 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWalking the Tightrope: An Investigation of the Convolutional Autoencoder Bottleneck
Paper and Code
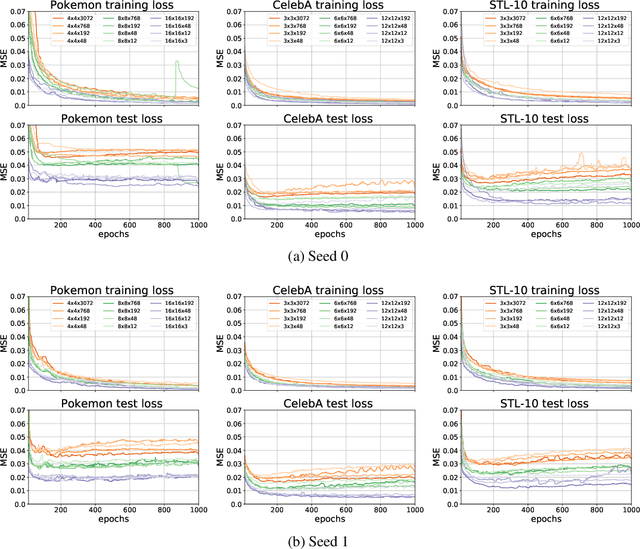

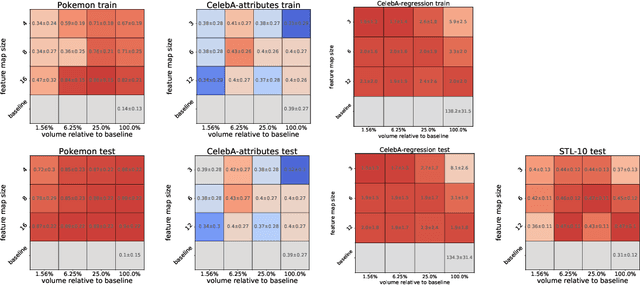
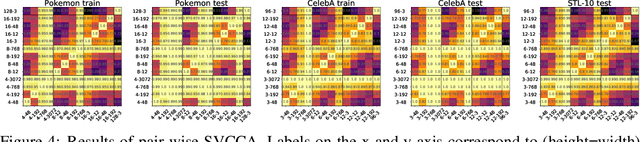
In this paper, we present an in-depth investigation of the convolutional autoencoder (CAE) bottleneck. Autoencoders (AE), and especially their convolutional variants, play a vital role in the current deep learning toolbox. Researchers and practitioners employ CAEs for a variety of tasks, ranging from outlier detection and compression to transfer and representation learning. Despite their widespread adoption, we have limited insight into how the bottleneck shape impacts the emergent properties of the CAE. We demonstrate that increased height and width of the bottleneck drastically improves generalization, which in turn leads to better performance of the latent codes in downstream transfer learning tasks. The number of channels in the bottleneck, on the other hand, is secondary in importance. Furthermore, we show empirically that, contrary to popular belief, CAEs do not learn to copy their input, even when the bottleneck has the same number of neurons as there are pixels in the input. Copying does not occur, despite training the CAE for 1,000 epochs on a tiny ($\approx$ 600 images) dataset. We believe that the findings in this paper are directly applicable and will lead to improvements in models that rely on CAEs.