 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Empirical Evaluation of Multivariate Time Series Classification with Input Transformation across Different Dimensions
Paper and Code
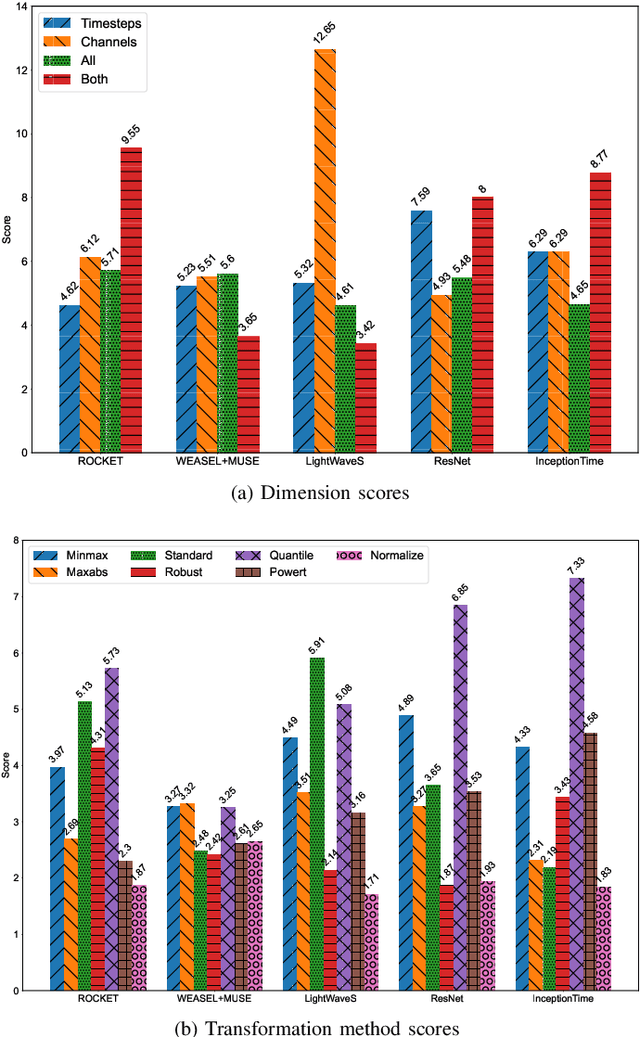

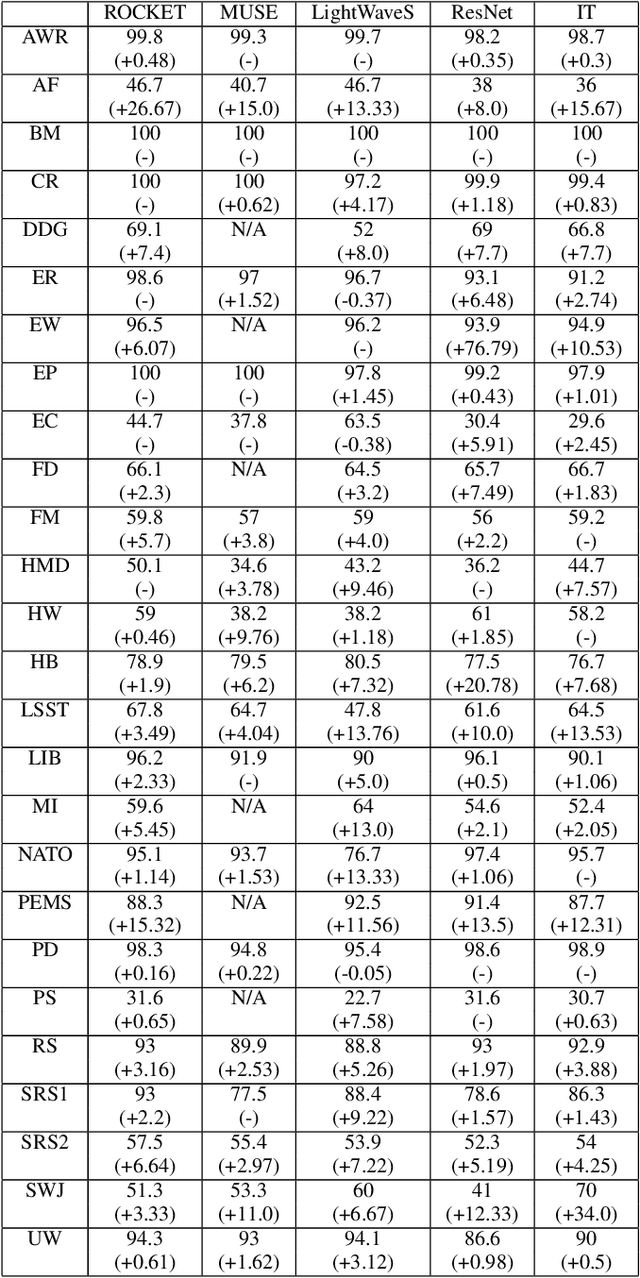
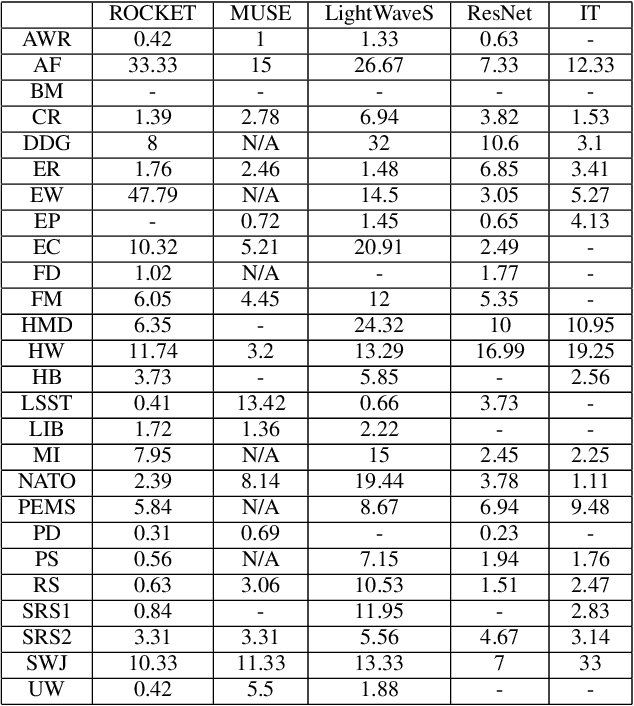
In current research, machine and deep learning solutions for the classification of temporal data are shifting from single-channel datasets (univariate) to problems with multiple channels of information (multivariate). The majority of these works are focused on the method novelty and architecture, and the format of the input data is often treated implicitly. Particularly, multivariate datasets are often treated as a stack of univariate time series in terms of input preprocessing, with scaling methods applied across each channel separately. In this evaluation, we aim to demonstrate that the additional channel dimension is far from trivial and different approaches to scaling can lead to significantly different results in the accuracy of a solution. To that end, we test seven different data transformation methods on four different temporal dimensions and study their effect on the classification accuracy of five recent methods. We show that, for the large majority of tested datasets, the best transformation-dimension configuration leads to an increase in the accuracy compared to the result of each model with the same hyperparameters and no scaling, ranging from 0.16 to 76.79 percentage points. We also show that if we keep the transformation method constant, there is a statistically significant difference in accuracy results when applying it across different dimensions, with accuracy differences ranging from 0.23 to 47.79 percentage points. Finally, we explore the relation of the transformation methods and dimensions to the classifiers, and we conclude that there is no prominent general trend, and the optimal configuration is dataset- and classifier-specific.