 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer-Learning Across Datasets with Different Input Dimensions: An Algorithm and Analysis for the Linear Regression Case
Feb 10, 2022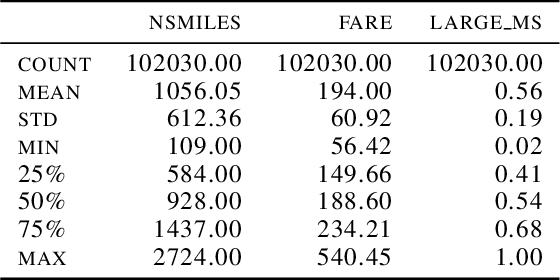
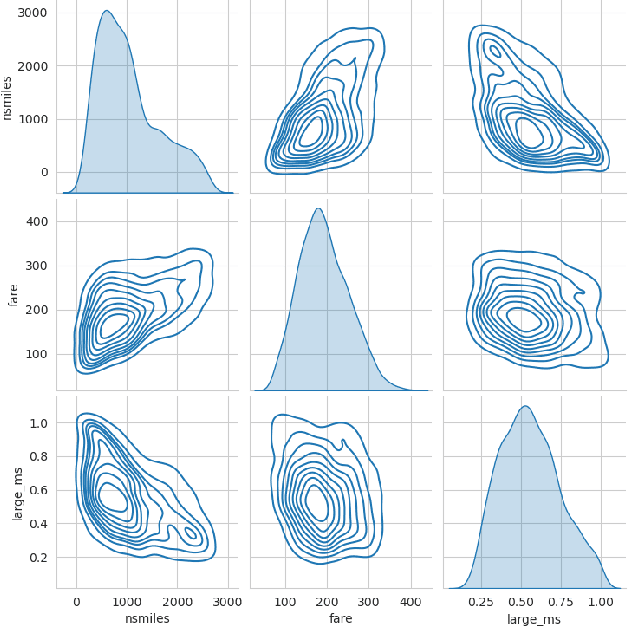
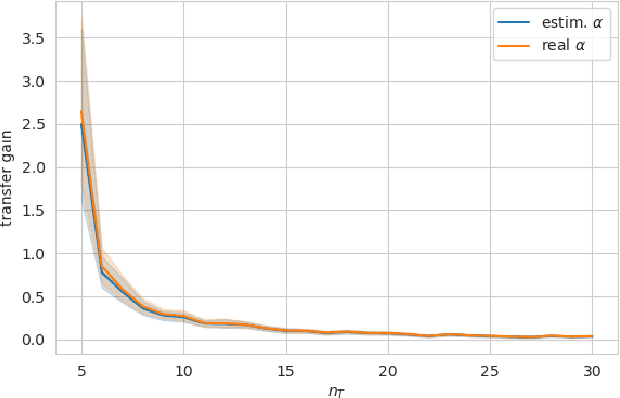

With the development of new sensors and monitoring devices, more sources of data become available to be used as inputs for machine learning models. These can on the one hand help to improve the accuracy of a model. On the other hand however, combining these new inputs with historical data remains a challenge that has not yet been studied in enough detail. In this work, we propose a transfer-learning algorithm that combines the new and the historical data, that is especially beneficial when the new data is scarce. We focus the approach on the linear regression case, which allows us to conduct a rigorous theoretical study on the benefits of the approach. We show that our approach is robust against negative transfer-learning, and we confirm this result empirically with real and simulated data.
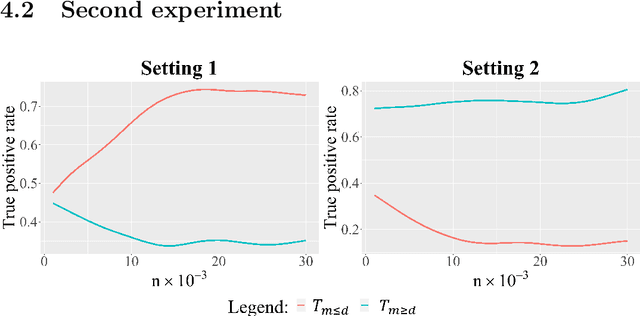
Optimal high-dimensional and nonparametric distributed testing under communication constraints
Feb 02, 2022We derive minimax testing errors in a distributed framework where the data is split over multiple machines and their communication to a central machine is limited to $b$ bits. We investigate both the $d$- and infinite-dimensional signal detection problem under Gaussian white noise. We also derive distributed testing algorithms reaching the theoretical lower bounds. Our results show that distributed testing is subject to fundamentally different phenomena that are not observed in distributed estimation. Among our findings, we show that testing protocols that have access to shared randomness can perform strictly better in some regimes than those that do not. Furthermore, we show that consistent nonparametric distributed testing is always possible, even with as little as $1$-bit of communication and the corresponding test outperforms the best local test using only the information available at a single local machine.
