 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIs forgetting less a good inductive bias for forward transfer?
Mar 14, 2023



One of the main motivations of studying continual learning is that the problem setting allows a model to accrue knowledge from past tasks to learn new tasks more efficiently. However, recent studies suggest that the key metric that continual learning algorithms optimize, reduction in catastrophic forgetting, does not correlate well with the forward transfer of knowledge. We believe that the conclusion previous works reached is due to the way they measure forward transfer. We argue that the measure of forward transfer to a task should not be affected by the restrictions placed on the continual learner in order to preserve knowledge of previous tasks. Instead, forward transfer should be measured by how easy it is to learn a new task given a set of representations produced by continual learning on previous tasks. Under this notion of forward transfer, we evaluate different continual learning algorithms on a variety of image classification benchmarks. Our results indicate that less forgetful representations lead to a better forward transfer suggesting a strong correlation between retaining past information and learning efficiency on new tasks. Further, we found less forgetful representations to be more diverse and discriminative compared to their forgetful counterparts.
* Published as a conference paper at ICLR 2023
Architecture Matters in Continual Learning
Feb 01, 2022

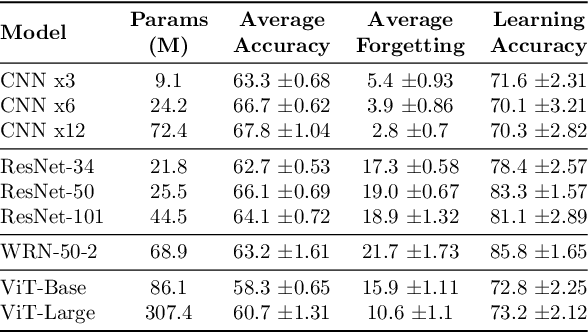

A large body of research in continual learning is devoted to overcoming the catastrophic forgetting of neural networks by designing new algorithms that are robust to the distribution shifts. However, the majority of these works are strictly focused on the "algorithmic" part of continual learning for a "fixed neural network architecture", and the implications of using different architectures are mostly neglected. Even the few existing continual learning methods that modify the model assume a fixed architecture and aim to develop an algorithm that efficiently uses the model throughout the learning experience. However, in this work, we show that the choice of architecture can significantly impact the continual learning performance, and different architectures lead to different trade-offs between the ability to remember previous tasks and learning new ones. Moreover, we study the impact of various architectural decisions, and our findings entail best practices and recommendations that can improve the continual learning performance.
