Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn asymptotic analysis of distributed nonparametric methods
Paper and Code
Nov 08, 2017

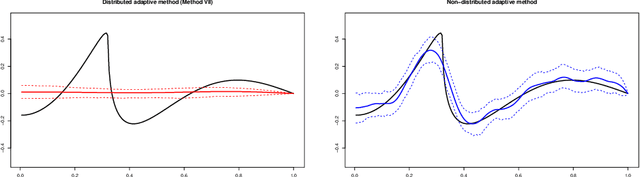
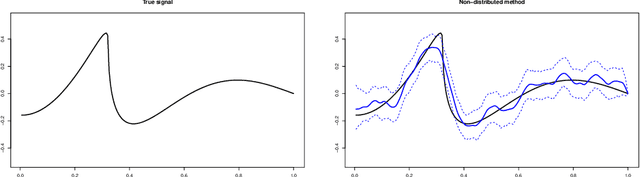
We investigate and compare the fundamental performance of several distributed learning methods that have been proposed recently. We do this in the context of a distributed version of the classical signal-in-Gaussian-white-noise model, which serves as a benchmark model for studying performance in this setting. The results show how the design and tuning of a distributed method can have great impact on convergence rates and validity of uncertainty quantification. Moreover, we highlight the difficulty of designing nonparametric distributed procedures that automatically adapt to smoothness.
* 29 pages, 4 figures
View paper on