Optimal distributed testing in high-dimensional Gaussian models
Dec 09, 2020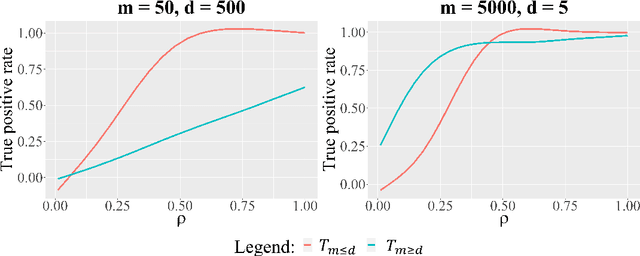
In this paper study the problem of signal detection in Gaussian noise in a distributed setting. We derive a lower bound on the size that the signal needs to have in order to be detectable. Moreover, we exhibit optimal distributed testing strategies that attain the lower bound.
Distributed function estimation: adaptation using minimal communication
Mar 28, 2020We investigate whether in a distributed setting, adaptive estimation of a smooth function at the optimal rate is possible under minimal communication. It turns out that the answer depends on the risk considered and on the number of servers over which the procedure is distributed. We show that for the $L_\infty$-risk, adaptively obtaining optimal rates under minimal communication is not possible. For the $L_2$-risk, it is possible over a range of regularities that depends on the relation between the number of local servers and the total sample size.
Nonparametric Bayesian label prediction on a large graph using truncated Laplacian regularization
Apr 13, 2018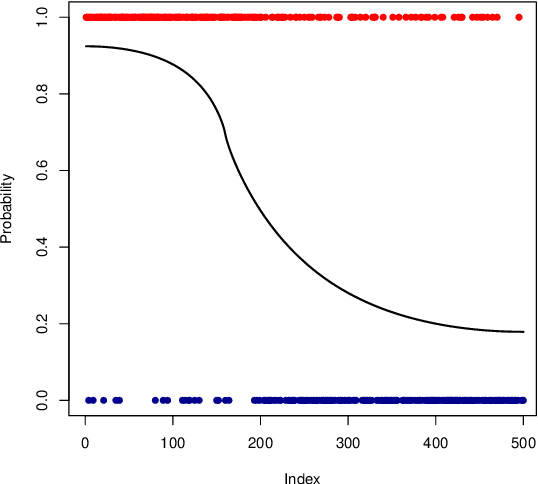
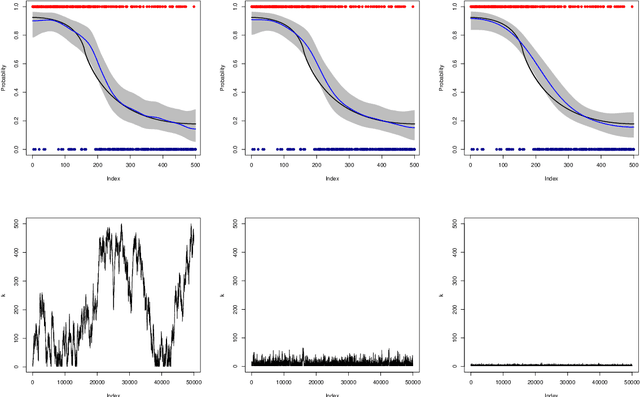

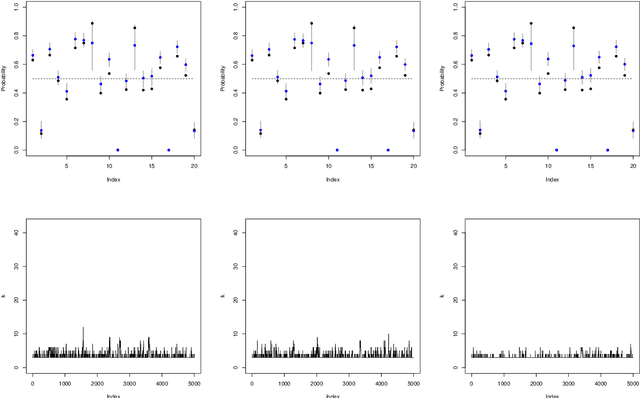
This article describes an implementation of a nonparametric Bayesian approach to solving binary classification problems on graphs. We consider a hierarchical Bayesian approach with a prior that is constructed by truncating a series expansion of the soft label function using the graph Laplacian eigenfunctions as basis functions. We compare our truncated prior to the untruncated Laplacian based prior in simulated and real data examples to illustrate the improved scalability in terms of size of the underlying graph.
