Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePush it to the Limit: Discover Edge-Cases in Image Data with Autoencoders
Paper and Code
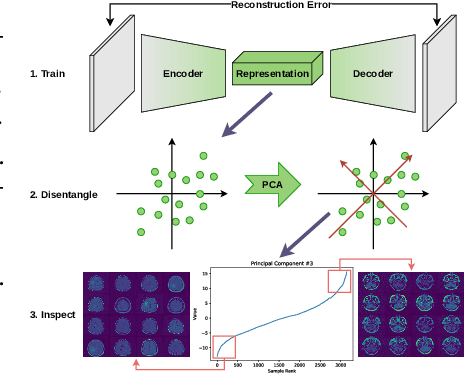

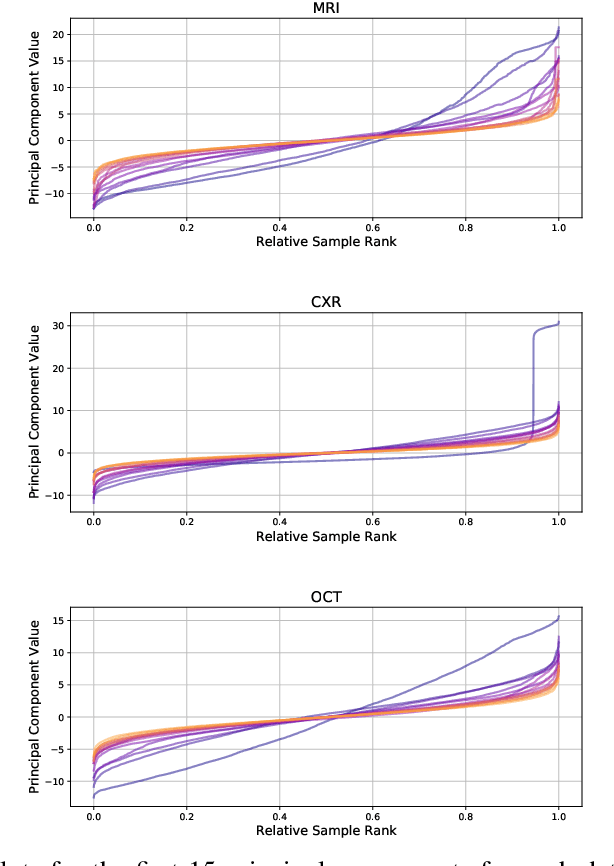
In this paper, we focus on the problem of identifying semantic factors of variation in large image datasets. By training a convolutional Autoencoder on the image data, we create encodings, which describe each datapoint at a higher level of abstraction than pixel-space. We then apply Principal Component Analysis to the encodings to disentangle the factors of variation in the data. Sorting the dataset according to the values of individual principal components, we find that samples at the high and low ends of the distribution often share specific semantic characteristics. We refer to these groups of samples as semantic groups. When applied to real-world data, this method can help discover unwanted edge-cases.
* Accepted as a workshop paper at MEDNeurIPS 2019
View paper on