is secondary in importance. Furthermore, we show empirically that, contrary to popular belief, CAEs do not learn to copy their input, even when the bottleneck has the same number of neurons as there are pixels in the input. Copying does not occur, despite training the CAE for 1,000 epochs on a tiny ($\approx$ 600 images) dataset. We believe that the findings in this paper are directly applicable and will lead to improvements in models that rely on CAEs.
Push it to the Limit: Discover Edge-Cases in Image Data with Autoencoders
Oct 07, 2019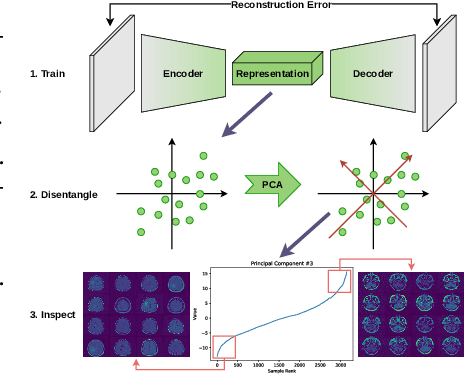

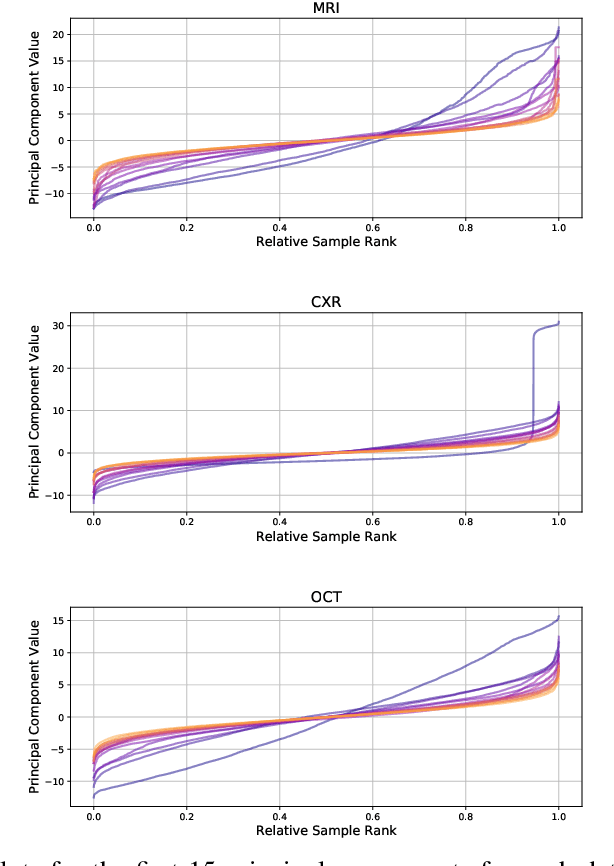
In this paper, we focus on the problem of identifying semantic factors of variation in large image datasets. By training a convolutional Autoencoder on the image data, we create encodings, which describe each datapoint at a higher level of abstraction than pixel-space. We then apply Principal Component Analysis to the encodings to disentangle the factors of variation in the data. Sorting the dataset according to the values of individual principal components, we find that samples at the high and low ends of the distribution often share specific semantic characteristics. We refer to these groups of samples as semantic groups. When applied to real-world data, this method can help discover unwanted edge-cases.
Noise as Domain Shift: Denoising Medical Images by Unpaired Image Translation
Oct 07, 2019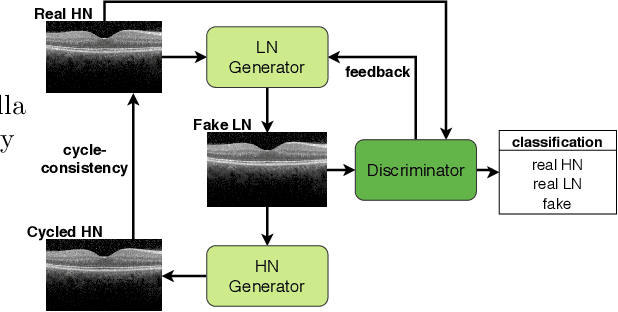
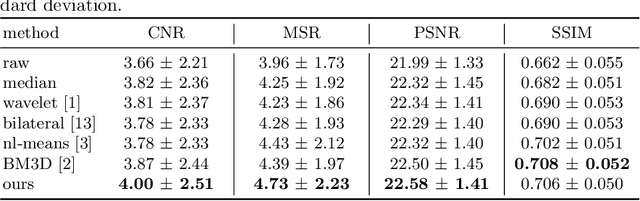
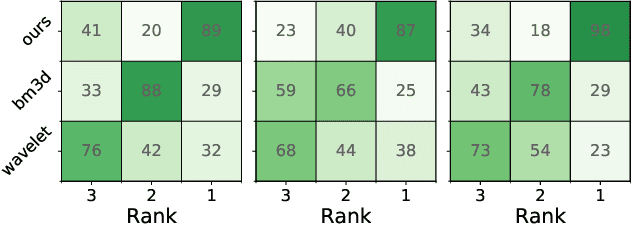
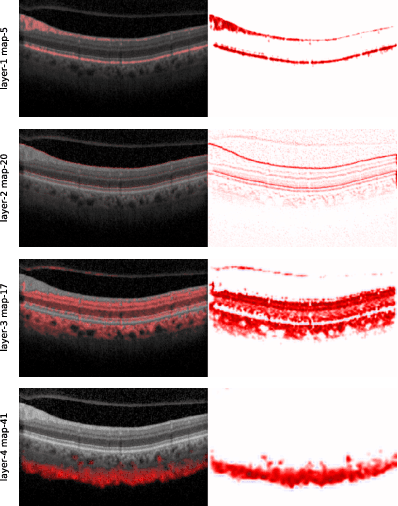
We cast the problem of image denoising as a domain translation problem between high and low noise domains. By modifying the cycleGAN model, we are able to learn a mapping between these domains on unpaired retinal optical coherence tomography images. In quantitative measurements and a qualitative evaluation by ophthalmologists, we show how this approach outperforms other established methods. The results indicate that the network differentiates subtle changes in the level of noise in the image. Further investigation of the model's feature maps reveals that it has learned to distinguish retinal layers and other distinct regions of the images.