Adaptive distributed methods under communication constraints
Apr 03, 2018We study distributed estimation methods under communication constraints in a distributed version of the nonparametric signal-in-white-noise model. We derive minimax lower bounds and exhibit methods that attain those bounds. Moreover, we show that adaptive estimation is possible in this setting.
An asymptotic analysis of distributed nonparametric methods
Nov 08, 2017

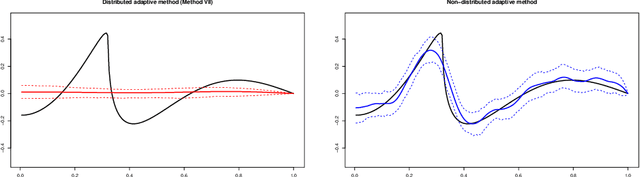
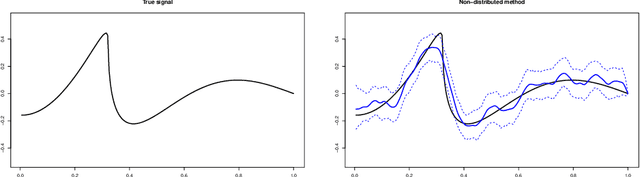
We investigate and compare the fundamental performance of several distributed learning methods that have been proposed recently. We do this in the context of a distributed version of the classical signal-in-Gaussian-white-noise model, which serves as a benchmark model for studying performance in this setting. The results show how the design and tuning of a distributed method can have great impact on convergence rates and validity of uncertainty quantification. Moreover, we highlight the difficulty of designing nonparametric distributed procedures that automatically adapt to smoothness.
Nonparametric Bayesian label prediction on a graph
Jun 15, 2017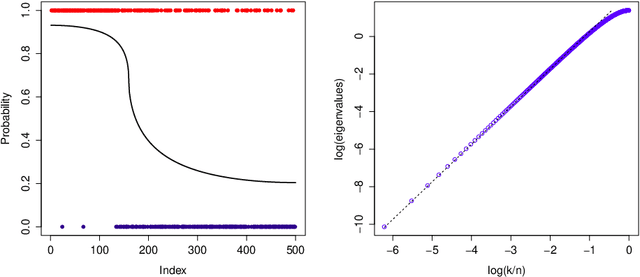
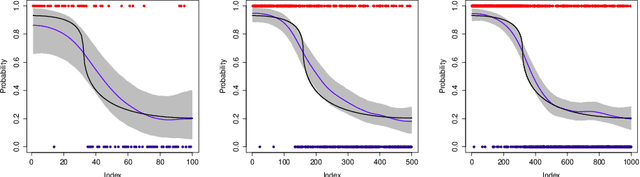
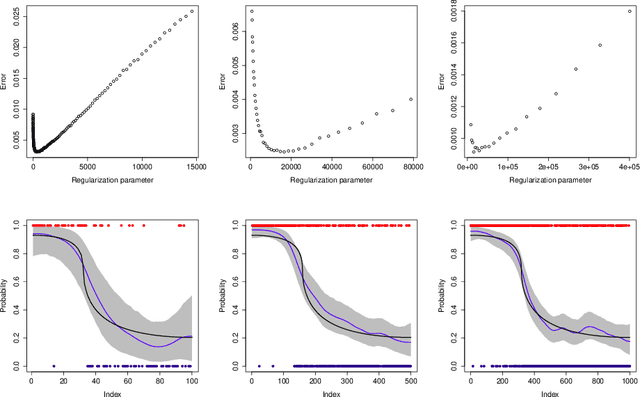

An implementation of a nonparametric Bayesian approach to solving binary classification problems on graphs is described. A hierarchical Bayesian approach with a randomly scaled Gaussian prior is considered. The prior uses the graph Laplacian to take into account the underlying geometry of the graph. A method based on a theoretically optimal prior and a more flexible variant using partial conjugacy are proposed. Two simulated data examples and two examples using real data are used in order to illustrate the proposed methods.
Optimality of Poisson processes intensity learning with Gaussian processes
Mar 02, 2015In this paper we provide theoretical support for the so-called "Sigmoidal Gaussian Cox Process" approach to learning the intensity of an inhomogeneous Poisson process on a $d$-dimensional domain. This method was proposed by Adams, Murray and MacKay (ICML, 2009), who developed a tractable computational approach and showed in simulation and real data experiments that it can work quite satisfactorily. The results presented in the present paper provide theoretical underpinning of the method. In particular, we show how to tune the priors on the hyper parameters of the model in order for the procedure to automatically adapt to the degree of smoothness of the unknown intensity and to achieve optimal convergence rates.