 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultivariate Time Series Early Classification Across Channel and Time Dimensions
Jun 26, 2023Nowadays, the deployment of deep learning models on edge devices for addressing real-world classification problems is becoming more prevalent. Moreover, there is a growing popularity in the approach of early classification, a technique that involves classifying the input data after observing only an early portion of it, aiming to achieve reduced communication and computation requirements, which are crucial parameters in edge intelligence environments. While early classification in the field of time series analysis has been broadly researched, existing solutions for multivariate time series problems primarily focus on early classification along the temporal dimension, treating the multiple input channels in a collective manner. In this study, we propose a more flexible early classification pipeline that offers a more granular consideration of input channels and extends the early classification paradigm to the channel dimension. To implement this method, we utilize reinforcement learning techniques and introduce constraints to ensure the feasibility and practicality of our objective. To validate its effectiveness, we conduct experiments using synthetic data and we also evaluate its performance on real datasets. The comprehensive results from our experiments demonstrate that, for multiple datasets, our method can enhance the early classification paradigm by achieving improved accuracy for equal input utilization.
An Empirical Evaluation of Multivariate Time Series Classification with Input Transformation across Different Dimensions
Oct 14, 2022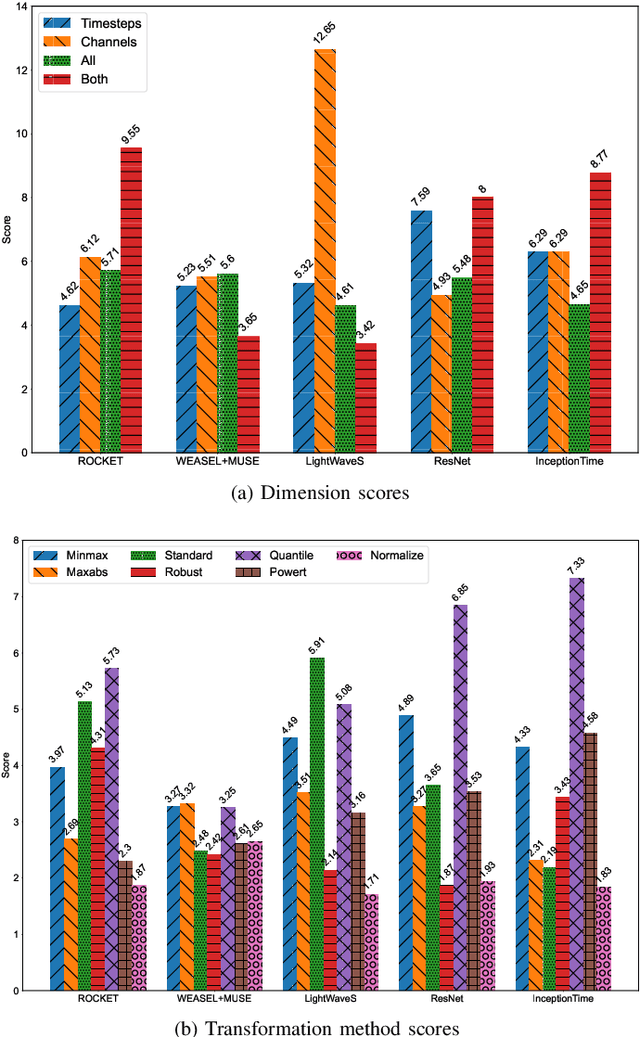

