 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHadamax Encoding: Elevating Performance in Model-Free Atari
May 21, 2025Neural network architectures have a large impact in machine learning. In reinforcement learning, network architectures have remained notably simple, as changes often lead to small gains in performance. This work introduces a novel encoder architecture for pixel-based model-free reinforcement learning. The Hadamax (\textbf{Hada}mard \textbf{max}-pooling) encoder achieves state-of-the-art performance by max-pooling Hadamard products between GELU-activated parallel hidden layers. Based on the recent PQN algorithm, the Hadamax encoder achieves state-of-the-art model-free performance in the Atari-57 benchmark. Specifically, without applying any algorithmic hyperparameter modifications, Hadamax-PQN achieves an 80\% performance gain over vanilla PQN and significantly surpasses Rainbow-DQN. For reproducibility, the full code is available on \href{https://github.com/Jacobkooi/Hadamax}{GitHub}.
Latent Assistance Networks: Rediscovering Hyperbolic Tangents in RL
Jun 13, 2024Activation functions are one of the key components of a neural network. The most commonly used activation functions can be classed into the category of continuously differentiable (e.g. tanh) and linear-unit functions (e.g. ReLU), both having their own strengths and drawbacks with respect to downstream performance and representation capacity through learning (e.g. measured by the number of dead neurons and the effective rank). In reinforcement learning, the performance of continuously differentiable activations often falls short as compared to linear-unit functions. From the perspective of the activations in the last hidden layer, this paper provides insights regarding this sub-optimality and explores how activation functions influence the occurrence of dead neurons and the magnitude of the effective rank. Additionally, a novel neural architecture is proposed that leverages the product of independent activation values. In the Atari domain, we show faster learning, a reduction in dead neurons and increased effective rank.
Disentangled (Un)Controllable Features
Oct 31, 2022



In the context of MDPs with high-dimensional states, reinforcement learning can achieve better results when using a compressed, low-dimensional representation of the original input space. A variety of learning objectives have therefore been used to learn useful representations. However, these representations usually lack interpretability of the different features. We propose a representation learning algorithm that is able to disentangle latent features into a controllable and an uncontrollable part. The resulting representations are easily interpretable and can be used for learning and planning efficiently by leveraging the specific properties of the two parts. To highlight the benefits of the approach, the disentangling properties of the algorithm are illustrated in three different environments.
Inclined Quadrotor Landing using Deep Reinforcement Learning
Mar 16, 2021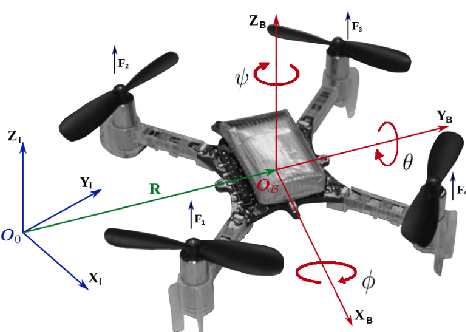
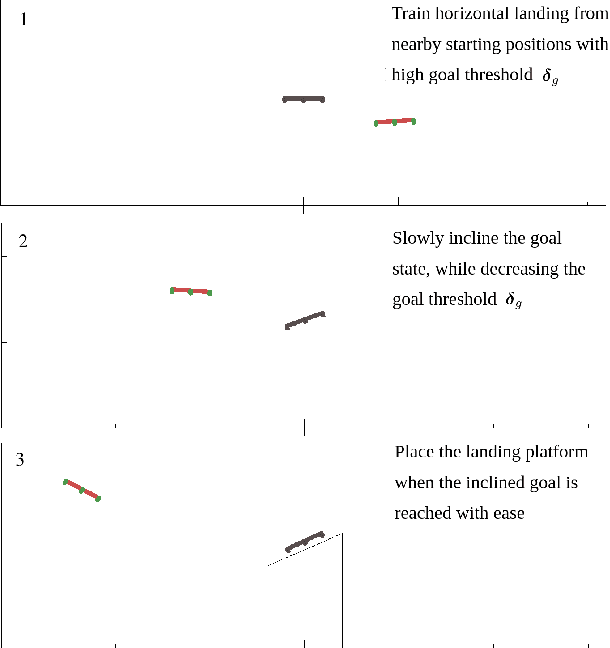
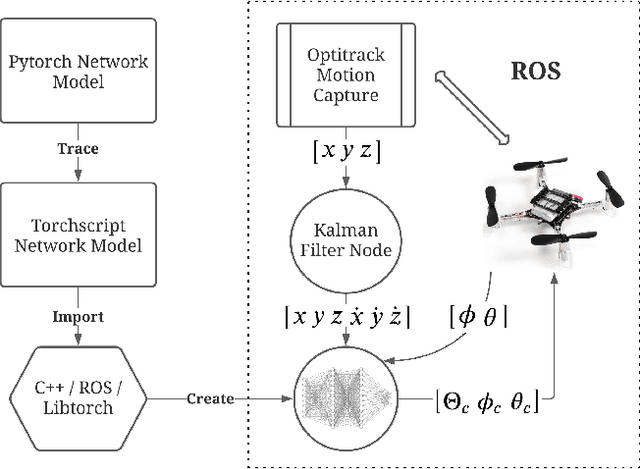

Landing a quadrotor on an inclined surface is a challenging manoeuvre. The final state of any inclined landing trajectory is not an equilibrium, which precludes the use of most conventional control methods. We propose a deep reinforcement learning approach to design an autonomous landing controller for inclined surfaces. Using the proximal policy optimization (PPO) algorithm with sparse rewards and a tailored curriculum learning approach, a robust policy can be trained in simulation in less than 90 minutes on a standard laptop. The policy then directly runs on a real Crazyflie 2.1 quadrotor and successfully performs real inclined landings in a flying arena. A single policy evaluation takes approximately 2.5 ms, which makes it suitable for a future embedded implementation on the quadrotor.