Dataset Distillation with Infinitely Wide Convolutional Networks
Jul 27, 2021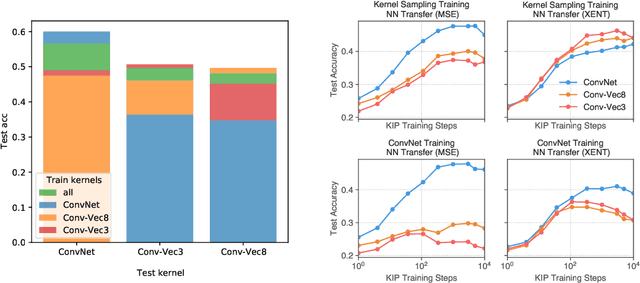
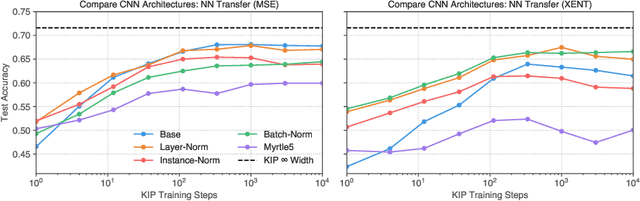
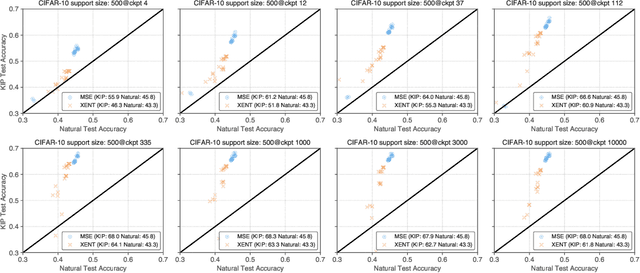
The effectiveness of machine learning algorithms arises from being able to extract useful features from large amounts of data. As model and dataset sizes increase, dataset distillation methods that compress large datasets into significantly smaller yet highly performant ones will become valuable in terms of training efficiency and useful feature extraction. To that end, we apply a novel distributed kernel based meta-learning framework to achieve state-of-the-art results for dataset distillation using infinitely wide convolutional neural networks. For instance, using only 10 datapoints (0.02% of original dataset), we obtain over 64% test accuracy on CIFAR-10 image classification task, a dramatic improvement over the previous best test accuracy of 40%. Our state-of-the-art results extend across many other settings for MNIST, Fashion-MNIST, CIFAR-10, CIFAR-100, and SVHN. Furthermore, we perform some preliminary analyses of our distilled datasets to shed light on how they differ from naturally occurring data.
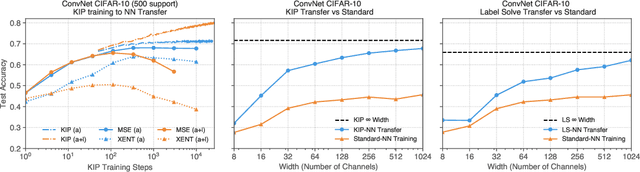
Dataset Meta-Learning from Kernel Ridge-Regression
Oct 30, 2020
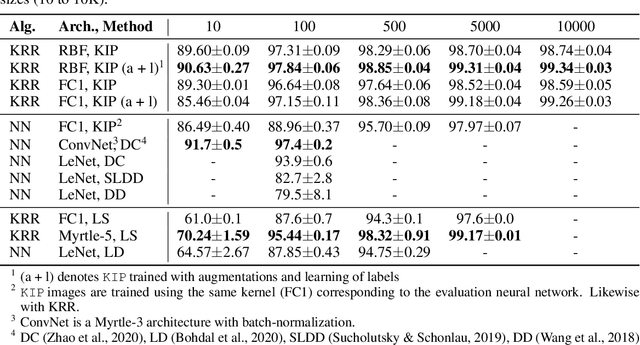

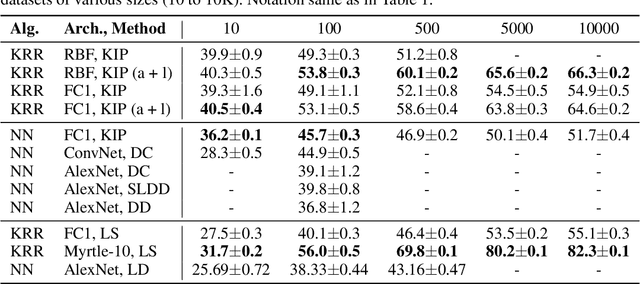
One of the most fundamental aspects of any machine learning algorithm is the training data used by the algorithm. We introduce the novel concept of $\epsilon$-approximation of datasets, obtaining datasets which are much smaller than or are significant corruptions of the original training data while maintaining similar model performance. We introduce a meta-learning algorithm called Kernel Inducing Points (KIP) for obtaining such remarkable datasets, inspired by the recent developments in the correspondence between infinitely-wide neural networks and kernel ridge-regression (KRR). For KRR tasks, we demonstrate that KIP can compress datasets by one or two orders of magnitude, significantly improving previous dataset distillation and subset selection methods while obtaining state of the art results for MNIST and CIFAR-10 classification. Furthermore, our KIP-learned datasets are transferable to the training of finite-width neural networks even beyond the lazy-training regime, which leads to state of the art results for neural network dataset distillation with potential applications to privacy-preservation.