 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Robustness of the Minimum Error Entropy Criterion: A Transfer Learning Case Study
Jul 25, 2023Coping with distributional shifts is an important part of transfer learning methods in order to perform well in real-life tasks. However, most of the existing approaches in this area either focus on an ideal scenario in which the data does not contain noises or employ a complicated training paradigm or model design to deal with distributional shifts. In this paper, we revisit the robustness of the minimum error entropy (MEE) criterion, a widely used objective in statistical signal processing to deal with non-Gaussian noises, and investigate its feasibility and usefulness in real-life transfer learning regression tasks, where distributional shifts are common. Specifically, we put forward a new theoretical result showing the robustness of MEE against covariate shift. We also show that by simply replacing the mean squared error (MSE) loss with the MEE on basic transfer learning algorithms such as fine-tuning and linear probing, we can achieve competitive performance with respect to state-of-the-art transfer learning algorithms. We justify our arguments on both synthetic data and 5 real-world time-series data.
Transfer-Learning Across Datasets with Different Input Dimensions: An Algorithm and Analysis for the Linear Regression Case
Feb 10, 2022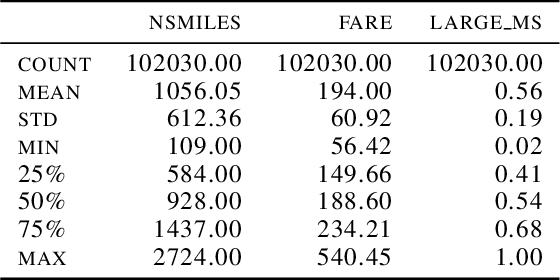
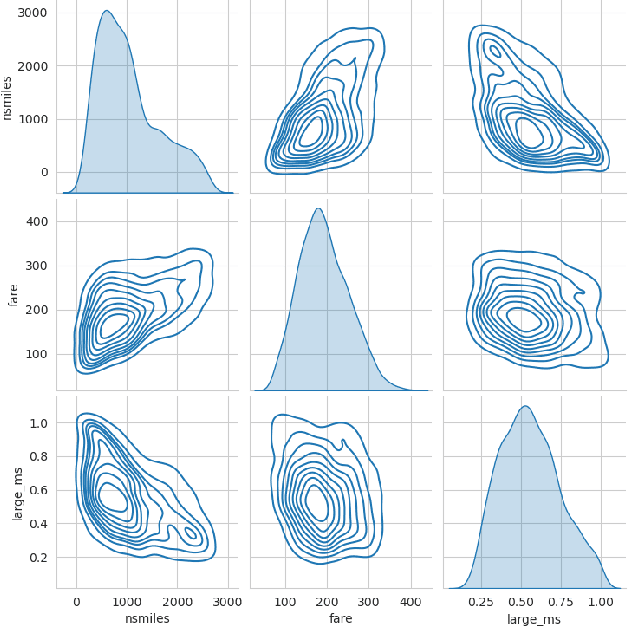
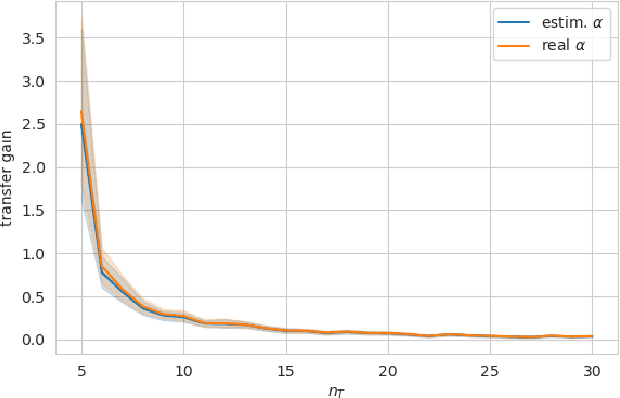

With the development of new sensors and monitoring devices, more sources of data become available to be used as inputs for machine learning models. These can on the one hand help to improve the accuracy of a model. On the other hand however, combining these new inputs with historical data remains a challenge that has not yet been studied in enough detail. In this work, we propose a transfer-learning algorithm that combines the new and the historical data, that is especially beneficial when the new data is scarce. We focus the approach on the linear regression case, which allows us to conduct a rigorous theoretical study on the benefits of the approach. We show that our approach is robust against negative transfer-learning, and we confirm this result empirically with real and simulated data.