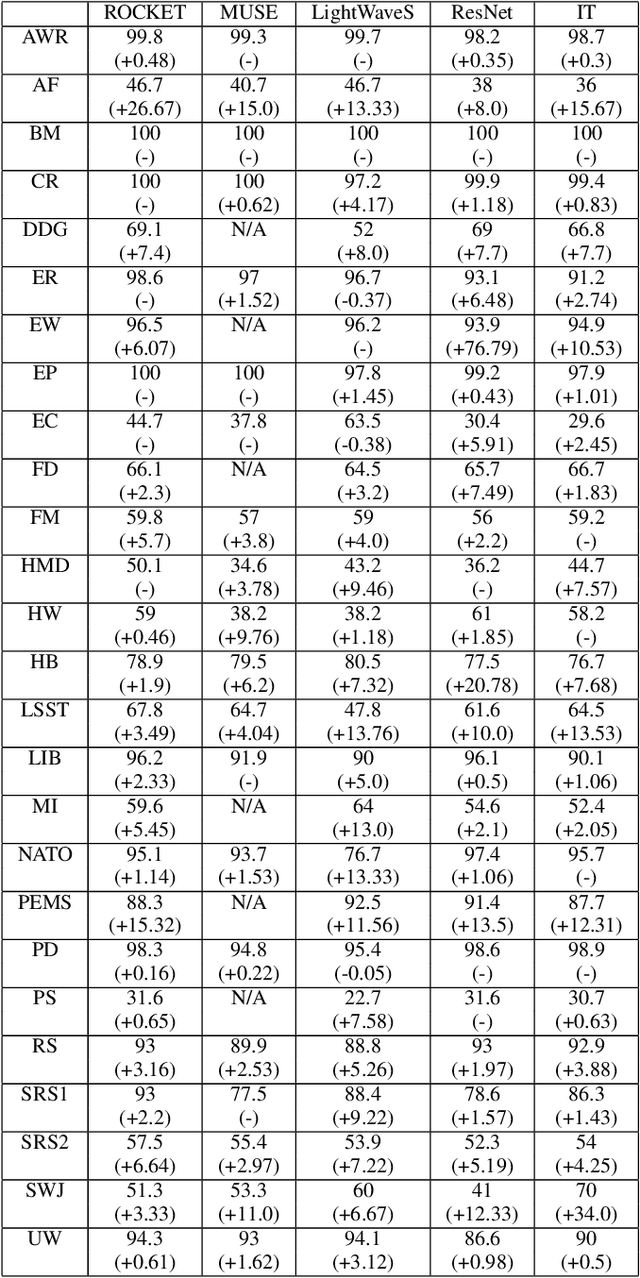
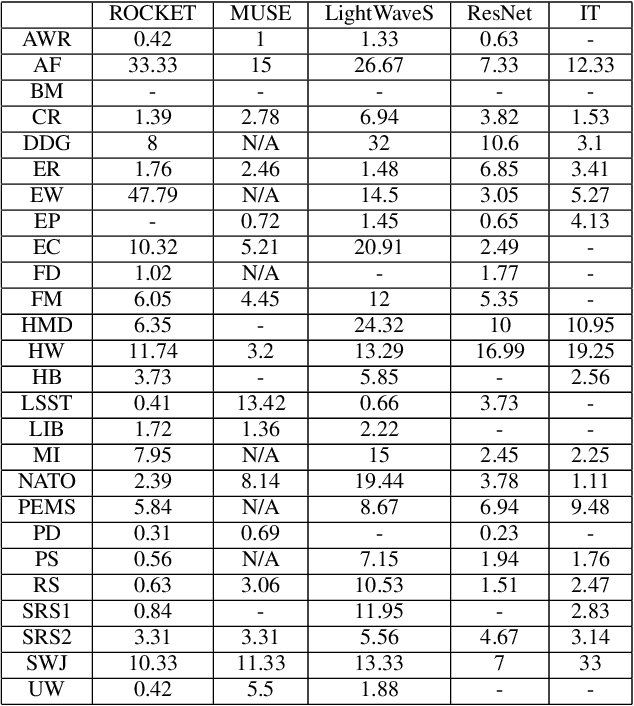
In current research, machine and deep learning solutions for the classification of temporal data are shifting from single-channel datasets (univariate) to problems with multiple channels of information (multivariate). The majority of these works are focused on the method novelty and architecture, and the format of the input data is often treated implicitly. Particularly, multivariate datasets are often treated as a stack of univariate time series in terms of input preprocessing, with scaling methods applied across each channel separately. In this evaluation, we aim to demonstrate that the additional channel dimension is far from trivial and different approaches to scaling can lead to significantly different results in the accuracy of a solution. To that end, we test seven different data transformation methods on four different temporal dimensions and study their effect on the classification accuracy of five recent methods. We show that, for the large majority of tested datasets, the best transformation-dimension configuration leads to an increase in the accuracy compared to the result of each model with the same hyperparameters and no scaling, ranging from 0.16 to 76.79 percentage points. We also show that if we keep the transformation method constant, there is a statistically significant difference in accuracy results when applying it across different dimensions, with accuracy differences ranging from 0.23 to 47.79 percentage points. Finally, we explore the relation of the transformation methods and dimensions to the classifiers, and we conclude that there is no prominent general trend, and the optimal configuration is dataset- and classifier-specific.
Taking ROCKET on an Efficiency Mission: Multivariate Time Series Classification with LightWaveS
Apr 11, 2022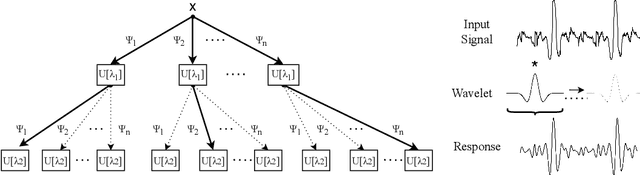
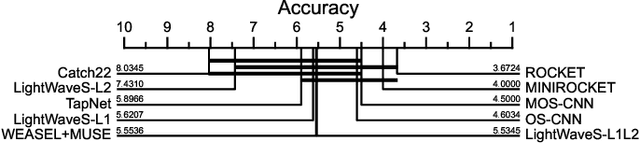
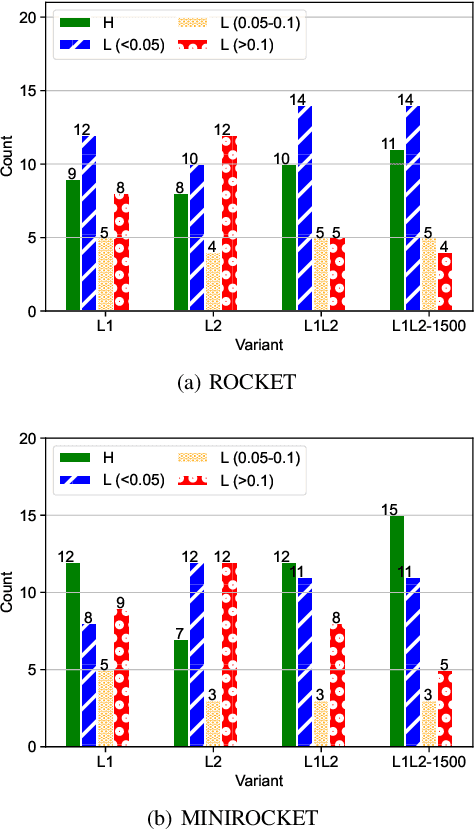
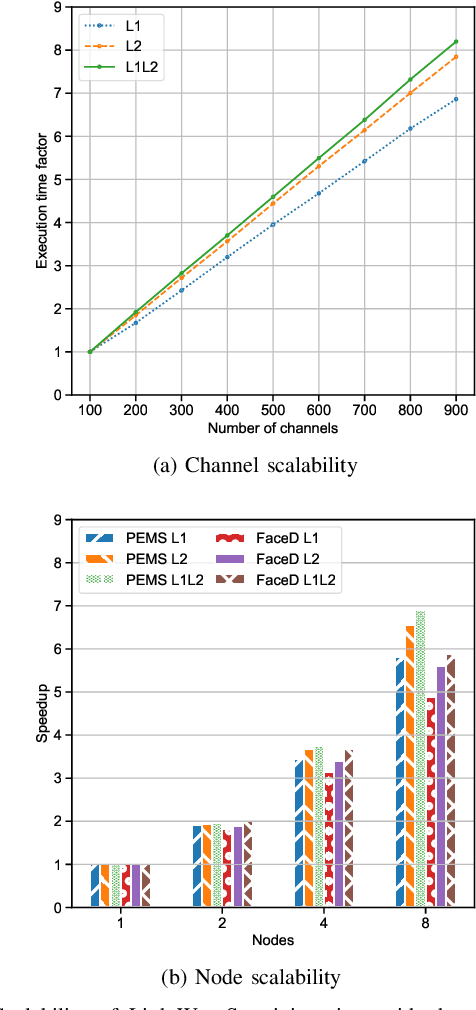
Nowadays, with the rising number of sensors in sectors such as healthcare and industry, the problem of multivariate time series classification (MTSC) is getting increasingly relevant and is a prime target for machine and deep learning approaches. Their expanding adoption in real-world environments is causing a shift in focus from the pursuit of ever-higher prediction accuracy with complex models towards practical, deployable solutions that balance accuracy and parameters such as prediction speed. An MTSC model that has attracted attention recently is ROCKET, based on random convolutional kernels, both because of its very fast training process and its state-of-the-art accuracy. However, the large number of features it utilizes may be detrimental to inference time. Examining its theoretical background and limitations enables us to address potential drawbacks and present LightWaveS: a framework for accurate MTSC, which is fast both during training and inference. Specifically, utilizing wavelet scattering transformation and distributed feature selection, we manage to create a solution that employs just 2.5% of the ROCKET features, while achieving accuracy comparable to recent MTSC models. LightWaveS also scales well across multiple compute nodes and with the number of input channels during training. In addition, it can significantly reduce the input size and provide insight to an MTSC problem by keeping only the most useful channels. We present three versions of our algorithm and their results on distributed training time and scalability, accuracy, and inference speedup. We show that we achieve speedup ranging from 9x to 53x compared to ROCKET during inference on an edge device, on datasets with comparable accuracy.